







大数据起源于-谷歌,于2003年起发布一系列论文(大数据三驾马车):
1. 《The Google File System 》
2. 《MapReduce: Simplified Data Processing on Large Clusters》在大型集群中简化数据处理
3.《Bigtable: A Distributed Storage System for Structured Data》结构化数据的分布式存储系统
1 、GFS
GFS 是一个大型的分布式文件系统。一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。
为 Google 大数据处理系统提供海量存储,并且与 MapReduce 和 BigTable 等技术结合得十分紧密,处于系统的底层。
GFS 的系统架构如图 所示,主要由一个 Master Server(主服务器)和多个 Chunk Server(数据块服务器)组成。
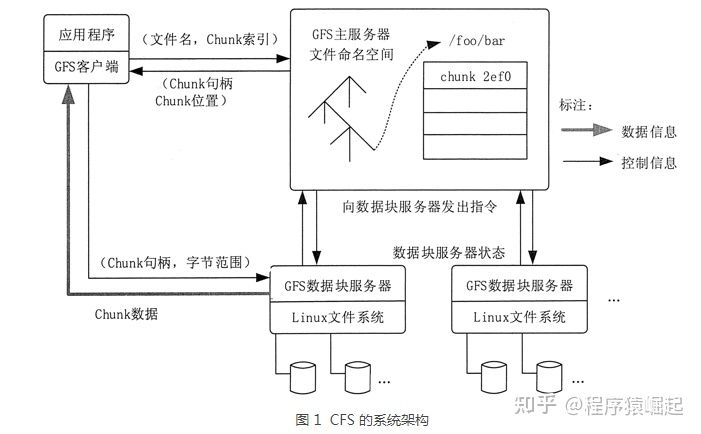
Master Server 主要负责维护系统中的名字空间,访问控制信息,从文件到块的映射及块的当前位置等元数据,并与 Chunk Server 通信。
Chunk Server 负责具体的存储工作。数据以文件的形式存储在 Chunk Server 上。Client 是应用程序访问 GFS 的接口。
Master Server 的所有信息都存储在内存里,启动时信息从 Chunk Server 中获取。这样不但提高了 Master Server 的性能和吞吐量,也有利于 Master Server 宕机后把后备服务器切换成 Master Server。
GFS 的系统架构设计有两大优势。
- Client 和 Master Server 之间只有控制流,没有数据流,因此降低了 Master Server 的负载。
- 由于 Client 与 Chunk Server 之间直接传输数据流,并且文件被分成多个 Chunk 进行分布式存储,因此 Client 可以同时并行访问多个 Chunk Server,从而让系统的 I/O 并行度提高。
Chunk Server 在硬盘上存储实际数据。Google 把每个 chunk 数据块的大小设计成 64MB,每个 chunk 被复制成 3 个副本放到不同的 Chunk Server 中,以创建冗余来避免服务器崩溃。如果某个 Chunk Server 发生故障,Master Server 便把数据备份到一个新的地方。
HDFS (Hadoop Distributed File System)最早是根据 GFS(Google File System)的论文概念模型来设计实现的。
HDFS 参照了它所以大部分架构设计概念是类似的,比如 HDFS NameNode 相当于 GFS Master,HDFS DataNode 相当于 GFS chunkserver。
2、MapReduce
GFS 解决了 Google 海量数据的存储问题,MapReduce 则是为了解决如何从这些海量数据中快速计算并获取期望结果的问题。
MapReduce 是由 Google 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
MapReduce 实现了 Map 和 Reduce 两个功能。Map 把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集,而 Reduce 是把两个或更多个 Map 通过多个线程、进程或者独立系统进行并行执行处理得到的结果集进行分类和归纳。
用户只需要提供自己的 Map 函数及 Reduce 函数就可以在集群上进行大规模的分布式数据处理。与传统的分布式程序设计相比,MapReduce 封装了并行处理、容错处理、本地化计算、负载均衡等细节,具有简单而强大的接口。正是由于 MapReduce 具有函数式编程语言和矢量编程语言的共性,使得这种编程模式特别适合于非结构化和结构化的海量数据的搜索、挖掘、分析等应用。
Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。hive是用于OLAP,提供类sql语言的分析与计算的框架,底层就是MR。
3、BigTable
BigTable 是 Google 设计的分布式数据存储系统,是用来处理海量数据的一种非关系型数据库。BigTable 是一个稀疏的、分布式的、持久化存储的多维度排序的映射表。
BigTable 的设计目的是能够可靠地处理 PB 级别的数据,并且能够部署到上千台机器上。
BigTable 开发团队确定了 BigTable 设计所需达到的几个基本目标。
- 广泛的适用性(要满足一系列 Google 产品而并非特定产品的存储要求。)
- 很强的可扩展性(根据需要随时可以加入或撤销服务器。)
- 高可用性(确保几乎所有的情况下系统都可用。对于客户来说,有时候即使短暂的服务中断也是不能忍受的。)
- 简单性(底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来了便利。)
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
补充:
数据库 Database (Oracle, Mysql, PostgreSQL)主要用于事务处理,数据仓库 Datawarehouse (Amazon Redshift, Hive)主要用于数据分析。
用途上的不同决定了这两种架构的特点不同。
数据库(Database)的特点是:
- 相对复杂的表格结构,存储结构相对紧致,少冗余数据。
- 读和写都有优化。
- 相对简单的read/write query,单次作用于相对的少量数据。
数据仓库(Datawarehouse)的特点是:
- 相对简单的(Denormalized)表格结构,存储结构相对松散,多冗余数据。
- 一般只是读优化。
- 相对复杂的read query,单次作用于相对大量的数据(历史数据)。
参考:
HDFS,MapReduce,Hive,Hbase 等之间的关系 - ck_2016 - 博客园
链接: 大数据三驾马车pdf下载 提取码: 7rpv

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









