








简介
在csdn上发现了一个http://blog.csdn.net/maotoula/article/details/7680716 ,上面有分析对于一个车牌的识别过程。于是跟着这个流程分析,自己利用opencv 来代码实现了一遍。
图像预处理
首先拿到如下的车牌照片:

接着对它进行一些预处理,这里做的是简单的将它灰阶二值化:
uchar* ptr = img_2.ptr(0); /********************************************************************/ for(int i = 0; i < width; i++){ for(int j=0;j<height;j++){ s = cvGet2D(&pI,i,j); int grayScale = (int)(s.val[0]*0.299 + s.val[1]*0.587 + s.val[2]*0.114); ptr[i*height+j] = grayScale; } } cv::namedWindow("img_2"); cv::imshow("img_2",img_2); /*********************************************************************/ for(int i = 0; i < width; i++){ for(int j=0;j<height;j++){ if(ptr[i*height+j] > 125){ ptr[i*height+j] = 255; }else{ ptr[i*height+j] = 0; } } }
也就是用之前讲过的算法,先RGB通道图片转化为灰阶图片,然后在利用设置的阀值125,将图片转化为2值图像。生成结果如下:
字符分割
第二步是在二值图像中将其中的7个字符都单独分离出来。我们的测试照片现在已经变成了字体白色,背景黑色,然后上下还有4个白色的铆钉。 因此我们需要做的是消除掉4个铆钉,然后将7个字符单独分离出来。 1、使用的办法也是如blog所示的,首先将图片水平扫描啊,然后将图片垂直扫描。如图片所示中,我们可以看到,图片中的铆钉所在的行中,它们所在的像素是最少的。 和真实数字之间有着很明显的区别。所以,可以做一个阀值判断,在水平扫描的时候。从头开始,直到像素点多于20的时候,表示真正是字符开始了。然后直到某行像素 低于20时候,表示字符结束了。
int real_width1, real_width2; int flag_width[width]; for(int i = 0; i < width; i++){ for(int j=0;j<height;j++){ s = cvGet2D(&pI_2,i,j); if(s.val[0] == 255){ flag += 1; } } flag_width[i] = flag; flag = 0; } for(int i=0;i<width;i++){ if(flag_width[i] > 20){ real_width1 = i; break; } } for(int i=width-1;i>0;i--){ if(flag_width[i] > 20){ real_width2 = width - i; } } printf("real_width1:%d,real_width2:%d\n",real_width1,real_width2);
这样最后获得的real_width1和real_width2就表示是字符真正行开始和结束的位置,因此,字符开始和结束的纵坐标也就确定了。
2、接着找到每一个字符开始和结束的横坐标。由于每个字符之间是分离开的,所以我们可以直接扫描每一列,当发现有255的像素时候,就是第一个字符开始位置, 一只到某一列没有255像素出现时候,表示是第一个字符结束位置,和下一个字符开始扫描的位置,直到所有的7个字符扫描结束。
int real_address[7][2]; for(int j=0;j<height;j++){ flag = 0; for(int i = real_width1; i < real_width2; i++){ s = cvGet2D(&pI_2,i,j); if(s.val[0]==255){ if(real_height1 == -1){ real_height1 = j; } flag = 1; break; } } if((real_height1 != -1) && (flag ==0)){ real_height2 = j; if(real_height2 - real_height1 < 10){ real_height1 = -1; flag = 0; continue; } real_address[record_number][0] = real_height1; real_address[record_number][1] = real_height2; real_height1 = -1; real_height2 = 0; record_number += 1; } } for(int i=0; i<7; i++){ printf("height1[%d]:%d,height2[%d]:%d\n",i, real_address[i][0], i, real_address[i][1]); }
这样,7个字符的纵坐标开始和结束位置就都存在了数组real_address中。然后,我们把它们显示出来:
void wordshow(int number){ cv::Mat word; int word_width = real_width2 - real_width1; int word_height; uchar* ptr_word; char str[2]; sprintf(str, "%d", number); word_height = real_address[number][1] - real_address[number][0]; word = cv::Mat(word_width, word_height, CV_8UC1, 1); ptr_word = word.ptr(0); for(int i = real_width1; i < real_width2; i++){ for(int j=real_address[number][0]; j<real_address[number][1]; j++){ int tmp; s = cvGet2D(&pI_2,i,j); tmp = (int)s.val[0]; ptr_word[(i-real_width1) * word_height + (j - real_address[number][0])] = tmp; } } cv::namedWindow(str); cv::imshow(str,word); }
显示出来的字符分割结果如下:

代码下载如下:http://download.csdn.net/detail/u011630458/8414317
归一化处理
之后,需要对分割出来的7个字符图片做归一化处理,简单的说,就是要将这7张图片从新设置大小为一样的。我这里设置为了40X20 使用的是opencv自带的函数cvResize。
.......... word2 = cv::Mat(40, 20, CV_8UC1, 1); IplImage pI_3 = word; IplImage pI_4 = word2; cvResize(&pI_3, &pI_4, 1); .........
这样就将原来的word图像复制一份到了word2,并设置为了40x20到大小。这样做的目的是方便之后进行模板匹配。我使用的模板图像就是40x20的。
字符识别
这里使用模板匹配来做字符识别,使用的函数是opencv官方教程中提到过的SSIM,这个函数返回图像的结构相似度指标。这是一个在0-1之间的浮点数(越接近1, 相符程度越高)。 代码中,在文件夹match_pic下,存放在用来匹配的模板图片。然后将分割出来的7个字符,每一个都使用getMSSIM来对所有的模板图片进行一一匹配,选择出匹配 相似度最高的图片,表示为对应的字符。 最后识别出来的结果如下:
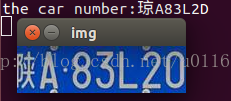
代码下载位置:http://download.csdn.net/detail/u011630458/8414375
总结
如果所示,该方法识别率低下。而且中间使用字符提取的方式太简单和无法通用,所以。。只能作为基本的练习。。















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









