






2025-05-07,由加州大学圣地亚哥分校创建了 Adaptive Motion Optimization (AMO) 数据集,该数据集通过结合运动捕捉数据和概率采样的躯干姿态,生成全身参考动作,以解决运动模仿强化学习中的分布偏差问题。
一、研究背景
人形机器人通过全身运动来扩展其操作空间,例如从地面捡起物体。然而,实现这种能力面临高自由度和非线性动态的挑战。
目前遇到困难和挑战:
1、高自由度和非线性动态:人形机器人全身控制的高维、非线性和接触丰富的特性使得传统基于模型的最优控制方法难以实现。
2、运动模仿的局限性:现有的基于运动捕捉(MoCap)的方法存在运动学偏差,无法满足人形机器人的动态约束,导致模拟运动与硬件可执行行为之间存在差距。
3、实时适应性不足:现有的方法在动态场景中难以快速适应未结构化的输入,例如反应式遥操作或环境干扰。
数据集地址:AMO数据集|人形机器人数据集|运动控制数据集
二、让我们一起看一下AMO数据集
Adaptive Motion Optimization (AMO) 数据集是为了解决人形机器人在高自由度和非线性动态下的全身控制问题而设计的。它通过结合运动捕捉数据和概率采样的躯干姿态,生成全身参考动作,从而提供了一个混合数据集,用于训练能够适应潜在的“Out-of-Distribution”(O.O.D.)命令的网络。
数据集构建
1、混合运动合成:将运动捕捉数据中的手臂轨迹与概率采样的躯干姿态融合,生成上半身命令集。这些命令驱动动力学感知的轨迹优化器,生成全身参考动作。
2、轨迹优化:使用基于动力学的轨迹优化器,将这些命令转换为满足运动学可行性和动态约束的全身参考动作。
3、数据集收集:通过上述方法生成的参考动作被收集并存储,形成 AMO 数据集。
数据集特点
1、混合数据集:结合了运动捕捉数据和概率采样的躯干姿态,消除了传统运动捕捉方法的运动学偏差。
2、动态可行性:生成的参考动作满足动力学约束,确保在真实硬件上可执行。
3、支持全身控制:数据集中的动作涵盖了手臂、躯干和腿部的协调运动,支持超灵巧全身控制。
数据集使用
AMO 数据集用于训练一个网络,该网络能够将躯干命令转换为参考下肢姿态。结合 AMO 模块的输出,可以训练强化学习策略,实现全身控制。
基准测试
在模拟和真实机器人实验中,AMO 数据集支持的系统在全身控制任务中表现出色,与现有方法相比,工作空间扩大了 50%,显著提升了稳定性和适应性。
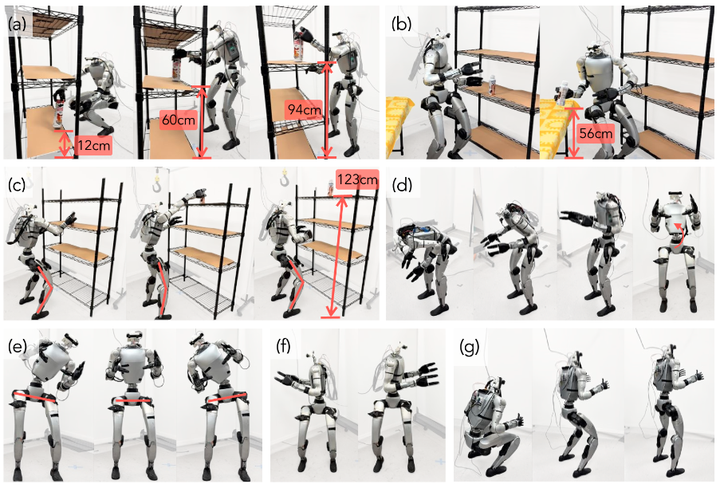
AMO 使类人形机器人实现超灵活全身运动。
AMO 使类人形机器人实现超灵活全身运动。
(a):机器人从不同高度的平台上取放罐头。
(b):机器人从左侧较高的货架上取下瓶子,放到右侧较低的桌子上。
(c):机器人伸展腿脚将瓶子放到较高的货架上。
(d-g):机器人展示了广泛的躯干俯仰、滚转、偏航和高度调整。
(e):机器人利用臀部电机补偿腰部关节限制,以实现更大的滚转旋转。

