









ChatGLM反卷总局
https://www.bilibili.com/video/BV1hu4y147EW/?spm_id_from=333.337.search-card.all.click&vd_source=b3aaf2cdc79875f83fdd149e1178ce26
容器
镜像:registry.cn-shanghai.aliyuncs.com/fjzj/chatglm_fjzj:v6
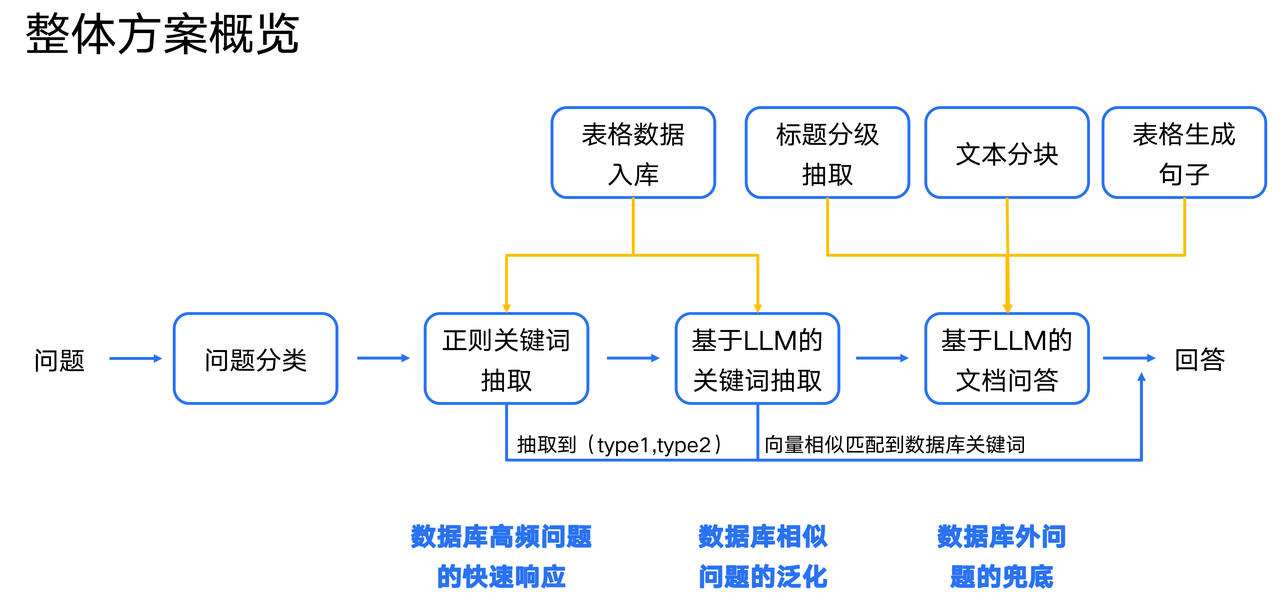
总体架构
1、基于正则分类与抽取关键词的方式,实现数据库字段高频问题的快速回答
