







一、写在前面
这篇文章主要介绍了OpenStack Mitaka Identity (keystone) 分页的实现,实现的方式比较简单暴力(扩展Keystone API),但目前已是作者想到的快速便捷实现的一种方式,如果各位有更优的现实方式请告知,相互进行技术交流,因为时间仓促以及个人理解有限,固有错误的地方请指出,谢谢! 如果转载,请保留作者信息。
邮箱地址:jpzhang.ht@gmail.com
个人博客:https://jianpengzhang.github.io/
CSDN博客:http://blog.csdn.net/u011521019
代码下载:https://jianpengzhang.github.io/2017/02/26/2017022606/#more
二、Keystone 分页历史
Identity (keystone) 分页早在2013年的时候就被提出,记忆中openstack开发峰会中还专门进行了讨论,时间过的太久记不起来,也懒得查找资料来说明历史,唯独找到https://blueprints.launchpad.net/keystone/+spec/pagination-backend-support,这个页面记录着在13年的时候扩展Identity (keystone),尽可能提高伸缩和性能被当作为一个Blueprints记录着,其中https://blueprints.launchpad.net/keystone/+spec/filtering-backend-support表示这个Blueprints在14年有一个里程碑的进展,但是从代码层面看,并没有真正实现底层代码的分页。
https://blueprints.launchpad.net/keystone/+spec/pagination说明:
分页的当前状态是未知的。本该在IceHouse summit会议 “kill pagination” 但是它从未兑现。分页依旧是残留的。
https://blueprints.launchpad.net/keystone/+spec/user-list-pagination 可以看到分页在2015年-09-11重新被提出,但是通过Blueprint information没有里程碑的进展,
目前分页的三个问题:
1、Marker+Limit(例如:实现“向前”分页)构建一个用户界面分页是不合适的。
2、分页扩展性不好
3、OpenStack提供的Api过滤功能并不是很好用。
Pagaination 反对的论点:
1.分页被滥用。例如,如果后端、配置不正确,可能需要很长的时间来满足用户通用的查询以及可能会返回大量的数据。
2.分页可能会伤害用户体验。请参阅
然而这不是分页根本性的障碍,从 API 的角度,分页是必要和有用的。
三、分页实现
项目列表代码分析
这里通过devstack部署的Mitaka版本来进行代码分析,默认部署完成之后keystone API 接口用的是V3, 但是简单看了下代码,horizon中对项目(tenants)连最基本的分页都没有,就决定不再基于V3接口代码下来讲解,通过对V2.0接口的代码来说明,因为V2.0接口中至少简单实现了tenants的部分分页代码,基于此来说明久更加方便易懂,读者也只需要掌握了基本的思路,想扩展其他功能列表的分页也比较轻易的事情。这里就允许自己偷个懒。
V3接口项目列表(已在设置中设置每页显示2条记录):
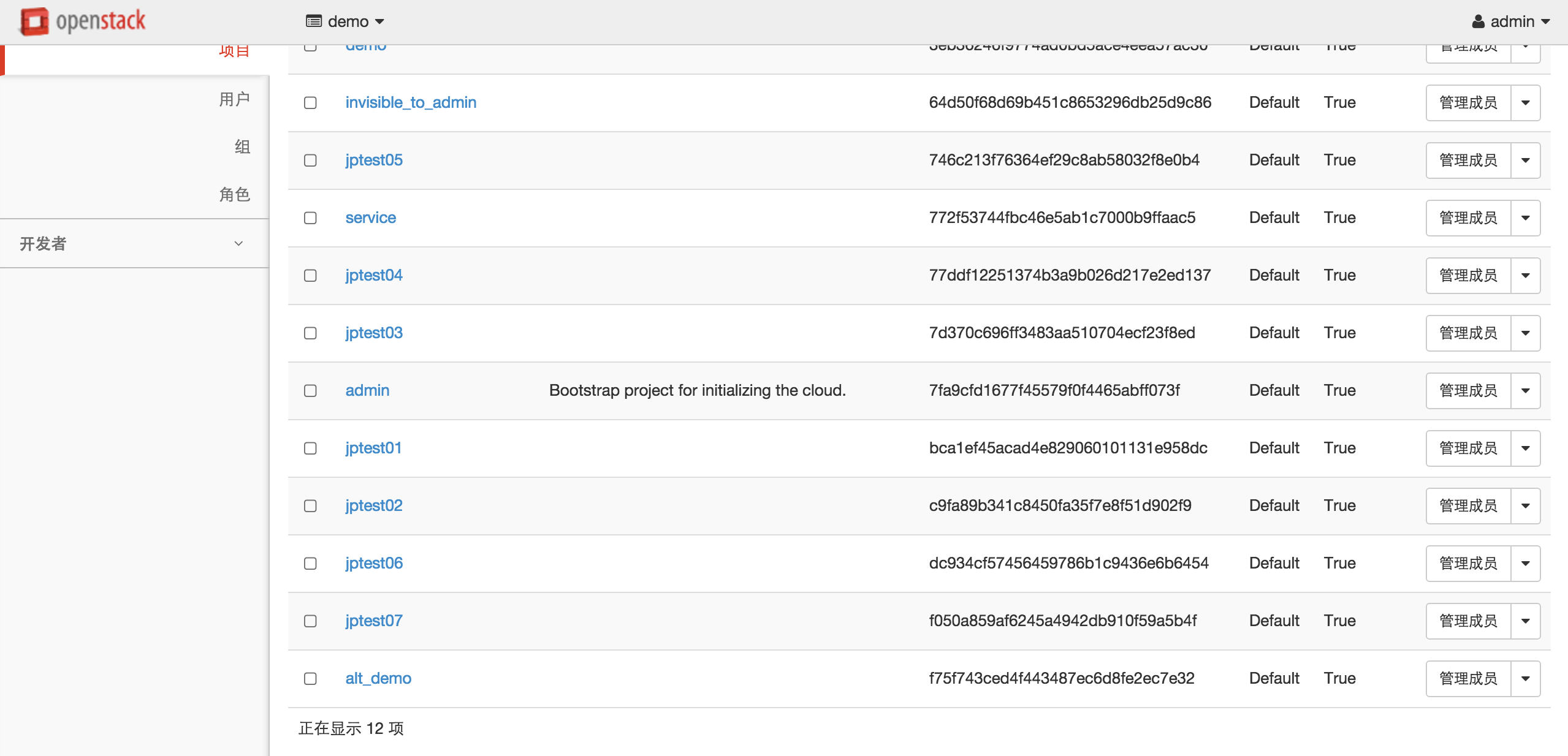
你可以看到设置每页显示条目根本没有起作用。
V2.0 接口项目列表(已在设置中设置每页显示2条记录):
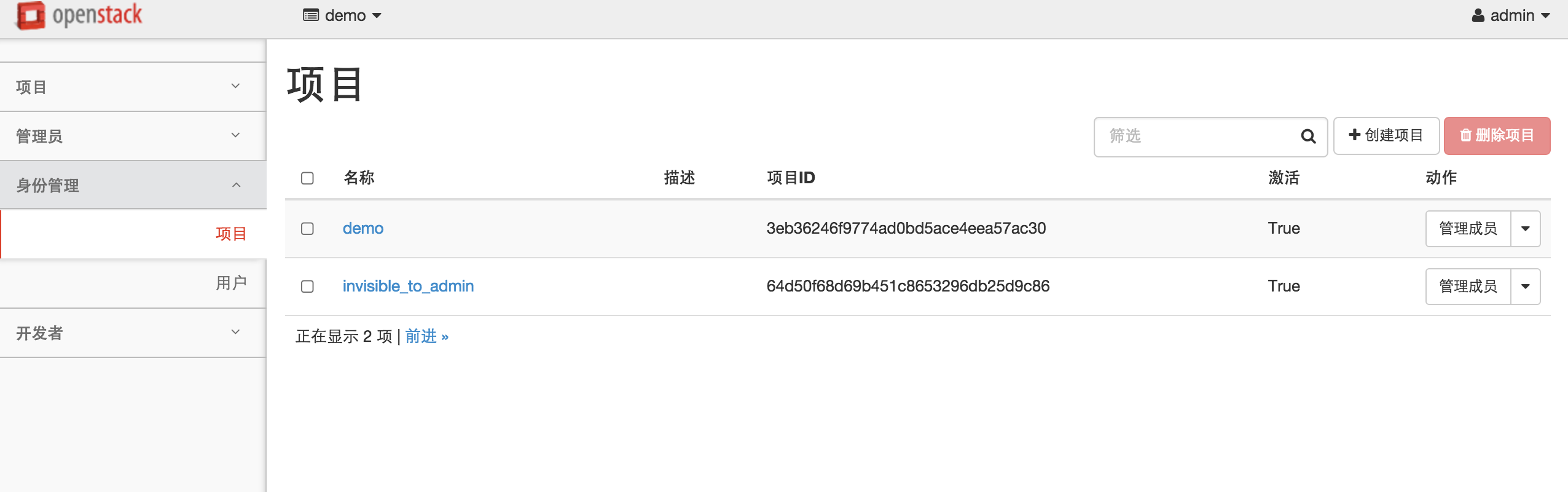
对比就比较明显,使用2.0的keystone接口,至少“前进“->下一页的按钮出来,能够进行分页,但是马上你会发现只有“前进”没有“后退”,不能翻看上一页的数据,不得不说openstack中的分页真是蛋疼。
如果你和我一样,默认的API接口是3,通过一下的方式就可以进行切换。
/openstack_dashboard/local/local_settings.py
WEBROOT="/"
COMPRESS_OFFLINE=True
OPENSTACK_KEYSTONE_DEFAULT_ROLE="Member"
OPENSTACK_HOST="192.168.31.235"
# 注意,这里一定要写2.0
OPENSTACK_API_VERSIONS={"identity":2.0}
OPENSTACK_KEYSTONE_URL="http://192.168.31.235:5000/v2.0"OK,keystone配置成V2.0的接口,接下去我们就来梳理下,“向前”实现的方式。
/openstack_dashboard/dashboards/identity/projects/urls.py
urlpatterns = patterns(
'',
url(r'^$', views.IndexView.as_view(), name='index'),
......通过urls路由映射,可以查看出,项目(tenants)页面请求调用的方法是views.IndexView方法。
代码有点长:
/openstack_dashboard/dashboards/identity/projects/views.py
class IndexView(tables.DataTableView):
table_class = project_tables.TenantsTable
template_name = 'identity/projects/index.html'
page_title = _("Projects")
def has_more_data(self, table):
# 返回True/False,table根据返回值显示是否有下一页的按钮链接
return self._more
def get_data(self):
tenants = []
# 获取request.GET对象中“tenant_marker”值,该值指的是当前页面最后一条tenant的ID值
marker = self.request.GET.get(
project_tables.TenantsTable._meta.pagination_param, None)
# 设置默认没有下一页
self._more = False
# 权限判断,判断当前用户时候有identity:list_projects、list_user_projects权限,
if policy.check((("identity", "identity:list_projects"),),
self.request):
domain_context = api.keystone.get_effective_domain_id(self.request)
# paginate 参数用来设置是否采用分页
try:
tenants, self._more = api.keystone.tenant_list(
self.request,
domain=domain_context,
paginate=True,
marker=marker)
except Exception:
exceptions.handle(self.request,
_("Unable to retrieve project list."))
elif policy.check((("identity", "identity:list_user_projects"),),
self.request):
......重点关注IndexView类中的has_more_data、get_data方法:
has_more_data:返回self._more值,该值根据返回的数据数量确定下一页是否有数据,如果有数据该值为True,即页面上显示“向前”,当然相对应的还有has_prev_data方法,这在下文进行扩展的时候具体说明。
get_data:该方法用来获取项目(tenants)页面tables中显示的数据信息。
接下去重点看下get_data方法,其中:
......
marker = self.request.GET.get(
project_tables.TenantsTable._meta.pagination_param, None)
......这段代码用来从request.GET对象中获取 “project_tables.TenantsTable._meta.pagination_param”,如果没有该值即返回None,那么这里代表的是什么值呢?一点点拆分这部分代码,
project_tables:openstack_dashboard.dashboards.identity.projects.tables.py -> class TenantsTable()该table类定义项目(tenants)页面table。
_meta:指的是TenantsTable中的元类(metaclass),class Meta(object)即:
class Meta(object):
name = "tenants"
verbose_name = _("Projects")
row_class = UpdateRow
row_actions = (UpdateMembersLink, UpdateGroupsLink, UpdateProject,
UsageLink, ModifyQuotas, DeleteTenantsAction,
RescopeTokenToProject)
table_actions = (TenantFilterAction, CreateProject,
DeleteTenantsAction)
pagination_param = "tenant_marker"pagination_param:即class Meta(object)中的属性,属性值是”tenant_marker”,
到了这里就比较清楚了,
marker = self.request.GET.get(
project_tables.TenantsTable._meta.pagination_param, None)
指的是:
marker = self.request.GET.get("tenant_marker", None)经过调试,marker其实获取的是用户点击下一页的时候request.GET中tenant ID值,即浏览器地址中看到的“http://192.168.31.235:8001/identity/?tenant_marker=64d50f68d69b451c8653296db25d9c86”,这个Tenant ID指的是当前页面最后一条tenant 的ID,关于这个ID有什么作用后面会具体说明。
调用api.keystone.tenant_list方法获取tenant list 数据,传入参数paginate布尔值,代码是否进行分页,返回tenants、 self._more,self._more布尔值表示是否有更多的数据需要下一页显示。
tenants, self._more = api.keystone.tenant_list(
self.request,
domain=domain_context,
paginate=True,
marker=marker)调用api.keystone.tenant_list方法获取数据,代码具体如下:
openstack_dashboard/api/keystone.py:
def tenant_list(request, paginate=False, marker=None, domain=None, user=None,
admin=True, filters=None):
manager = VERSIONS.get_project_manager(request, admin=admin)
# 获取每页显示多少条数据
page_size = utils.get_page_size(request)
limit = None
# 判断是否进行分页,如果分页从底层抓取数据的数据的时候夺取一条,用来判断是否还有更多的数据,用于判断是否显示下一页
if paginate:
limit = page_size + 1
has_more_data = False
# if requesting the projects for the current user,
# return the list from the cache
if user == request.user.id:
tenants = request.user.authorized_tenants
elif VERSIONS.active < 3:
# 判断keystone API 接口版本,这里使用的是2.0接口
tenants = manager.list(limit, marker)
# 判断获取的数据是否比每页显示的数据多,如果获取的数据多于每页需要显示的数据,即表示还有下一页数据展示
if paginate and len(tenants) > page_size:
# 按照用户配置显示制定数量的数据,移除多抓取出来的一条数据
tenants.pop(-1)
# 设置下一页数据显示为true,
has_more_data = True
# V3 API
else:
domain_id = get_effective_domain_id(request)
kwargs = {
"domain": domain_id,
"user": user
}
if filters is not None:
kwargs.update(filters)
tenants = manager.list(**kwargs)
return tenants, has_more_data这里调用“tenants = manager.list(limit, marker)”,传入需要参数limit、marker。
limit:每页显示几条数据,抓取数据的时候多抓取一条,用于判断是否还有更多的数据,多取一条数据的目的为了判断显示“上一页”、“下一页”。
marker:这个值很有意思,这是horizon默认分页采用的原理,marker表示当前页面第一条数据或者最后一条数据的ID值,如果点击的是下一页,这个值既是当前页面最后一条记录的ID值,该值传入到keystone中,底层代码判断该条数据在数据库中的位置,下一页的数据就从这条数据所在的位置开始取,取指定数量的数据。如果点击的是上一页,这个数值表示的是当前页面第一条数据的ID,用处也是一样,用于告知底层取下一页的数据从什么位置开始取。
调用keystoneclient的代码发起request请求,获取数据:
keystoneclient/v2_0/tenants.py:
def list(self, limit=None, marker=None):
"""Get a list of tenants.
:param integer limit: maximum number to return. (optional)
:param string marker: use when specifying a limit and making
multiple calls for querying. (optional)
:rtype: list of :class:`Tenant`
"""
# 组拼参数
params = {}
if limit:
params['limit'] = limit
if marker:
params['marker'] = marker
query = ""
if params:
query = "?" + urllib.parse.urlencode(params)
# NOTE(jamielennox): try doing a regular admin query first. If there is
# no endpoint that can satisfy the request (eg an unscoped token) then
# issue it against the auth_url.
try:
tenant_list = self._list('/tenants%s' % query, 'tenants')
except exceptions.EndpointNotFound:
endpoint_filter = {'interface': auth.AUTH_INTERFACE}
tenant_list = self._list('/tenants%s' % query, 'tenants',
endpoint_filter=endpoint_filter)
return tenant_list
这一块没什么好讲,组拼请求参数,发起GET请求至nova api,用于获取数据,没有什么好讲,每个API接口调用都是一样的。
接下来我们具体来看下keystone组件中对于tenant请求的处理,
keystone/keystone/assignment/routers.py
class Public(wsgi.ComposableRouter):
def add_routes(self, mapper):
# 定义处理的控制器类
tenant_controller = controllers.TenantAssignment()
# 映射,将通过“GET”方式以及请求地址带上“/tenants”发送的请求绑定到处理控制器tenant_controller。
mapper.connect('/tenants',
controller=tenant_controller,
# 指定控制器中处理的函数
action='get_projects_for_token',
# 指定请求发送的方式
conditions=dict(method=['GET']))
在“Public”类中的add_routes函数中清楚的定义了,当API请求地址为“/tenants”时并且请求是以“GET”的方式发送过来,调用控制器为tenant_controller中的“get_projects_for_token”函数,tenant_controller控制器指的是controllers.TenantAssignment(),至于如何加载这个路由规则后续的文章讲逐步说明。
控制器处理函数:
/keystone/keystone/assignment/controllers.py
@dependency.requires('assignment_api', 'identity_api', 'token_provider_api')
class TenantAssignment(controller.V2Controller):
"""V2 Tenant api处理类。"""
@controller.v2_auth_deprecated
def get_projects_for_token(self, context, **kw):
"""获取基于用于认证令牌令牌有效的租户。
从上下文获取令牌,验证它并得到有效租户令牌中的用户。
"""
token_ref = utils.get_token_ref(context)
# 获取tenant 列表
tenant_refs = (
self.assignment_api.list_projects_for_user(token_ref.user_id))
# project_ref从V3到V2转换, 该方法只适用于project_refs从2.0控制器返回
# 如果ref是列表类型,我们将通过每个元素反复做转换。
tenant_refs = [self.v3_to_v2_project(ref) for ref in tenant_refs
if ref['domain_id'] == CONF.identity.default_domain_id]
params = {
'limit': context['query_string'].get('limit'),
'marker': context['query_string'].get('marker'),
}
# 格式v2样式项目列表,包括标记/限制。
return self.format_project_list(tenant_refs, **params)这里涉及比较重要的三个方法调用:
1、/keystone/keystone/assignment/core.py:list_projects_for_user():
获取project_ref,即tenants
2、/keystone/keystone/common/controller.py:v3_to_v2_project():
project_ref从V3到V2转换。
3、/keystone/keystone/common/controller.py:format_project_list()