与两种近期代表性的人形运动模仿工作的比较。灵活度躯干表示机器人能否调整其躯干的朝向和高度以扩大工作空间。任务空间表示末端执行器。无参考部署表示机器人在部署过程中是否需要参考运动。O.O.D.表示工作是否评估了 O.O.D.性能,这是机器人由人类操作员控制且控制信号高度不可预测的典型情况。
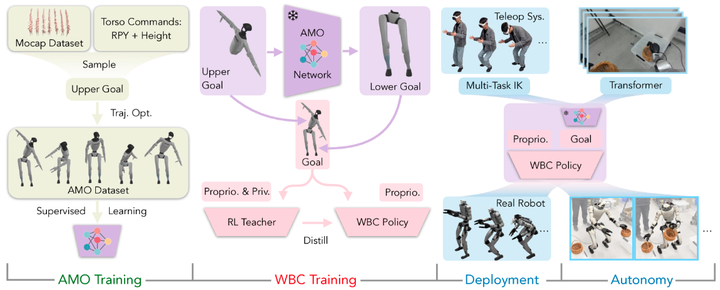
系统概述。
系统分解为四个阶段:
1. 通过轨迹优化收集 AMO 数据集进行 AMO 模块训练;
2. 通过模拟中的师生蒸馏进行 RL 策略训练;
3. 通过逆运动学和重定位进行真实机器人遥操作;
4. 通过 transformer 进行模仿学习(IL)训练真实机器人自主策略。
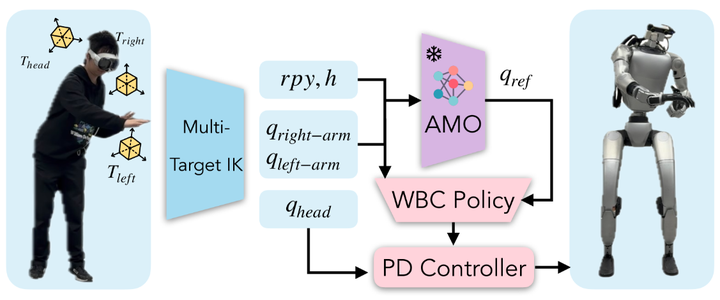
遥操作系统概述。操作员提供三个末端执行器目标:头部、左腕和右腕姿态。多目标逆运动学计算通过同时匹配三个加权目标来得出上层目标和中间目标。中间目标( 𝐫𝐩𝐲,ℎ )被输入到 AMO 并转换为下层目标。
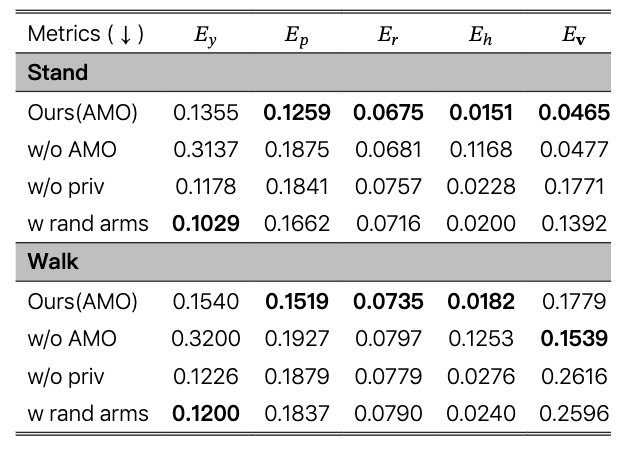
与基线跟踪误差的比较。每个跟踪误差是在 4096 个环境和 500 步中平均得到的。
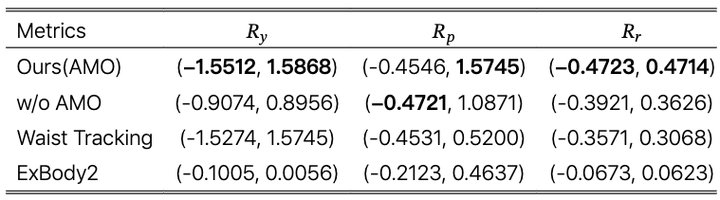
最大躯干控制范围的比较。

