







Google引爆大数据时代的三篇论文
谈到Hadoop的起源,就不得不提Google的三驾马车:Google FS、MapReduce、BigTable。虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文,奠定了风靡全球的大数据算法的基础!
一,GFS—-2003
2003年,Google发布Google File System论文,这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。

GFS由一个master和大量的chunkserver构成。Google设置一个master来保存目录和索引信息,这是为了简化系统结果,提高性能来考虑的,但是这就会造成主成为单点故障或者瓶颈。为了消除主的单点故障Google把每个chunk设置的很大(64M),这样,由于代码访问数据的本地性,application端和master的交互会减少,而主要数据流量都是Application和chunkserver之间的访问。
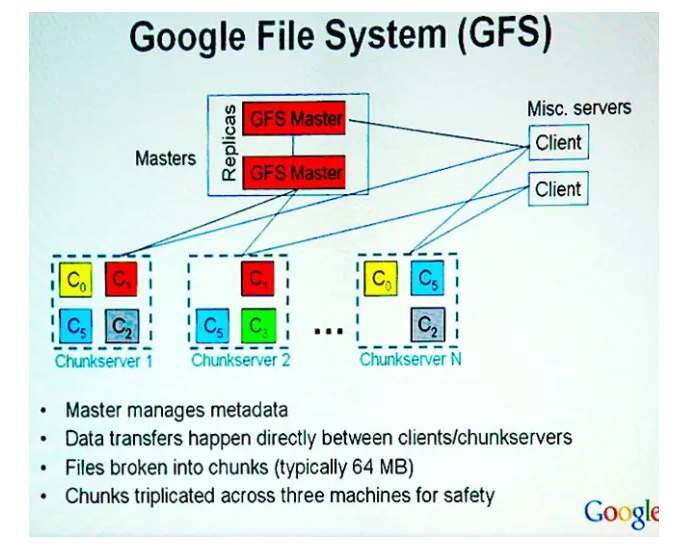
另外,master所有信息都存储在内存里,启动时信息从chunkserver中获取。提高了master的性能和吞吐量,也有利于master当掉后,很容易把后备j机器切换成master。客户端和chunkserver都不对文件数据单独做缓存,只是用linux文件系统自己的缓存。
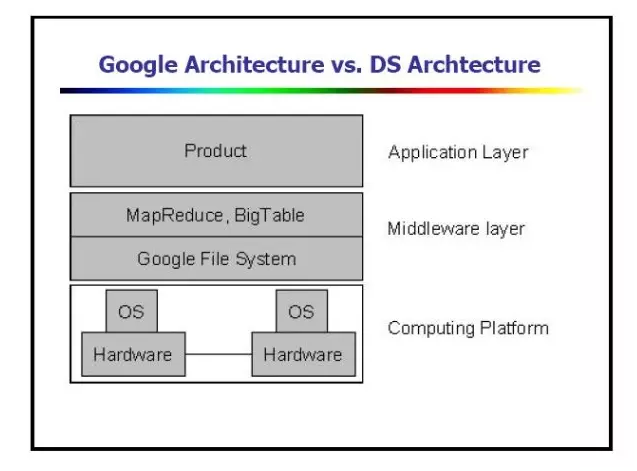
从上图可以看出,Google的后面两篇论文——MapReduce 和 BigTable都是以GFS为基础。三大基础核心技术构建出了完整的分布式运算架构。
二,MapReduce—-2004
紧随其后的就是2004年公布的 MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
传说中,Google使用它计算他们的搜索索引。而Mikio L. Braun认为其工作模式应该是:Google把所有抓取的页面都放置于他们的集群上,然后每天使用MapReduce来重算。

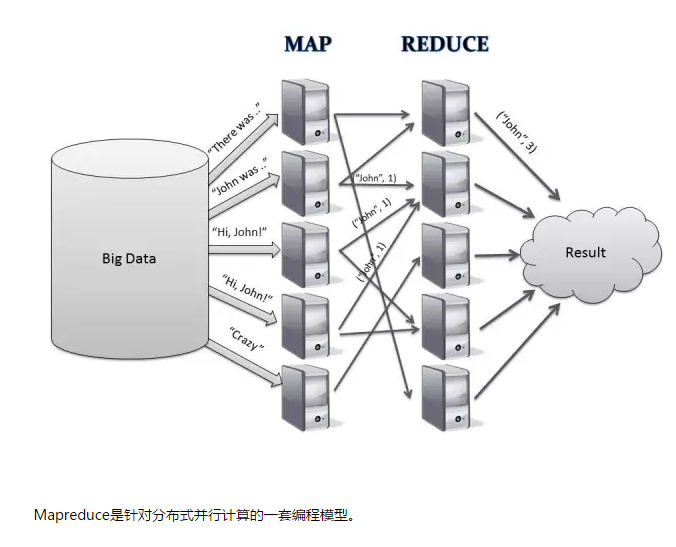
Mapreduce是针对分布式并行计算的一套编程模型。
讲到并行计算,就不能不谈到微软的Herb Sutter在2005年发表的文章” The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software”,主要意思是通过提高cpu主频的方式来提高程序的性能很快就要过去了,cpu的设计方向也主要是多核、超线程等并发上。但是以前的程序并不能自动的得到多核的好处,只有编写并发程序,才能真正获得多核的好处。分布式计算也是一样。
Mapreduce由Map和reduce组成,来自于Lisp,Map是影射,把指令分发到多个worker上去,reduce是规约,把Map的worker计算出来的结果合并。Mapreduce使用GFS存储数据。
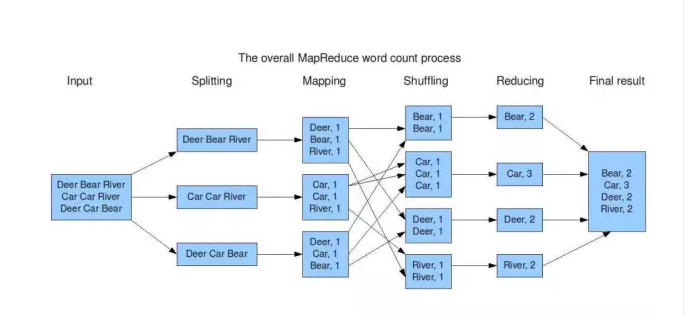
3
BigTable—-2006
Bigtable发布于2006年,启发了无数的NoSQL数据库,比如:Cassandra、HBase等等。Cassandra架构中有一半是模仿Bigtable,包括了数据模型、SSTables以及提前写日志(另一半是模仿Amazon的Dynamo数据库,使用点对点集群模式)。

BigTable 是建立在 GFS 和 MapReduce 之上的。每个Table都是一个多维的稀疏图
为了管理巨大的Table,把Table根据行分割,这些分割后的数据统称为:Tablets。每个Tablets大概有 100-200 MB,每个机器存储100个左右的 Tablets。底层的架构是:GFS。
由于GFS是一种分布式的文件系统,采用Tablets的机制后,可以获得很好的负载均衡。比如:可以把经常响应的表移动到其他空闲机器上,然后快速重建。
论文中英文版下载http://pan.baidu.com/s/1slUy4sl















 4831
4831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









