







学习一下unordered_map的用法,上海区域赛前才第一次见这个东西,看到和map用法一样自信觉得能用,然而场上卡住了,现在滚过来学一下orz【虽然事后发现G题根本不需要用这个东西。
学过哈希的都很容易理解离散化,无非就是数据过大开不了那么大的数组时,但其实中间有很多浪费掉的空间,那么映射到另一个数组中就可以了。
以前常用的c++离散化是
// a[i] 为初始数组,下标范围为 [1, n]
// len 为离散化后数组的有效长度
std::sort(a + 1, a + 1 + n);
len = std::unique(a + 1, a + n + 1) - a - 1;
// 离散化整个数组的同时求出离散化后本质不同数的个数。
std::lower_bound(a + 1, a + len + 1, x) - a; // 查询 x 离散化后对应的编号
而unordered_map是一个内部实现了哈希表的数据结构。其查找效率是O(1)的。
那么先上一个基础应用例题:https://ac.nowcoder.com/acm/contest/5158/H
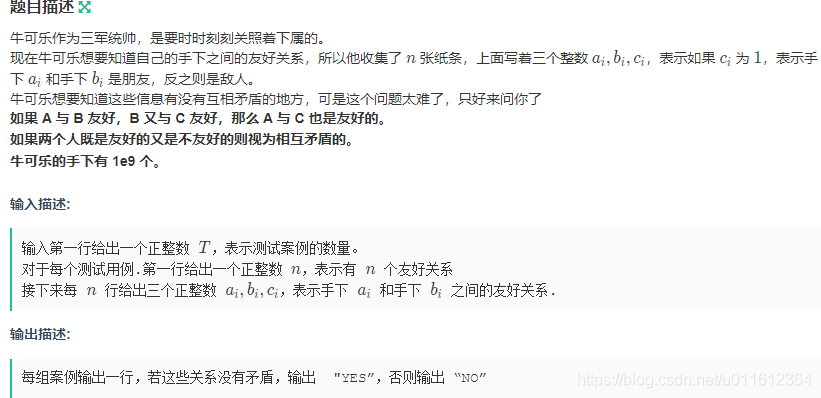
明显并查集,但是1e9,这么大肯定离散化,那就用一下这个unordered_map代替并查集中的pre数组就ok
#include<bits/stdc++.h>
using namespace std;
unordered_map<int ,int > pre;
int find(int a)
{
if(pre[a] == 0)
return a;
else
return pre[a] = find(pre[a]);
}
void Union(int a,int b){
int m = find(a);
int n = find(b);
pre[m] = n;
return ;
}
int main()
{
cin.tie(0),ios::sync_with_stdio(false);
int t;
cin>>t;
while(t--) {
pre.clear();
int flag = 1;
int n,a,b,c;
cin >> n;
for(int i = 0 ;i < n; i++) {
cin>>a>>b>>c;
int m = find(a);
int n = find(b);
if(c == 1 ){
if( m!=n && a !=m &&b != n){
flag = 0;
break;
}
else
Union(a,b);
}
else{
if( m == n){
flag = 0;
break;
}
}
}
if(flag == 0)
cout<<"NO"<<endl;
else
cout<<"YES"<<endl;
}
system("pause");
return 0;
}
未完持续考完试继续写















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









