







VDSR
SRCNN存在三个问题需要进行改进:1、依赖于小图像区域的内容;2、训练收敛太慢;3、网络只对于某一个比例有效。
VDSR模型主要有以下几点贡献:1、增加了感受野,在处理大图像上有优势,由SRCNN的13*13变为41*41。2、采用残差图像进行训练,收敛速度变快,因为残差图像更加稀疏,更加容易收敛(换种理解就是lr携带者低频信息,这些信息依然被训练到hr图像,然而hr图像和lr图像的低频信息相近,这部分花费了大量时间进行训练)。3、考虑多个尺度,一个卷积网络可以处理多尺度问题。
网络结构如下图所示:
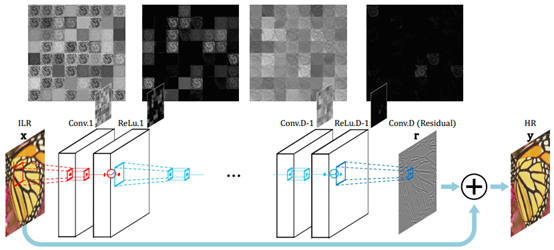
训练的策略:1、才用残差的方式进行训练,避免训练过长的时间。2、使用大的学习进行训练。3、自适应梯度裁剪,将梯度限制在某一个范围,本文采用自适应梯度方法,将梯度限制在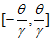

对于边界问题,由于卷积的操作导致图像变小的问题,本文作者提出一个新的策略,就是每次卷积后,图像的size变小,但是,在下一次卷积前,对图像进行补0操作,恢复到原来大小,这样不仅解决了网络深度的问题,同时,实验证明对边界像素的预测结果也得到了提升。
参考:
论文全名:Accurate Image Super-Resolution Using Very Deep Convolutional Networks
下载地址:https://pan.baidu.com/s/1ge2pCWF
code:https://github.com/huangzehao/caffe-vdsr















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









