







本文主要介绍如何将Prometheus监控接入到Sanic框架中,并监控QPS、平均延时、P99、请求成功率等指标。
一、安装sanic-prometheus
安装指令:
pip install sanic_prometheus二、公开的指标
目前sanic-prometheus提供四个指标:
- sanic_request_count - 请求总数(标签:方法、端点、状态)
- sanic_request_latency_sec - 以秒为单位的请求延迟(标签:方法,端点)
- sanic_mem_rss_bytes - 进程使用的常驻内存(以字节为单位)
- sanic_mem_rss_perc - 运行 Sanic 的进程使用的总物理内存的百分比
三、启用监控
找到sanic app创建的地方,按照说明添加一两行代码即可,有两种方案,如下:
方案一(推荐)
from sanic import Sanic
from sanic_prometheus import monitor
app = Sanic()
...
if __name__ == "__main__":
monitor(app).expose_endpoint() # adds /metrics endpoint to your Sanic server
app.run(host="0.0.0.0", port=8000)方案二
from sanic import Sanic
from sanic_prometheus import monitor
app = Sanic()
...
if __name__ == "__main__":
monitor(app).start_server(addr="0.0.0.0", port=8000)
四、多进程模式
如果 Sanic 是用多进程模式,会影响指标数据的收集。需要做一些调整。
为了从多个worker收集指标,请创建一个目录并将 prometheus_multiproc_dir 环境变量指向它。在启动服务之前确保目录为空:
rm -rf /path/to/your/directory/*
env prometheus_multiproc_dir=/path/to/your/directory python your_sanic_app.py【备注】上面方案二的代码方式,在多进程模式下不适用,建议用方案一的方式。
五、Prometheus 查询示例
-
过去 30 分钟的平均延迟:
rate(sanic_request_latency_sec_sum{endpoint='/your-endpoint'}[30m]) /
rate(sanic_request_latency_sec_count{endpoint='/your-endpoint'}[30m])-
请求延迟的第 95 个百分位:
histogram_quantile(0.95, sum(rate(sanic_request_latency_sec_bucket[5m])) by (le))-
过去 10 分钟的物理内存使用百分比:
rate(sanic_mem_rss_perc[10m])六、实际项目中的例子
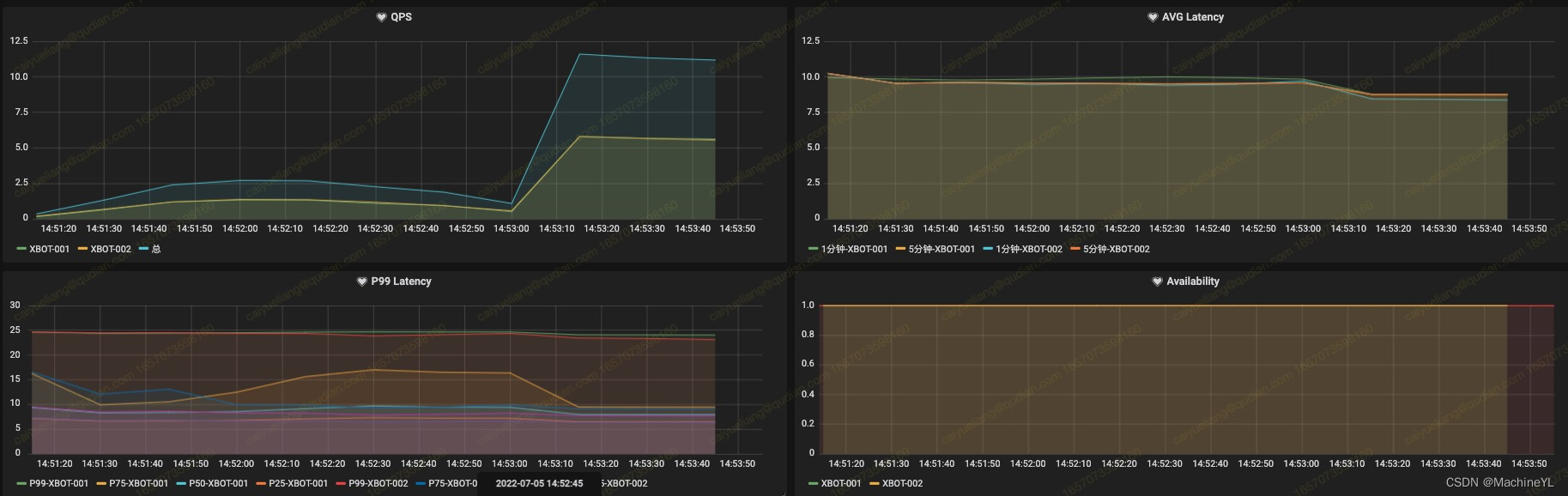
最终是在Grafana平台上展示监控指标,监控代码如下。
- 最近1分钟,请求 “/webhooks/rest/webhook” 接口的QPS
sum(rate(sanic_request_count_total{endpoint="/webhooks",method="POST",raw_url="b'/webhooks/rest/webhook'"}[1m]))- 最近1分钟,请求 “/webhooks/rest/webhook” 接口的平均延时
rate(sanic_request_latency_sec_sum{endpoint='/webhooks',method="POST",raw_url="b'/webhooks/rest/webhook'"}[1m])
/ rate(sanic_request_latency_sec_count{endpoint='/webhooks',method="POST",raw_url="b'/webhooks/rest/webhook'"}[1m])- 最近1分钟,请求 “/webhooks/rest/webhook” 接口的P99延时
histogram_quantile(0.99, sum(rate(sanic_request_latency_sec_bucket{endpoint="/webhooks",method="POST",raw_url="b'/webhooks/rest/webhook'",instance="106.15.67.196:1001"}[1m])) by (le))- 最近1分钟,请求 “/webhooks/rest/webhook” 接口的成功率
rate(sanic_request_count_total{endpoint="/webhooks",http_status="200",raw_url="b'/webhooks/rest/webhook'"}[1m])
/ ignoring(http_status,instance,method,job)sum(rate(sanic_request_count_total{endpoint="/webhooks",raw_url="b'/webhooks/rest/webhook'"}[1m])) by (endpoint, raw_url)七、Grafana展示结果


















 4293
4293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