2、基于LLM抽取关键词的方式,实现与数据库字段相似问题的泛化
3、基于LLM文档问答的方式,实现数据库字段外问题的兜底
亮点:
1、使用In-Context Learning的方式抽取关键词,无需微调,保留大模型的通用能力
2、通过分块文本增加标题信息,以及LLM关键词的召回增强的方法,显著提升回答公司综合问题的效果
表格数据抽取
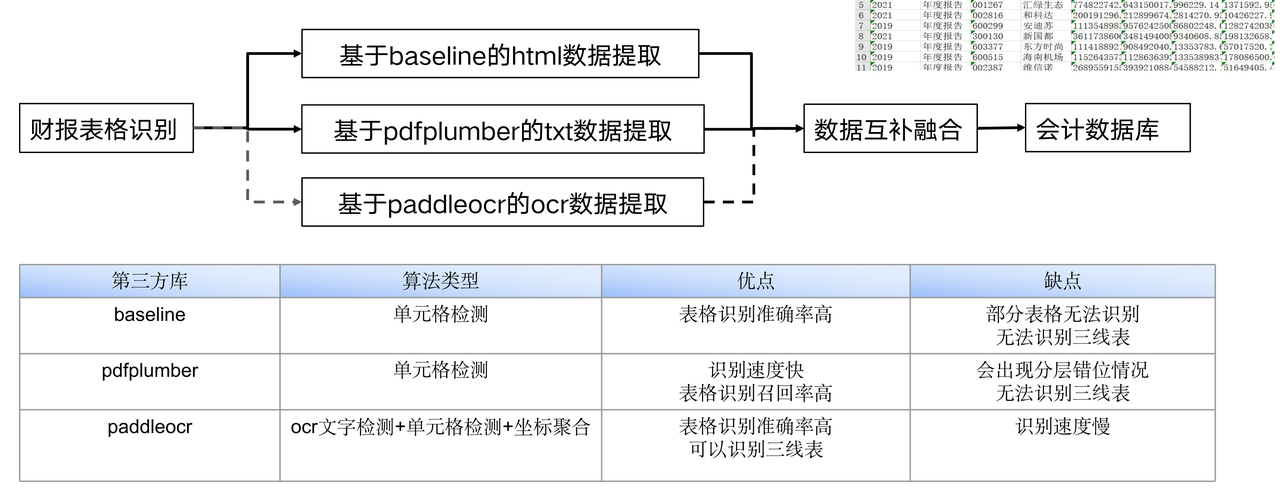
process_data:pdf2excel
A榜:2000条数据
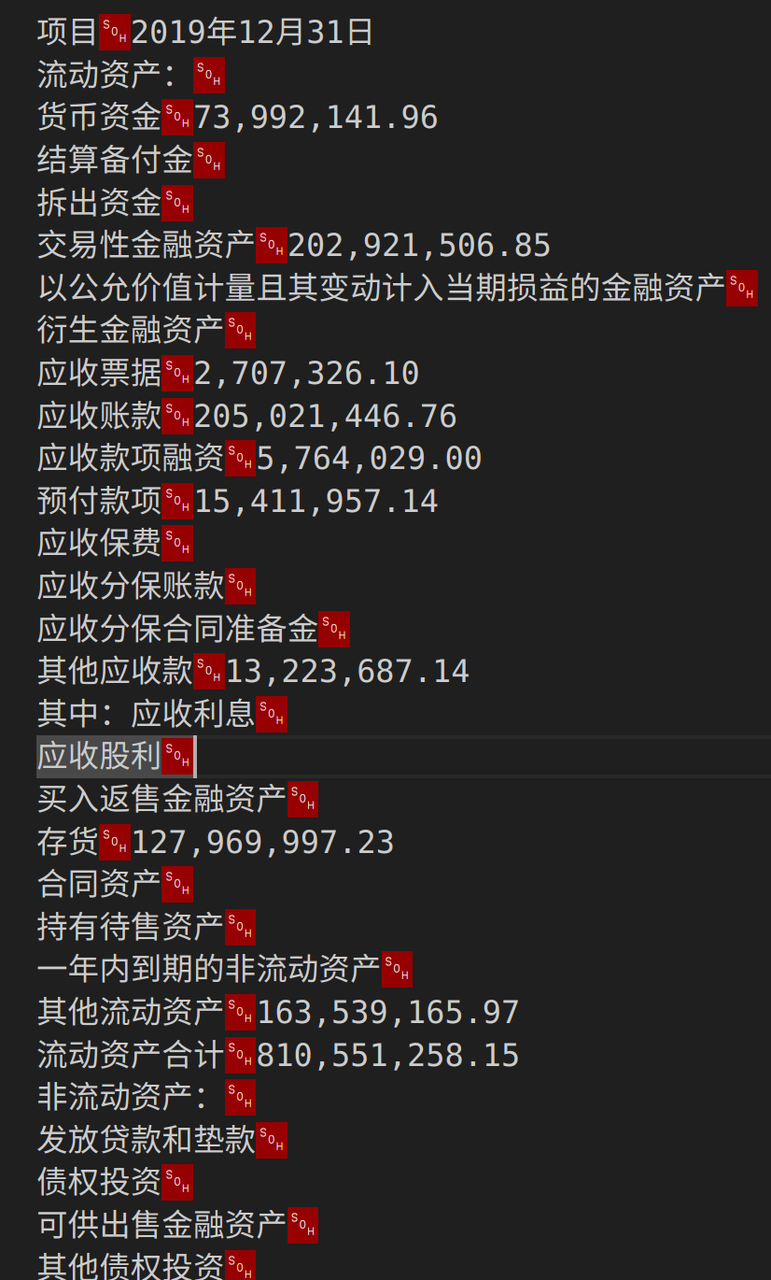
txt_extract_info: go
