






逻辑回归与线性回归的联系与区别
- 线性回归是回归问题,预测连续型变量,其取值可以在在,0, 1之外。
- 逻辑回归是分类问题,属于某类的概率,也可看做是回归的分类问题。
参数估计:
线性回归中使用的是最小化平方误差损失函数,对偏离真实值越远的数据惩罚越严重。假如使用线性回归对{0,1}二分类问题做预测,则一个真值为1的样本,其预测值为50,那么将会对其产生很大的惩罚,这也和实际情况不符合,更大的预测值说明为1的可能性越大,而不应该惩罚的越严重
逻辑回归使用对数似然函数进行参数估计,使用交叉熵作为损失函数,对预测错误的惩罚是随着输出的增大,逐渐逼近一个常数,这就不存在上述问题了
逻辑回归的原理
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
逻辑回归损失函数推导及优化
逻辑回归选择 Sigmoid 函数作为预测函数, 图像如下, g (x) =
1
1
+
e
−
x
\frac{1}{1 + e^-x}
1+e−x1

当x = 0的时候, g(x) = 0.5
当x < 0的时候, g(x) < 0.5, x越小, g(x)越接近0
当x > 0的时候, g(x) > 0.5,x越大, g(x)越接近1
假设令z(x)=θTx , 则g(z) = g(θTx ) =
1
1
+
e
−
(
θ
T
x
)
\frac{1}{1 + e^-(θ^Tx)}
1+e−(θTx)1
可以理解成sigmoid函数将我们的预测值转化为一条上界为1, 下界为0的曲线
损失函数
我们的目标是尽可能减少误分类的点。
就是统计将0分为1, 将1分为0的点。
损失函数的本质就是,错的离谱的点,给的惩罚重一点, 错的没那么离谱的点, 给的惩罚轻一点。
所以我们定义逻辑回归的代价函数为:
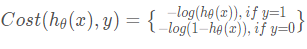
试着思考一下, 在y=1的情况下,随着h(x)越来越大,预测值越接近1。 所以我们的惩罚就要相对轻一点。
看y=1的情况, -log(h(x))是一个减函数,满足条件
y=0的情况下, -log(1 - h(x))是一个增函数, 满足条件。
至于为什么取自然对数为底的对数,是因为sigmoid函数有个e, 去自然对数为底的对数,方便处理这个e
接下来,为了方便计算,我们会考虑将上述两条式子合并成一条。
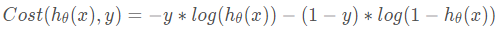
那么损失函数就是
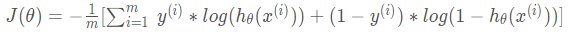
首先我们对sigmoid函数进行求导。
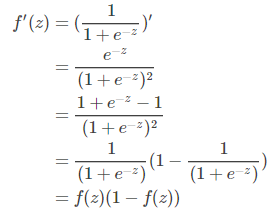
接下来我们对θ1进行求导。
前面的1/m 以及求和符号不影响求导。 所以我们只看里面。
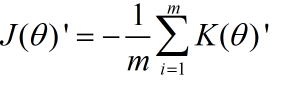
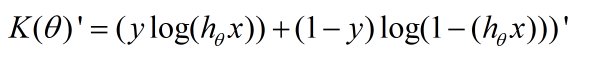
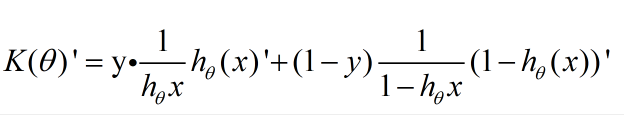
这里应用刚才算出来的sigmoid函数求导结果。
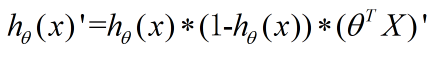
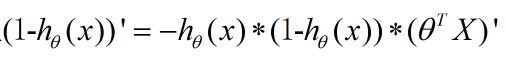
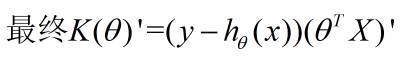
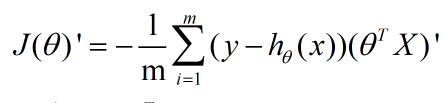
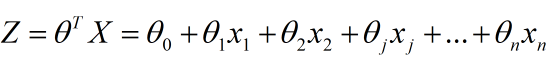
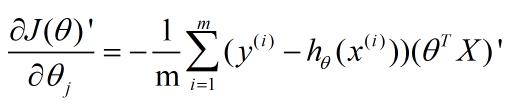
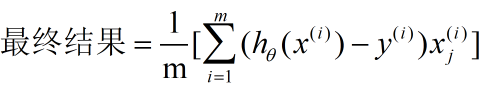
然后就可以应用梯度下降算法啦。 找到最优解。
正则化与模型评估指标
为了避免过拟合问题,又不得不提到正则化了。
楼主还没搞懂这个问题, 请大家移步这个帖子
https://blog.csdn.net/whuhan2013/article/details/53454811
