






2025-04-18 , 由浙江大学、哈尔滨工业大学、郴州市第一人民医院、新加坡国立大学等机构合作创建了 Eyecare-100K数据集,这是首个涵盖多种模态、任务和疾病的高质量眼科视觉指令数据集,为眼科智能诊断领域提供了关键资源,推动了医学视觉语言模型(Med-LVLMs)在眼科的精细化理解与应用。
一、研究背景
医学大型视觉语言模型(Med-LVLMs)在医疗领域展现出巨大潜力,但在眼科智能诊断方面,由于依赖于一般医疗数据和粗粒度的全局视觉理解,其表现受到限制。
目前遇到困难和挑战:
1、数据方面:缺乏深度标注、高质量、多模态的眼科视觉指令数据。
2、基准测试方面:缺少全面系统的基准测试,无法准确评估 Med-LVLMs 在眼科诊断任务上的表现。
3、模型方面:现有模型架构难以适应眼科病变识别所需的细粒度、区域特定的视觉理解。
数据集地址:Eyecare-100K|眼科图像分析数据集|疾病诊断数据集
二、 让我们一起来看一下Eyecare-100K数据集
Eyecare-100K 是一个包含约 10.2 万对视觉问答(VQA)的高质量眼科视觉指令数据集,覆盖 8 种成像模态、15 种以上解剖结构和 100 多种眼病。
Eyecare-100K 集成了来自 13 个公共数据集、3 家医院和 3 个公共医学案例库的 58485 张眼科图像。它涵盖了荧光素血管造影(FA)、吲哚青绿血管造影(ICGA)、光学相干断层扫描(OCT)、眼底摄影、超声生物显微镜(UBM)、裂隙灯、荧光素染色成像和计算机断层扫描(CT)等 8 种成像模态,跨越 15 种解剖结构和 100 多种眼科疾病及罕见病症,极大地增强了数据集的多样性和全面性。
数据集构建:
构建过程中,开发了一个多智能体数据引擎,用于从大规模原始数据中提取、清理、标准化信息,并进行专家审核。该引擎包含信息提取器、医疗案例收集器、数据清洗器、问答模板库、问答生成器和基于人类偏好的审核器等 6 个组件,最终将数据组织成封闭问答(多项选择题)、开放问答(简答题)和报告生成(长文本回答)三种类型的 VQA 任务。