结果:

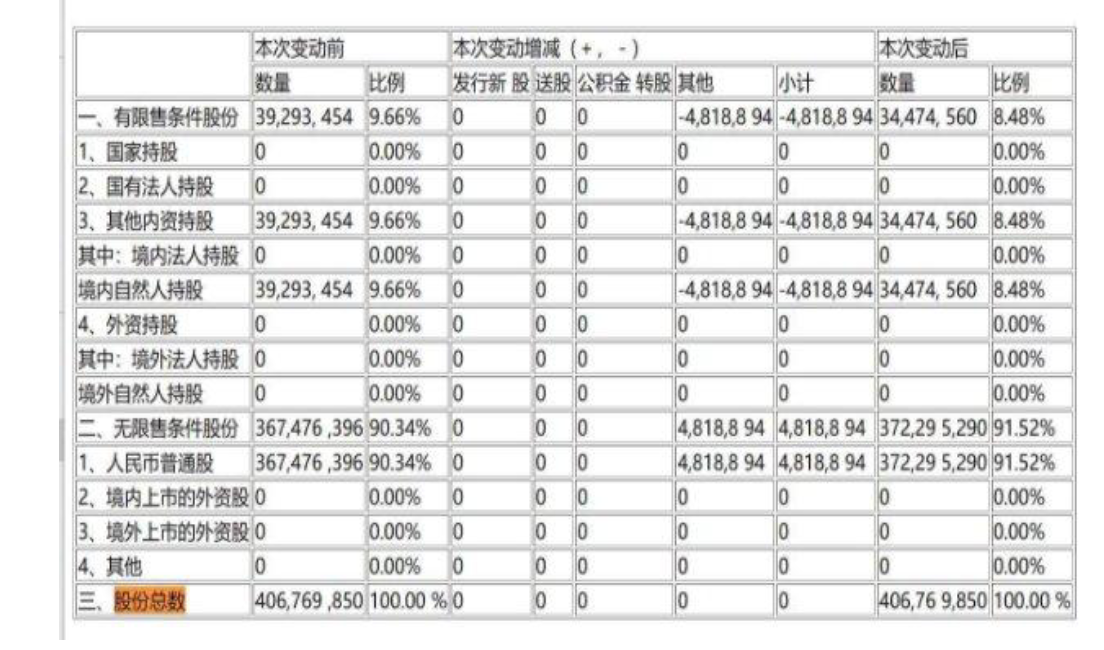
baseline(html): html_extract_info
结果:
combine_html_txt:
根据官方txt抽取出的报表和抽取出的html,输出balance,balance_static,cashFlow,profit数据
extract_people.go:
提取人员信息
extract_baseinfo.go
transfer_to_excel:把csv转化为excel
process:数据预处理阶段
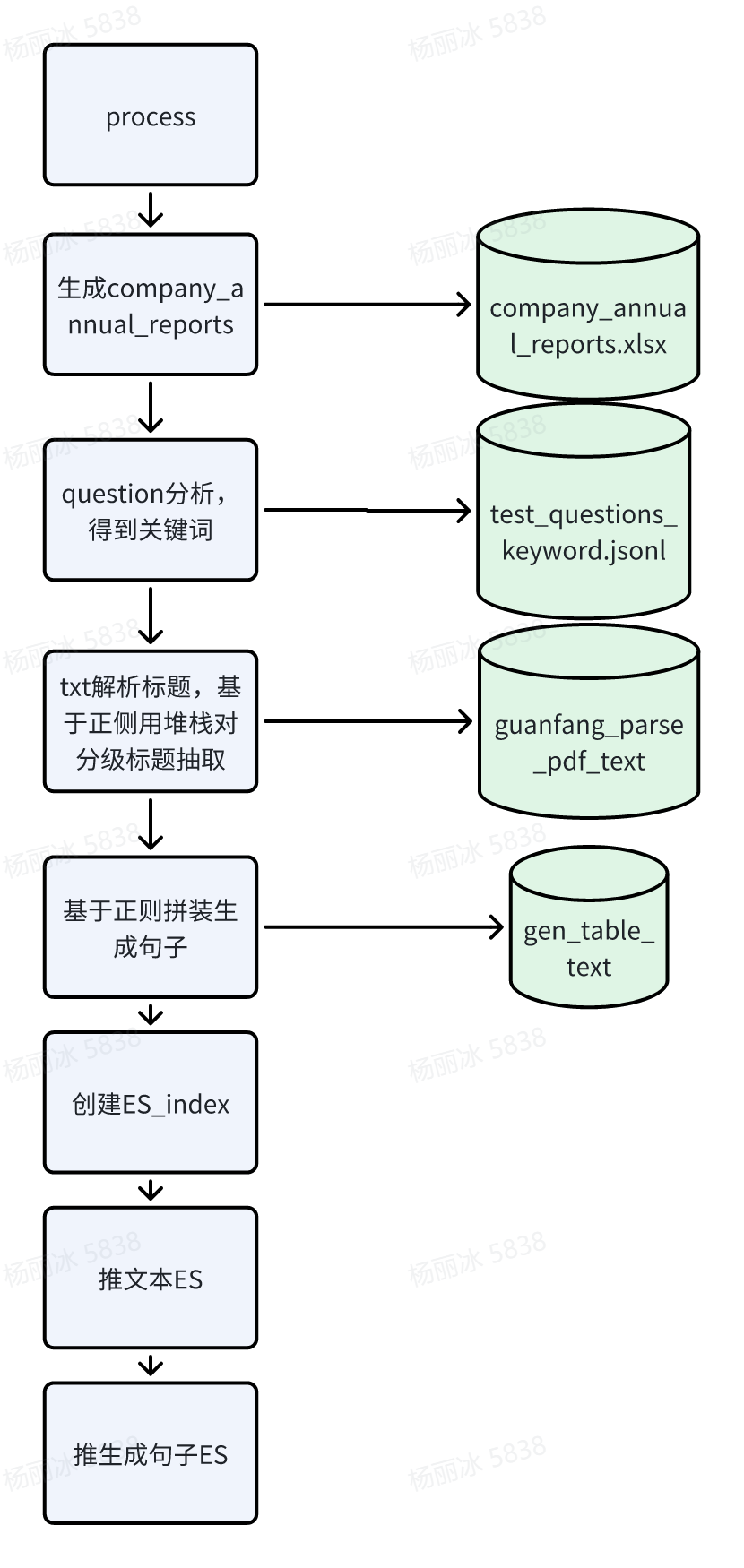