逻辑回归的优缺点
优点:1)适合需要得到一个分类概率的场景。2)计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。它可以应用于分布式数据,并且还有在线算法实现,用较少的资源处理大型数据。3)LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。(严重的多重共线性则可以使用逻辑回归结合L2正则化来解决,但是若要得到一个简约模型,L2正则化并不是最好的选择,因为它建立的模型涵盖了全部的特征。)
缺点:1)容易欠拟合,分类精度不高。2)数据特征有缺失或者特征空间很大时表现效果并不好。
样本不均衡问题解决办法
- 增加数据集。
- 重新采样(整体)
- 用不同的评判指标。
比如,当负样本很小的时候,准确率其实不适用,(因为所有都预测正样本,准确率其实也有可能很高。模型需要的是找出负样本) - 在已有样本的情况下重新欠采样。
总观测 = 1000
欺诈性观察 = 20
非欺诈性观察 = 980
事件发生率 = 2%
这种情况下我们复制 20 个欺诈性观察 20 次。
非欺诈性观察 = 980
复制少数类观察之后的欺诈性观察 = 400
过采样之后新数据集中的总体观察 = 1380
欠采样之后新数据集的事件发生率 = 400/1380 = 29%
sklearn参数
penalty : str, ‘l1’ or ‘l2’, default: ‘l2. 默认正则化用l2范数
‘newton-cg’, ‘sag’ and ‘lbfgs’ 只支持L2范数
dual : bool, default: False. 默认False
对偶或者原始方法。Dual只适用于正则化相为l2 liblinear的情况,通常样本数大于特征数的情况下,建议使用False
tol : float, default: 1e-4 默认0.0001
停止迭代的条件
C : float, default: 1.0 默认1
λ的倒数,必须为正, 数值越小, 代表更强的正则化
fit_intercept:默认为True
是否存在截距,默认存在
intercept_scaling : float, default 1. 默认1
只有在solver == liblinear 且有截距时有用。
class_weight : dict or ‘balanced’, default: None
默认为None;与“{class_label: weight}”形式中的类相关联的权重。如果不给,则所有的类的权重都应该是1。
random_state
整型,默认None;当“solver”==“sag”或“liblinear”时使用。在变换数据时使用的伪随机数生成器的种子。
solver
{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’},默认: ‘liblinear’;用于优化问题的算法。
对于小数据集来说,“liblinear”是个不错的选择,而“sag”和’saga’对于大型数据集会更快。
对于多类问题,只有’newton-cg’, ‘sag’, 'saga’和’lbfgs’可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
max_iter
最大迭代次数,整型,默认是100;
multi_class : str, {‘ovr’, ‘multinomial’, ‘auto’}, default: ‘ovr’
字符串型,{ovr’, ‘multinomial’},默认:‘ovr’;如果选择的选项是“ovr”,那么一个二进制问题适合于每个标签,否则损失最小化就是整个概率分布的多项式损失。对liblinear solver无效。
##########观参数有感,逻辑回归还有很多东西要了解。路漫漫其修远兮。















 7853
7853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









