






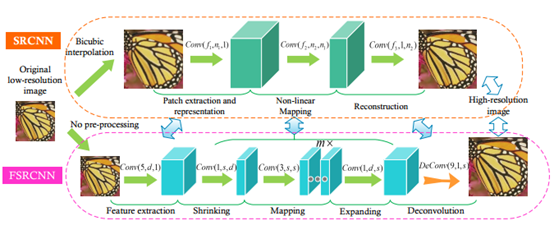
FSRCNN
主要的目的是加速之前的SRCNN模型。重新设计SRCNN结构,主要 在三个方面:一是使用了一个解卷积层在最后,这个作用是从没有差值的低分辨率图像直接映射到高分辨率图像。第二是,重新改变输入特征维数。第三是使用了更小的卷积核但是使用了更多的映射层。
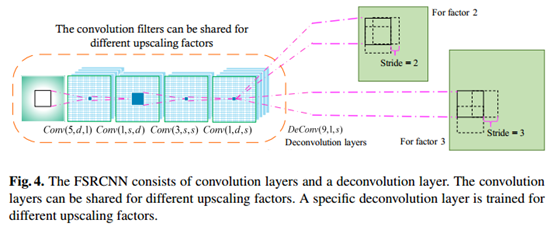
针对SRCNN中有两点限制了速度。第一点,低分辨率图像需要上采样(通过三次插值);第二点,非线性映射步骤,需要缩减参数加快速度。对于第一个问题采用解卷积层代替三次插值,针对第二个问题,添加萎缩层和扩张层,并将一个大层用一些小层(卷积核大小是3*3)来代替。整个网络结构类似于漏斗的形状,中间细两端粗。这个网络不仅仅速度快,而且不需要更改参数除了最后一个解卷积层。
三个贡献:1、设计漏斗结构的卷积网络,不需要预处理操作2、速度提升3、训练速度快,只要改变最后的解卷积层就可以。
由于SRCNN需要先三次插值到HRsize,所以复杂度与HRsize有关。
主要分为5个部分。特征提取:SRCNN中第一层感受野是9*9,由于这里不用插值,一次用5*5就好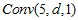
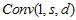



损失函数为

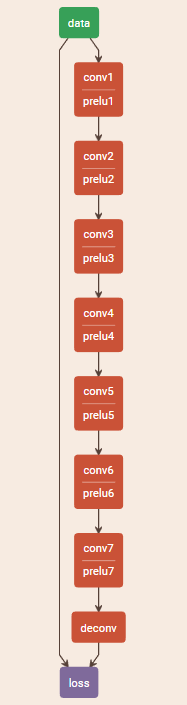
结构图:
实验结果:

参考:
https://arxiv.org/pdf/1608.00367v1.pdf Accelerating the Super-Resolution Convolutional Neural Networks (ECCV 2016)















 5614
5614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