转换v2样式项目列表,包括标记/限制。
这里重点讲一下1和3,
获取project_ref,即tenants
/keystone/keystone/assignment/core.py
# TODO(henry-nash): We might want to consider list limiting this at some
# point in the future.
def list_projects_for_user(self, user_id, hints=None):
assignment_list = self.list_role_assignments(
user_id=user_id, effective=True)
# Use set() to process the list to remove any duplicates
project_ids = list(set([x['project_id'] for x in assignment_list
if x.get('project_id')]))
return self.resource_api.list_projects_from_ids(list(project_ids))
这个函数比较复杂,在这里不进行代码分析,后续有用到在具体进行分析,你只需要了解到,这个方法最终将返回tenants 列表。
默认分页的实现
让我们回到class TenantAssignment(), 看下:
/keystone/keystone/assignment/controllers.py
......
params = {
'limit': context['query_string'].get('limit'),
'marker': context['query_string'].get('marker'),
}
return self.format_project_list(tenant_refs, **params)这部分代码把分页用到的参数:limit、marker 、以及tenant_refs传入到self.format_project_list() 实现分页,但是可以这里知道Mitaka版本的horizon并没有在把limit、marker 参数传递过来,因此分页并没有起作用。
keystone/keystone/common/controller.py(384)format_project_list()
def format_project_list(self, tenant_refs, **kwargs):
"""Format a v2 style project list, including marker/limits."""
# 获取horizon传递过来的marker值,该值表示的是上一页最后一条记录的ID值或者最后一条记录的ID值
marker = kwargs.get('marker')
# 初始化下一页数据或上一个数据从什么位置开始取
first_index = 0
if marker is not None:
# 循环确定marker ID表示的记录位置,
for (marker_index, tenant) in enumerate(tenant_refs):
if tenant['id'] == marker:
# we start pagination after the marker
# 通过比对marker值,确定下一页数据或者上一页数据从first_index位置开始取
first_index = marker_index + 1
break
else:
msg = _('Marker could not be found')
raise exception.ValidationError(message=msg)
# limit 表示取几条记录
limit = kwargs.get('limit')
last_index = None
if limit is not None:
try:
limit = int(limit)
if limit < 0:
raise AssertionError()
except (ValueError, AssertionError):
msg = _('Invalid limit value')
raise exception.ValidationError(message=msg)
# 确定分页取到第几条记录的位置
last_index = first_index + limit
# 通过列表切片的形式进行分页,这里可以看到没有实现真正的数据库分页,
# 还是一种简单的分页,这种分页比前段分页就是降低了请求返回的数据包大小
tenant_refs = tenant_refs[first_index:last_index]
for x in tenant_refs:
if 'enabled' not in x:
x['enabled'] = True
o = {'tenants': tenant_refs,
'tenants_links': []}
return o具体分析可以看我的代码注释,这一块没有起到正真的分页,只是一种伪分页,没有实现数据库分页机制,在性能上并没有提升多少。
实现项目列表分页
OK,说了这么多,接下来我就来讲讲怎么通过扩展API接口来实现项目组列表的分页,时间仓促以及个人理解有限,编码格式可能并不是标准规范请谅解。
Horizon:
openstack_dashboard/dashboards/identity/projects/views.py
class IndexView(tables.DataTableView):
....
def has_more_data(self, table):
# author: jpzhang.ht@gmail.com
# blog: http://www.smallartisan.site/ or http://blog.csdn.net/u011521019
# 返回True/False,table根据返回值显示是否有下一页的按钮链接
return self._more
def has_prev_data(self, table):
# author: jpzhang.ht@gmail.com
# blog: http://www.smallartisan.site/ or http://blog.csdn.net/u011521019
# 返回True/False,table根据返回值显示是否有上一页的按钮链接
return self._prev
....