intial_company_excel:生成company_annual_reports
保存到:company_annual_reports_path = ./data/company_annual_reports.xlsx
question_analyse:正则化处理
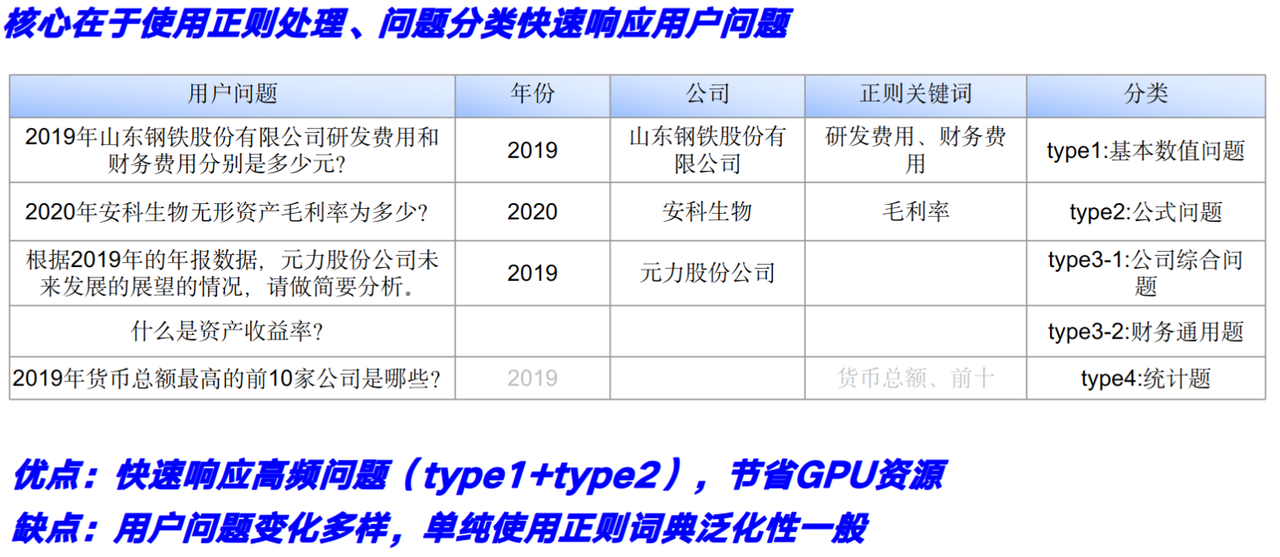
问题分类:
- calculate:type 1 数值计算题 如在保留两位小数的情况下,请计算出金钼股份2019年的流动负债比率
- com_info: 如光云科技2021年年报中提及的投资收益增长率具体是什么?
