







信息熵
1. 熵
1.1 熵的定义
定义一个用来描述事件的不确定程度的量,即信息量,假设某一事件
x
发生的概率是
- 当 p(x)=0 的时候, I(x)=+∞ ;
- 当 p(x)=1 的时候, I(x)=0
- 当 p(x)<p(y) 的时候, I(x)>I(y)
- I(x)>=0
- 当事件相互独立的时候,联合概率密度 p(x,y)=p(x)p(y) ,信息量为 I(x,y)=I(x)+I(y) .即独立事件同时发生的的信息量等于单个事件信息量之和
满足上面的性质,
c
是常数,对数的底数任意,于是就将
熵是用来描述一个系统的平均信息量的,即一个系统的平均不确定程度,假设某一系统(随机变量)由很多事件(观测值) (x0,x1,....,xn−1) 构成,事件的概率分布为 (p(x0),p(x1),...,p(xn−1)) ,定义:
信息熵
1.2 熵的极大值定理证明:
一个随机变量的熵值在各个取值的概率都相等的时候取得最大(每个系统的熵是相对的,只有同一系统才能比较熵值的大小,不同的系统不能比较)
简化写为
(1)式是熵的一阶导数,(2)式是熵的二阶导,由于:
a . 二阶导小于零
b . pi=0 的时候一阶导 →+∞ , pi=1 的时候一阶导 →−∞
得出则熵的函数是一个上凸的函数,函数的极值点就是最大值点。
对于每一个
i≠j
都有式子
pi1−pi−∑k≠i,jkpk=1
,则有所有
pi(i≠j)
相等,记为p,则有
即当且仅当随机变量所有的事件的概率相等时,随机变量的熵值取得最大值。
1.3 凸函数性质
注意:这里的凸函数是指的下凸,上凸称作凹
凸函数 f(x) 有两个性质
- 二阶导大于零
- 对所有 0<=λ<=1x1≠x2 ,有 f(λx1+(1−λ)x2)<=λf(x1)+(1−λ)f(x2)
Jensen不等式:
对于一个下凸的函数f和一个随机变量X,有
证明:
考虑离散情况,使用数学归纳法:
当只有二项分布的时候,由凸函数的性质,有 p1f(x1)+p2f(x2)>=f(p1x1+p2x2) ,显然成立。
假设有n-1个分布点的时候,不等式成立,即已知
对于n个分布点:
即得证。
形象地:
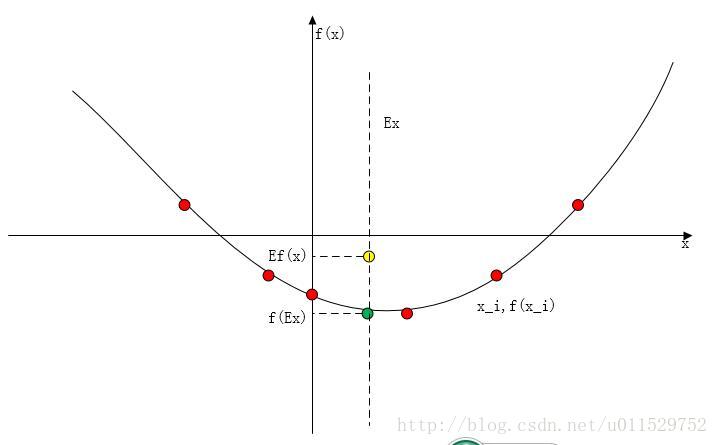
红点是随机分布的分布点,绿点是 f(Ex) ,黄点所在的纵坐标是 E(f(x)) ,显然有 f(E(x))<=E(f(x)) 的
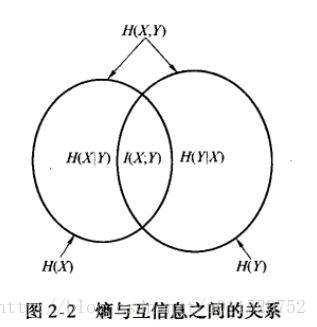
2. 联合熵与条件熵
2.1 联合熵
对于二元的概率,联合熵为
2.2 条件熵
当X取某一观测值,条件概率为
p(Y|X=x)
,此时对于随机变量Y来说,在X=x的条件下熵是:
条件熵就定义为当X取遍所有观测值时,随机变量Y的熵的期望
链式法则:
也可以由
两边同时取期望得到
2.3 联合熵和条件熵的辨析
条件熵是在确定某一条件的情况下,系统的平均不确定度。此时如果加上自身的不确定度,则等于系统的整体不确定度。即条件确定,条件下的状态确定,则系统确定。
3. 相对熵与互信息
3.1 相对熵
假设有一个随机变量X,对于他所有的取值x,都对应着两个分布p和q,即
假设相对熵描述对于相同取值的随机变量的不同分布之间的距离
辨析:
a. 距离是相对的而且是不对称的, D(p||q)≠D(q||p) ,在度量的时候要么在 D(p||q) 的框架下,要么反之,不能混用。
b. D(p||q)>=0 ,当且仅当所有 pi=qi 的时候取等号。
证明:
得 D(p||q)>=0 ,只有当所有 pi=cqi ,的时候取等号,又 ∑ipi=∑iqi=1 ,有 ∑ipi=c∑iqi=∑iqi ,得c=1 。即只有当所有 pi=qi 的时候,才能取等号。
c.约定 0log00=0 , 0log(0q)=0 , plog(p0)=∞
3.2 互信息
互信息用来描述两个随机变量之间的相关性,定义为联合概率密度和概率密度之积 的相对熵。
辨析:
a. 当I(X;Y)值比较大的时候,表明相关性很强,因为p(x)p(y)表示如果两个随机变量独立分布的时候的概率密度。反之,如果I(X;Y)的值很小甚至接近于0,表明X和Y的相关性很弱,因为联合概率密度接近于独立分布的概率密度。
b.互信息是对称的,I(X;Y)=I(Y;X),只是分母分子不能反。
c.互信息的链式规则:
互信息也可以解释为给定Y的情况下X的不确定程度的减少量,如果给定Y,X的熵并没有变少,则X和Y相对独立,减少量就少。反之,给定Y后熵的减少量多,则X和Y之间存在很强的相关性。
3.3 自信息
现有的链式法则有:
得
自信息















 4074
4074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