def get_data(self):
#获取prev_pagination_param,该值指的是当前页面第一条tenant的ID值
prev_marker = self.request.GET.get(
project_tables.TenantsTable._meta.prev_pagination_param, None)
if prev_marker is not None:
marker = prev_marker
else:
# 获取request.GET对象中“tenant_marker”值,该值指的是当前页面最后一条tenant的ID值
marker = self.request.GET.get(
project_tables.TenantsTable._meta.pagination_param, None)
# 根据是否是上一页还是下一页,得到一个布尔值
reversed_order = prev_marker is not None
tenants = []
# 权限判断,判断当前用户时候有identity:list_projects、list_user_projects权限,
if policy.check((("identity", "identity:list_projects"),),
self.request):
domain_context = api.keystone.get_effective_domain_id(self.request)
# paginate 参数用来设置是否采用分页
try:
tenants, self._more, self._prev = api.keystone.tenant_list_paged(
self.request,
domain=domain_context,
paginate=True,
marker=marker,
sort_dir='asc', # 排序
sort_key='id', # 排序字段
reversed_order=reversed_order)
except Exception:
self._prev = self._more = False
exceptions.handle(self.request,
_("Unable to retrieve project list."))
......这块的代码比较简单,def has_more_data(self, table);def has_prev_data(self, table)定义两个属性值用来表示列表是否有上一页数据还是有下一页数据,根据返回的数据长度来确定,获取N+1条数据,其中N表示每页显示的数据,每次取数据都多取一条记录用来判断是否有上一页数据还是有下一页数据。
prev_marker/marker用来获取点击上一页或者下一页的时候URL路径上表示的project ID值,这个值用来干什么上面已有介绍,这里不再叙述。
tenant_list_paged(),这个方法是自己定义的主要用来调用keystoneclient发起request请求,向keystone获取project的数据。其中有几个参数在这个说明下:
- paginate:用来表示是否采用分页机制来获取数据,默认是True,采用分页。
- marker:用来传递点击上一页或者下一页时,当前页面第一条或者最后一条project ID值。
- sort_dir:用来指定数据库获取数据时排序,如果是点击下一页数据库获取数据排序是“acs”,上一页时“desc”排序
- sort_key:用来指定排序字段,默认是project “id”值
openstack_dashboard/api/keystone.py
def tenant_list_paged(request, paginate=False, marker=None, domain=None, user=None,
admin=True, filters=None, sort_key="name", sort_dir="desc",
reversed_order=False):
"""
author: jpzhang.ht@gmail.com
blog: http://www.smallartisan.site/ or http://blog.csdn.net/u011521019
"""
has_more_data = False
has_prev_data = False
manager = VERSIONS.get_project_manager(request, admin=admin)
limit = None
page_size = utils.get_page_size(request)
# 判断是否进行分页,如果分页从底层抓取数据的数据的时候夺取一条,用来判断是否还有更多的数据,用于判断是否显示下一页
if paginate:
if reversed_order:
sort_dir = 'desc' if sort_dir == 'asc' else 'asc'
limit = page_size + 1
# if requesting the projects for the current user,
# return the list from the cache
if user == request.user.id:
tenants = request.user.authorized_tenants
elif VERSIONS.active < 3:
# 判断keystone API 接口版本,这里使用的是2.0接口
tenants = manager.list_paged(limit, marker, sort_key=sort_key, sort_dir=sort_dir)
# V3 API 这里主要通过V2API 来讲解,故此不对V3 API进行扩展
else:
domain_id = get_effective_domain_id(request)
kwargs = {
"domain": domain_id,
"user": user
}
if filters is not None:
kwargs.update(filters)
tenants = manager.list(**kwargs)
tenants, has_more_data, has_prev_data = update_pagination(
tenants, page_size, marker, sort_dir, sort_key, reversed_order)
return (tenants, has_more_data, has_prev_data)添加调用keystoneclient方法,其中:
if paginate:
if reversed_order:
sort_dir = 'desc' if sort_dir == 'asc' else 'asc'
limit = page_size + 1根据paginate 和 reversed_order参数来确定获取数据时采用的排序方式。limit以及获取多少条数据。
manager.list_paged()自定义在keystoneclient的函数,用来发起request请求的函数。
update_pagination()函数,根据返回的数据长度设置has_more_data,has_prev_data属性值,如果是上一页数据,需要根据排序(“acs”/“desc”)反转排序处理,保证显示数据顺序正常,这种分页有一个弊端就是对每一个数据显示的顺序有依赖性,因为底层是用过传递过去ID来确定该条记录在数据库中的位置,以此来获取上一页或者下一页的数据。如果不怕麻烦可以通过django的Paginator分页模块,传递参数(当前页数、每页显示多少条记录)到底层进行分页,这种实现机制或更好一些,这里不再具体来说明,要实现页时比较简单。
def update_pagination(entities, page_size, marker, sort_dir, sort_key,
reversed_order):
has_more_data = has_prev_data = False
if len(entities) > page_size:
has_more_data = True
entities.pop()
if marker is not None:
has_prev_data = True
# first page condition when reached via prev back
elif reversed_order and marker is not None:
has_more_data = True
# last page condition
elif marker is not None:
has_prev_data = True
# restore the original ordering here
if reversed_order:
entities = sorted(entities, key=lambda entity:
(getattr(entity, 'id') or '').lower(),
reverse=(sort_dir == 'asc'))
return entities, has_more_data, has_prev_dataKeystoneclient:
keystoneclient的修改比较简单,这里我们API接口用的是V2.0,因此我们只需要修改V2.0即可。
keystoneclient/v2_0/tenants.py
class TenantManager(base.ManagerWithFind):
......