数据集特点:
1、多模态:涵盖多种成像模态,如 FA、ICGA、OCT 等。
2、多任务:支持封闭问答、开放问答和报告生成等多种任务。
3、高质量标注:经过专家审核,确保标注的准确性和标准化。
4、大规模:包含约 10.2 万对视觉问答,数据量丰富。
基准测试:
基于 Eyecare-100K 构建的 Eyecare-Bench 基准测试,包含约 1.5 万个测试样本,覆盖多种任务、模态和疾病类别。在该基准测试中,EyecareGPT 模型取得了平均准确率 84.56% 的最佳性能,显著优于其他模型,验证了数据集的有效性和模型的优越性。

Eyecare-100K 概述。Eyecare-100K 汇集了来自 8 个模态、15 个以上解剖结构和 100 个以上眼科疾病的真实世界眼科数据,支持多模态报告生成和精细视觉问答任务。
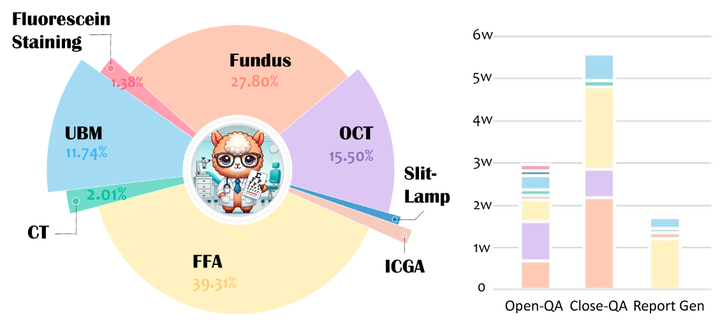
Eyecare-100K 数据统计
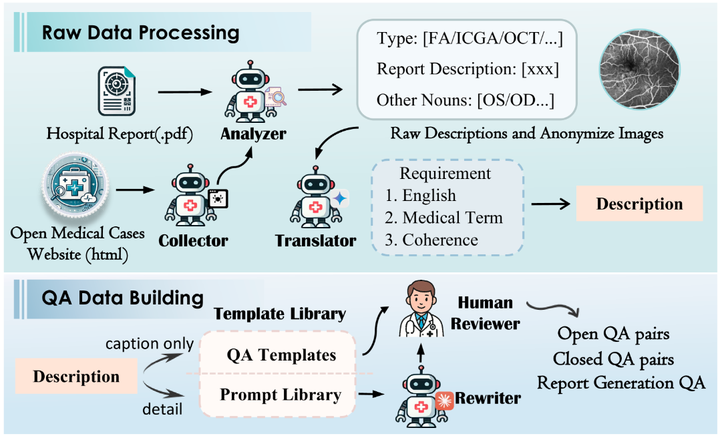
多智能体数据引擎框架
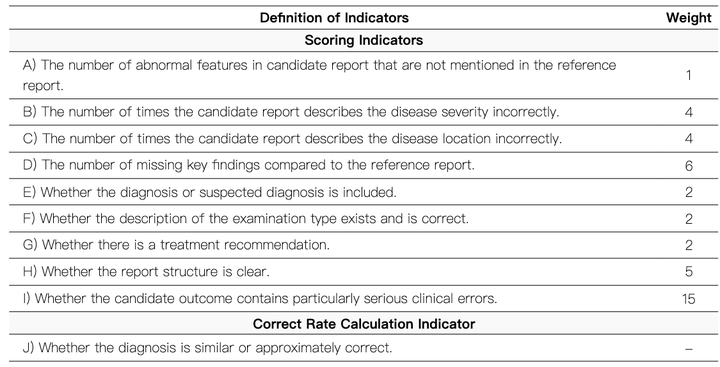
十项评估框架
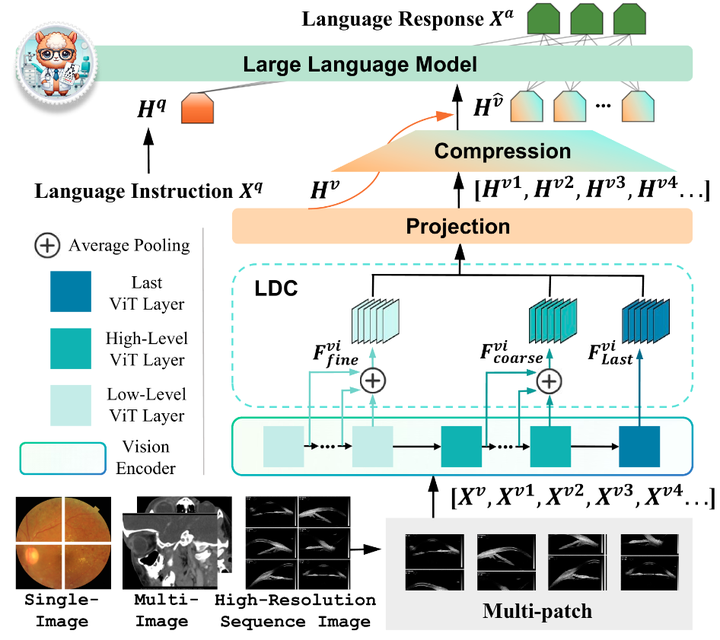
EyecareGPT 的模型架构
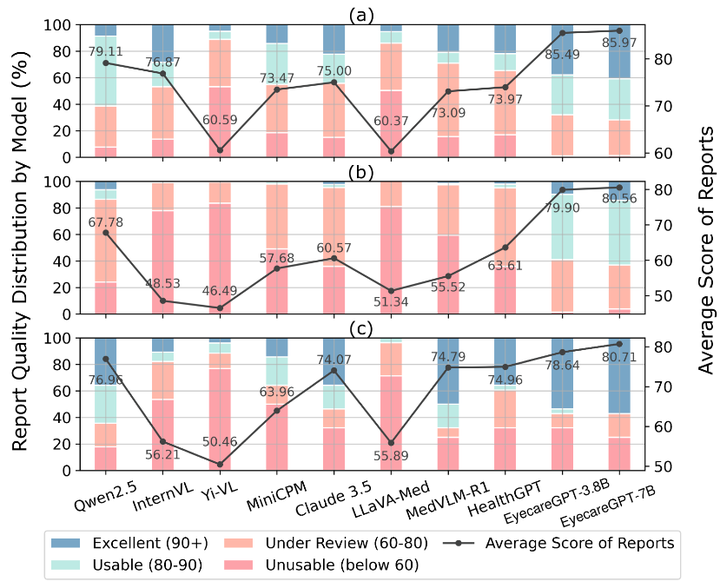
基于 GPT-4 在报告生成任务中评估结果,包括(a)FA,(b)UBM 和(c)CT 模态。
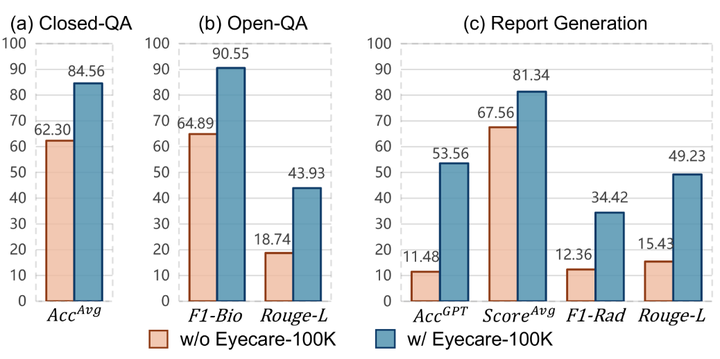
在 Eyecare-100K 上进行微调后的结果。
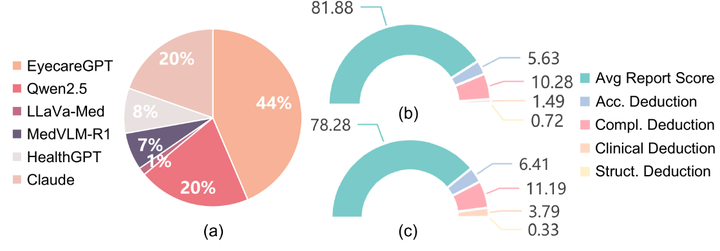