- com_normal: 如根据青岛港国际股份有限公司2019年的年报数据,能否简要介绍公司报告期内破产重整相关事项的详情。
- normal:type 4 财务通用题 如无形资产是指什么?
对问题进行分类,基本上是正则+判断+LLM判断,对问题的内容做了归一化,计算公式中明确了召回数据,用若干字典配置。
正则匹配到关键词就直接查表输出
- 提取所有公司名,形成正则所需词典
- 对问题进行后续精细化提取
- 年份提取
- 公司提取
- 问题分类
- 关键词提取
- 元素定位
1. 判断出是需要计算的题
2. 识别出是公式
3. 普通项目抽取
保存到keyword_question_path中:./data/test_questions_keyword.jsonl

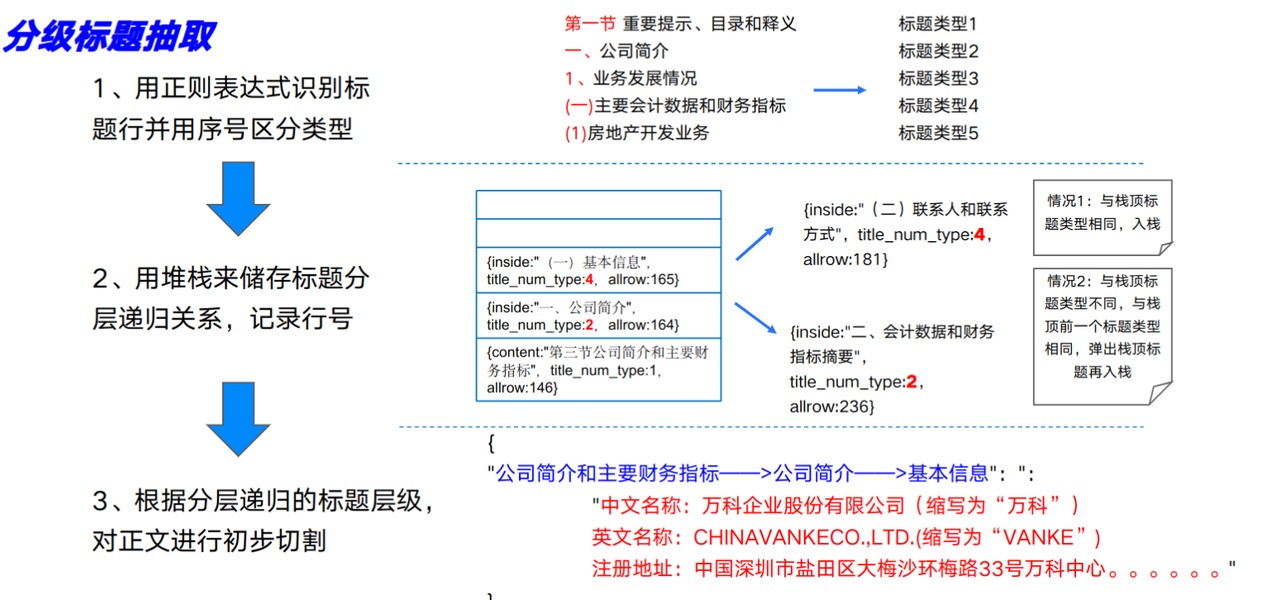
extra_title:txt解析标题 分级标题抽取
保存到parse_title_text_path = ./data/guanfang_parse_pdf_text中
- 识别出所有的标题,并且生成递归关系
- 根据递归关系,生成字典,key是标题名,value是对应的内容列表

gen_table_text: 生成句子
保存到:gen_table_text_path = ./data/gen_table_text