def list_paged(self, limit=None, marker=None, sort_key=None, sort_dir=None):
"""
author: jpzhang.ht@gmail.com
blog: http://www.smallartisan.site/ or http://blog.csdn.net/u011521019
"""
# 组拼参数
params = {}
if limit:
params['limit'] = limit
if marker:
params['marker'] = marker
if sort_key:
params['sort_key'] = sort_key
if sort_dir:
params['sort_dir'] = sort_dir
query = ""
if params:
query = "?" + urllib.parse.urlencode(params)
try:
tenant_list = self._list('/tenants/paged%s' % query, 'tenants')
except exceptions.EndpointNotFound:
endpoint_filter = {'interface': auth.AUTH_INTERFACE}
tenant_list = self._list('/tenants%s' % query, 'tenants',
endpoint_filter=endpoint_filter)
return tenant_listkeystoneclient 中在class TenantManager(base.ManagerWithFind)类中扩展def list_paged()函数,组拼GET请求发送的参数,以及GET请求发送的请求地址“/tenants/paged”,这个地址即为自己在keystone中自己扩展的API请求接口。
Keystone:
keystone 处理tenants的逻辑代码主要放在/keystone/assignment中,本文不具体介绍keystone的目录结构以及代码逻辑,仅说明扩展接口完成tenants分页数据的展示。
keystone/assignment/routers.py
class Admin(wsgi.ComposableRouter):
def add_routes(self, mapper):
# add by jpzhang.ht@gmail.com 2016/08/20
mapper.connect('/tenants/paged',
controller=tenant_controller,
action='get_projects_for_token_paged',
conditions=dict(method=['GET']))
.....定义请求路由映射,即请求地址为“/tenants/paged”,调用的控制器为“tenant_controller”,处理的函数为“get_projects_for_token_paged”,这里主要是请求路由与控制器处理函数建立映射关系。
在控制器中定义“get_projects_for_token_paged”处理函数:
keystone/assignment/controllers.py
class TenantAssignment(controller.V2Controller):
@controller.v2_auth_deprecated
def get_projects_for_token_paged(self, context, **kw):
"""
add by jpzhang.ht@gmail.com 2016/08/18
"""
token_ref = utils.get_token_ref(context)
params = {
'limit': context['query_string'].get('limit'),
'marker': context['query_string'].get('marker'),
'sort_key': context['query_string'].get('sort_key'),
'sort_dir': context['query_string'].get('sort_dir'),
}
tenant_refs = (
self.assignment_api.list_projects_for_user_paged(user_id=token_ref.user_id, params=params))
# tenant_refs = [self.v3_to_v2_project(ref) for ref in tenant_refs
# if ref['domain_id'] == CONF.identity.default_domain_id]
return self.format_project_list(tenant_refs)组拼GET过来的参数,self.assignment_api.list_projects_for_user_paged()函数过去tenants数据。
keystone/assignment/core.py
class Manager(manager.Manager):
def list_projects_for_user_paged(self, user_id, params=None):
"""
add by jpzhang.ht@gmail.com 2016/08/20
"""
return self.driver.list_projects_for_user_paged(user_id=user_id, params=params)这里调用相应的driver获取数据,这里只针对sql进行扩展,对ldap、kvs不做扩展。
keystone/assignment/backends/sql.py
class Assignment(keystone_assignment.AssignmentDriverV9):
......