医生对生成的报告(a)和 EyeEval 可靠性(b、c)的偏好
三、展望Eyecare-100K数据集
以前,医生诊断糖尿病视网膜病变主要依靠人工检查眼底照片。这个过程非常耗时,因为医生需要仔细观察每一张照片,寻找微血管瘤、出血、渗出物等病变特征。而且,由于人眼的局限性,有时候一些细微的病变可能被遗漏,导致诊断不够准确。对于大规模的筛查项目来说,这种方式效率低下,很难快速处理大量患者的数据。
现在借助 Eyecare-100K 数据集,那可就不一样了
这个数据集包含了大量高质量、多模态的眼科图像以及深度标注信息,涵盖了多种眼病,包括糖尿病视网膜病变。研究人员利用这个数据集训练出了更精准的医学视觉语言模型(如 EyecareGPT),这些模型能够自动识别眼底照片中的病变特征。
诊断效率大幅提升:模型可以在短时间内处理大量图像,快速筛查出高风险患者,大大节省了医生的时间。比如,在一些眼科智能诊疗中心,患者可以在更近的医疗机构完成眼底检查,智能系统能够快速给出初步诊断结果,缩短了患者的等待时间。
诊断准确性提高:由于数据集的标注非常详细,模型学习到了更丰富的病变特征和诊断知识,能够更准确地识别病变。这有助于早期发现糖尿病视网膜病变,及时进行干预,减少因延误治疗导致的视力损害。
个性化医疗体验:基于 Eyecare-100K 训练的模型还可以生成详细的诊断报告,为医生提供更全面的参考信息,帮助制定个性化的治疗方案。
更多免费的数据集,请打开:遇见数据集
遇见数据集-让每个数据集都被发现,让每一次遇见都有价值。遇见数据集,领先的千万级数据集搜索引擎,实时追踪全球数据集,助力把握数据要素市场。![]() https://www.selectdataset.com/
https://www.selectdataset.com/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