躯干方向范围比较
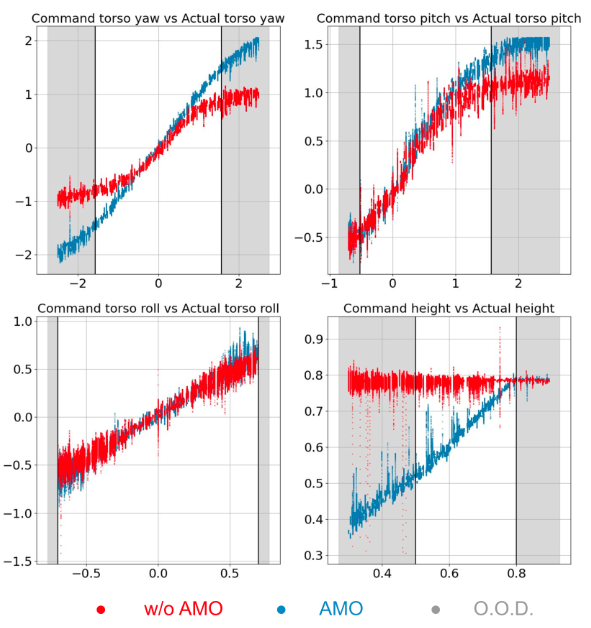
评估分布内(I.D.)和分布外(O.O.D.)跟踪结果。每个图都显示了目标方向与实际指令方向的比较。白色区域表示 I.D.,即指令在轨迹优化和 RL 训练中都使用。灰色区域表示 O.O.D.,即指令在轨迹优化或 RL 训练中都不使用。红色和蓝色曲线分别代表无 AMO 和 AMO 的情况。

纸袋拾取:任务开始于机器人调整其躯干,使其橡胶手与把手对齐。然后,机器人应转身移动到目的地桌子适当的位置,站立不动,并使用其上半身关节协调一致地将手从把手中抽出。

垃圾桶扔掷:任务开始时,机器人弯腰并向左转动上半身以抓取垃圾桶。然后,机器人将腰部向右转动约 90 度,将垃圾桶扔进垃圾桶内。
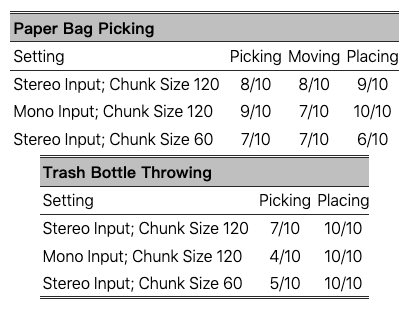
表 IV:每个任务的各个阶段的训练设置和成功率。每个训练设置包括:使用立体(左右眼图像)或单目(单张图像)视觉输入;在动作块分割转换器中使用的块大小。
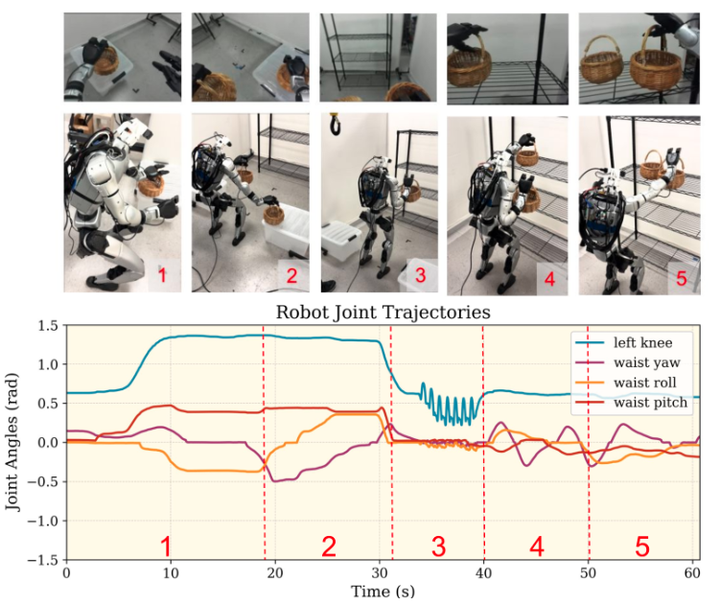
篮子挑选:这是一个复杂的定姿操作任务,同时也需要全身协调。任务开始于机器人从左侧(1)和右侧(2)挑选两个放置在低处且靠近地面的篮子。然后,机器人站立起来,向前移动(3),并将两个篮子放在与眼睛平齐的架子上(4,5)。在自主运行过程中,显示并标注了电机角度轨迹,以匹配相应的阶段。
三、数据集应用场景
AMO 数据集支持多种超灵巧人形机器人全身控制的应用场景,比如:
1、从地面捡起物体:机器人可以通过全身协调运动,从不同高度的平台上捡起物体并放置到其他位置。
2、高架货架取物:机器人可以伸展腿部,将物体放置到高架货架上,展示了出色的全身协调能力。
3、复杂环境中的物体搬运:机器人可以在复杂的环境中,通过全身运动调整姿态,完成物体的搬运任务。
4、自主任务执行:通过模仿学习,机器人可以自主完成复杂的全身控制任务,例如在不同高度的平台上进行物体的抓取和放置



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









