






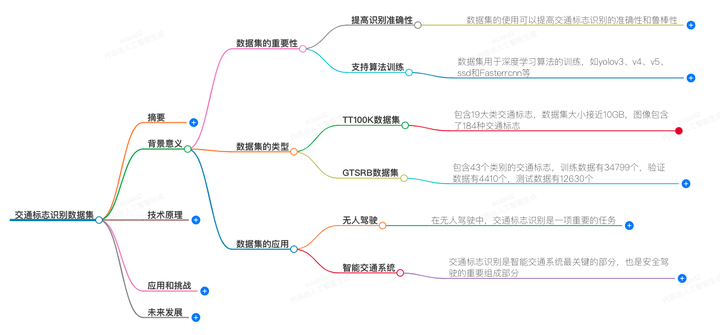
交通标志识别数据集是用于训练和测试交通标志识别算法的集合,它包含了大量的图像数据以及相应的标注信息。这些数据集通常涵盖了多种交通标志类别,并在不同的光照、天气条件下拍摄,以提高模型的泛化能力。深度学习技术,尤其是像YOLOv8这样的算法,被广泛应用于这些数据集上,以实现高精度的交通标志检测。
一、背景
交通标志识别数据集的背景意义主要体现在两个方面:
-
交通安全需求:随着汽车保有量的增加,交通事故频发,许多事故是由于驾驶员未能正确识别交通标志导致的。通过准确识别交通标志,可以减少交通事故,保障人身和财产安全。
-
自动驾驶技术发展:在自动驾驶技术中,车辆需要准确识别交通标志以做出正确的驾驶决策,因此交通标志识别是自动驾驶系统的关键技术之一。
二、技术原理:
交通标志识别技术主要基于深度学习,尤其是卷积神经网络(CNN)。这些模型通过学习图像中的特征来识别交通标志。YOLO(You Only Look Once)系列算法是一种流行的单阶段目标检测算法,它通过输入图像,经过主干网络(Backbone)、特征增强网络(Neck)和检测头(Head)来预测交通标志的位置和类别。
三、应用和挑战:
交通标志识别数据集在自动驾驶、智能交通管理等领域有广泛应用。然而,实际应用中仍面临诸多挑战。例如,需要考虑计算资源限制,因此模型轻量化和压缩技术变得重要。此外,数据集的质量和多样性直接影响识别系统的性能,因此需要不断更新和扩充数据集。同时,还需要考虑光照、气候、阴影等环境因素对识别效果的影响。
未来发展:
未来,交通标志识别数据集的发展方向可能包括以下几个方面:
1、数据集多样化:增加更多样化的环境条件、不同尺寸和形状的交通标志,以及精确的标注信息,提供全面而丰富的训练和测试平台。
2、模型优化:继续优化深度学习模型,特别是在速度和准确度上取得更好的平衡。
3、环境适应性:提高模型在不同光照、气候条件下的适应性,减少环境因素对识别效果的影响。
4、轻量化和压缩:研究模型轻量化和压缩技术,减少计算复杂度和内存占用,便于部署在边缘设备上。
5、算法融合:结合不同深度学习算法的优点,进一步优化交通标志识别性能。
在学术界,像麻省理工学院、斯坦福大学和卡内基梅隆大学这样的知名研究机构,都在这一领域取得了显著成果。他们的研究不仅在理论上推动了技术的发展,也在实际应用中展现了巨大的潜力。这些成果的积累和应用,为交通标志识别数据集的构建和优化提供了坚实的基础。
接下来,我们来看看这些数据集都有哪些,它们是如何为交通标志识别技术的研究和应用提供宝贵资源的。
数据集:GTSRB - German Traffic Sign Recognition Benchmark
-
发布时间:2011-09
-
数据集内容:GTSRB数据集是一个用于交通标志识别的基准数据集,包含超过50,000张交通标志图像,分为43个不同的类别。该数据集广泛用于计算机视觉和机器学习领域的研究,特别是用于训练和评估交通标志识别算法。
-
数据集地址:GTSRB|交通标志识别数据集|图像分类数据集
数据集:BelgiumTS - Belgium Traffic Sign Dataset
-
发布时间:2013-09
-
数据集内容:Belgium Traffic Sign Dataset是一个用于交通标志分类的图像数据集。该数据集包含62个不同类别的交通标志,总共有7000张彩色图像。这些图像是在比利时不同地点拍摄的,涵盖了各种天气和光照条件。数据集被分为训练集和测试集,分别包含4575张和2520张图像。
数据集:TT100K - Tsinghua-Tencent 100K
-
发布时间:2016-09
-
数据集内容:TT100K数据集是一个用于交通标志检测和识别的大规模数据集,包含100,000张标注的交通标志图像。该数据集主要用于计算机视觉和自动驾驶领域的研究。
数据集:STSD - Swedish Traffic Sign Dataset
-
发布时间:2013-01
-
数据集内容:STSD(Swedish Traffic Sign Dataset)是一个包含瑞典交通标志图像的数据集。该数据集主要用于交通标志识别和分类任务,包含了多种不同类型的交通标志图像。
-
数据集地址:STSD |交通标志识别数据集|图像分类数据集
数据集:STS - Swedish Traffic Sign Dataset
-
发布时间:2013-01
-
数据集内容:STS - Swedish Traffic Sign Dataset 是一个包含瑞典交通标志图像的数据集,主要用于交通标志识别和分类任务。该数据集包含了多种类型的交通标志,每张图像都带有相应的标签,便于进行机器学习和深度学习模型的训练和测试。
-
数据集地址:STS |交通标志识别数据集|机器学习数据集
免费数据集网站:遇见数据集
遇见数据集是一个平台,致力于让每个数据集都被发现,让每一次遇见都有价值,
1、数据获取的便利性:
遇见数据集通过集中整合全球数据资源,提供了一个一站式平台,使得用户能够轻松搜索和访问各种数据集,无需在多个来源之间进行切换,从而提高了数据获取的效率。
2、数据的可发现性:
通过详细的数据标签和分类系统,遇见数据集增强了数据集的可发现性,帮助用户快速找到特定领域的数据集,尤其是对于特定研究领域或应用场景的数据,极大地方便了数据的检索和使用。
3、数据更新的及时性:
遇见数据集频繁更新数据集内容,确保用户能够获取最新的数据资源,这对于需要最新数据进行分析和研究的用户来说尤为重要,保证了数据的时效性和相关性。


















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