def list_projects_for_user_paged(self, role_id=None,
user_id=None, group_ids=None,
domain_id=None, project_ids=None,
inherited_to_projects=None, params=None):
"""
add by jpzhang.ht@gmail.com 2016/08/18
"""
with sql.session_for_read() as session:
marker_row = None
if params.has_key('marker'):
marker_row = session.query(Project).filter_by(id=params['marker']).first()
query = session.query(Project)
query = sqlalchemyutils.paginate_query(query,
Project, params['limit'],
[params['sort_key']],
marker=marker_row,
sort_dir=params['sort_dir'])
return query.all()获取数据库中对应的记录,其中:
marker_row = session.query(Project).filter_by(id=params['marker']).first()根据传递过来的tenants id值获取这条记录在数据库中的位置,如果上一页倒序获取数据,原理简单推算下你就会明白为什么上页数据是倒序取。
当然这里我写的比较暴力,之前考虑过沿用其目前的获取数据的方式,但发现最后因为上一页、下一页数据对传递过来的ID值依赖性比较强,并且“RoleAssignment”这张表tenants ID值并不是主键,将会导致根据marker值获取数据的记录将会不准,因此我这边直接去获取project这张表中的数据。
重启keystone,apache即可查看分页已经实现:
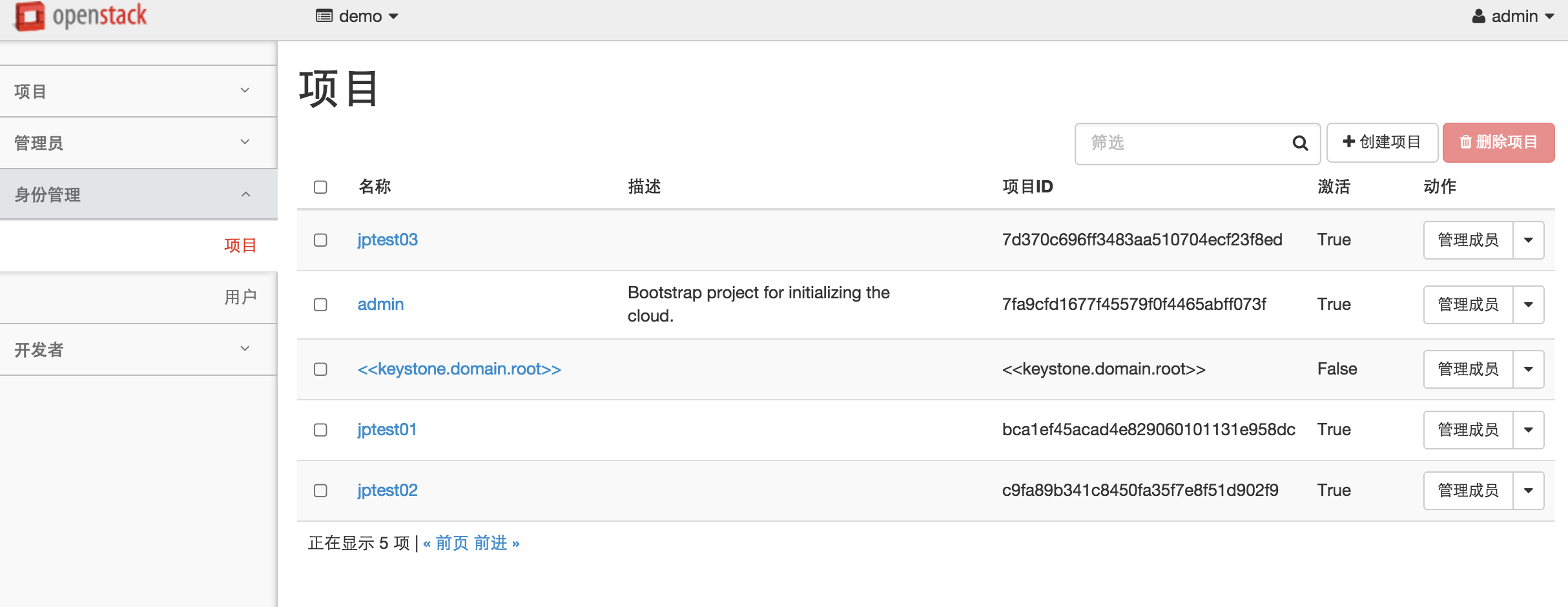
四、总结
通过keystone tenant项目列表的分页,其实可以看出openstack的当前的分页现状,目前我这边方式实现分页比较暴力,如果想在其他组件上通过这种方式也是可行的例如镜像、配置模版等,不过需要经过测试是否可行,我这里就不在具体说明,如果大家有其他好的方式可以告知我,互相学习。















 8452
8452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