- 找到表格
- 获取标题
- 抽取表格
最终保存:
final_hebing_result[‘合并利润表’] = hebing_result
final_hebing_result[‘合并资产负债表’] = zichan_result
final_hebing_result[‘合并现金流量表’] = liuliang_result
final_hebing_result[‘公司信息’] = info_result
final_hebing_result[‘员工信息表’] = result
创建es索引

- 使用 configparser 模块读取配置文件的信息,包括 Elasticsearch 的连接信息和索引名称。
- 创建 Elasticsearch 的实例,即连接 Elasticsearch 服务器并设置连接参数。
- 定义索引的设置和映射,即索引包含的字段和字段的类型,以及分析器的设置。其中,“fields” 和 “analyzer” 指定了分析器类型,“type” 定义了字段的数据类型,如 “text” 表示一个长文本字段,可以参与全文搜索,而 “keyword” 表示一个短文本字段,不支持分词,适用于精确的字段匹配。
- 使用 Elasticsearch 的 API 创建索引,指定需要创建的索引名称和索引的设置。
推文本ES:
initial_text_es():
RecursiveCharacterTextSplitter
可以将一段大文本按照指定的块大小进行分割。它使用一组字符来完成此任务,默认提供给它的字符包括[“\n\n”, “\n”, " ", “”]。
推生成句子ES
predict:
代码会先将问题中的一些特殊符号去掉,然后判断是否包含股票名称和年份,以及问题类型是否为普通问题。如果包含股票名称和年份且问题类型不是普通问题,代码会尝试计算股票指标,并将结果作为回答。如果问题中包含“增长率”且问题类型不是普通问题,代码会尝试从财务报表中获取相关数据,并将结果作为回答

基于LLM的文档问答

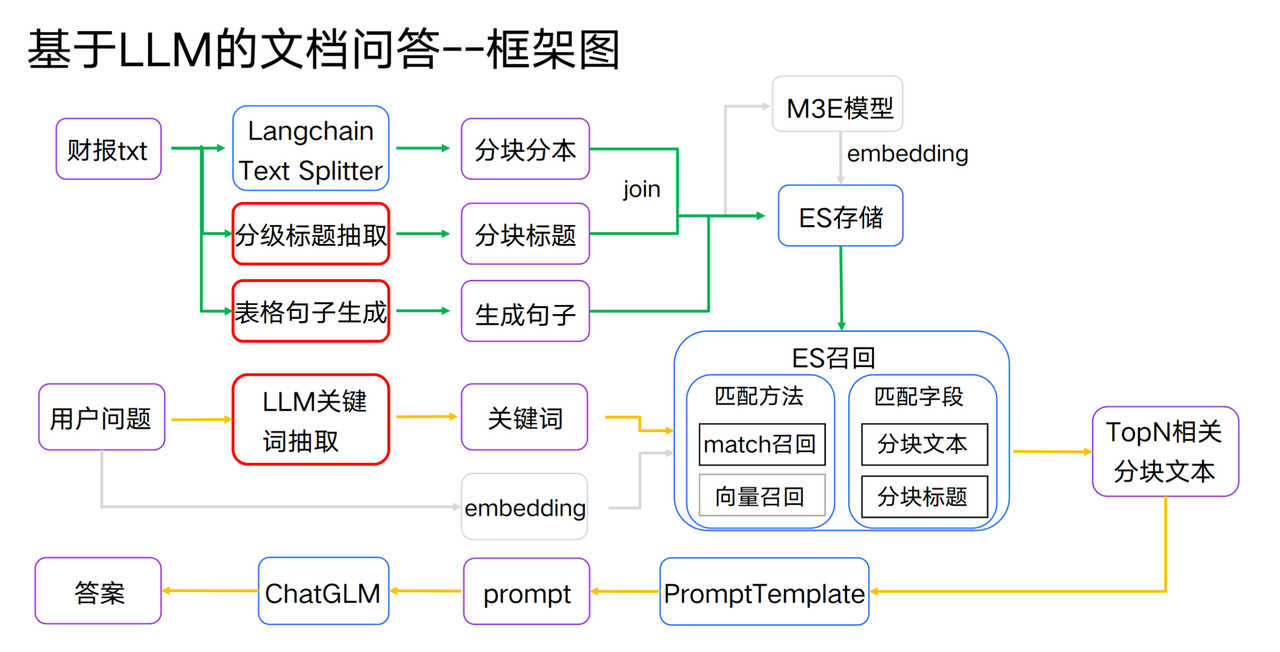
文本分块:使用Langchain分块, 每个分块的开头添加抽取的分级标题
基于LLM召回增强

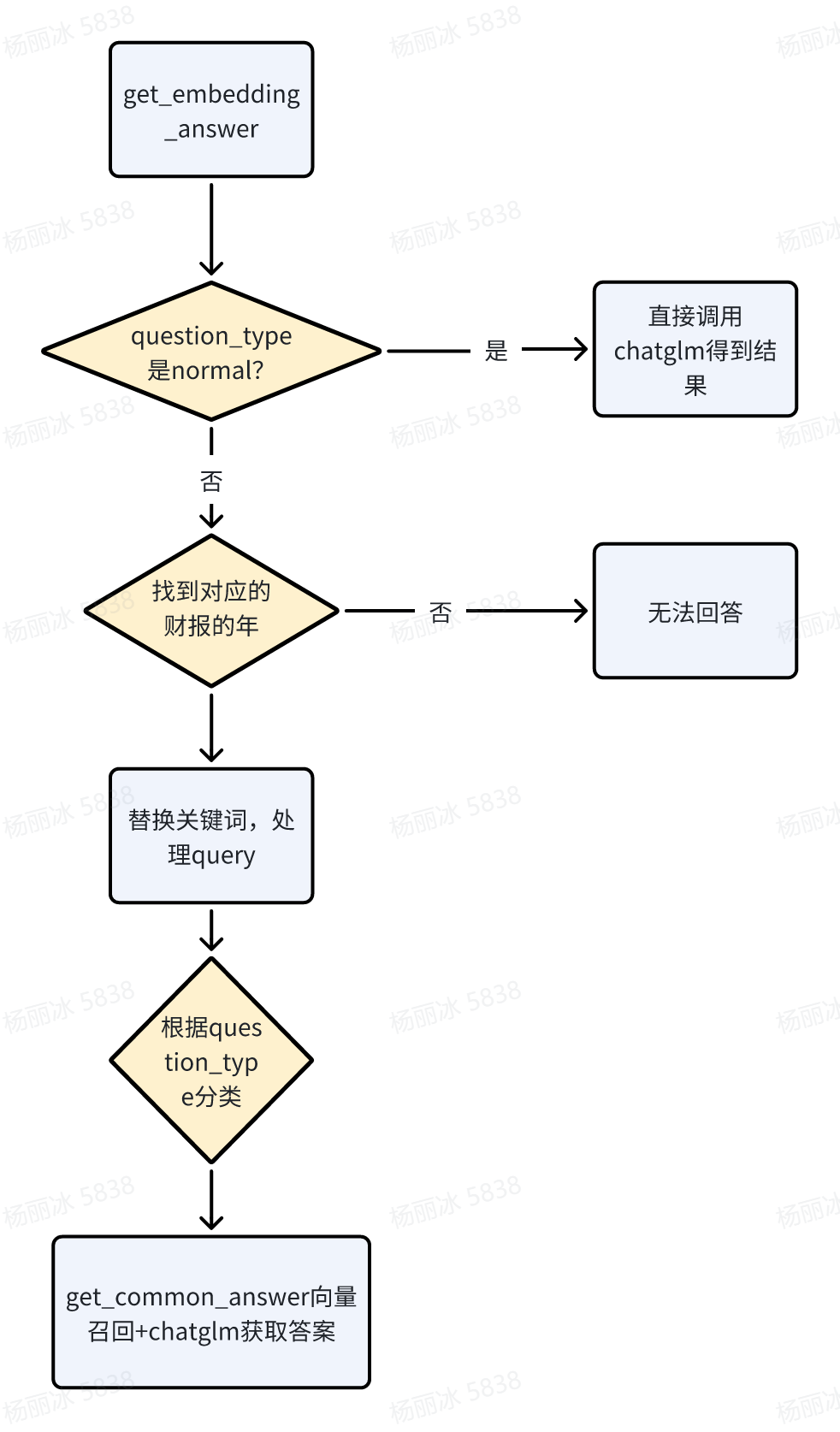
get_common_answer:用最普通的方式获取答案(向量召回+chatglm)














 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









