







一、将list转换为string
list1=[1,'ab','c']
list1_str ="".join([str(x) for x in list1])
运行结果:

二、将string转换为list
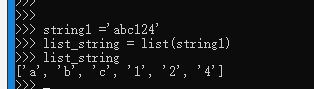
string1 ='abc124'
list_string = list(string1)
list_string
运行结果
三、is和==的区别
is判断两个对象是否一致(内存id地址一致)
==判断是两个对象的值是否相等

四、List功能点
1)初始化
list1 =[]
初始化固定长度 list1 =[None] * 10
2)拼接
注意:拼接的内容为列表,且返回一个新的列表
如:list1 =[1,‘2’] +[“3”] (允许)
list2=[1,‘2’]+“345” (列表拼接字符串,不允许)
list1 = [1,2,3]
list2 =[4,5,6]
print(id(list1),id(list2),"list1:",list1)
list1 = list1 +list2 #返回新的列表,id不一样
#list1.extend(list2) #在原有内容扩展列表,id一样
print(id(list1),list1)

3)常用方法

使用示例:



五、String功能点
1、格式化字符串
1)使用%s
2)使用.format()方式
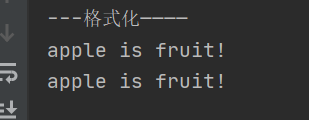
print("---格式化————")
item = "apple"
kind = "fruit"
print("%s is %s!"%(item,kind))
print("{} is {}!".format(item,kind))
运行结果:
2、常用方法

示例:
string1 = "Python Demo"
print("---find方法:在字符串中查找子串,如果找到,就返回子串的第一个字符索引,否则返回-1————")
print(string1.find("Demo"))
print(string1.find("不存在"))
print("---join方法:合并字符串———")
String2 = "","user","bin","env"
String2_join = "/".join(String2)
print(String2_join)
print("---split方法:将字符串拆分为列表———")
string_split = String2_join.split("/")
print(string_split,type(string_split))
print("---lower方法:将字符串变为小写———")
print(string1.lower())
print("---strip方法:将字符串开头和末尾的空白(注意不包括中间的空白)删除,并返回删除后的结果———")
print(" tomorrow is better ".strip())
print("---replace方法:将指定子串都替换为另一个字符串,并返回替换后的结果———")
print("time is gold!".replace("is","aaa"))
运行结果:

六、字典
1、字典创建
初始化 dict1 = {}
或者 dict1 = dict([(“name”,“Bob”),(“age”,24)])
运行结果如下:

2、常用功能

示例:
print("---fromkeys方法:创建一个新的字典,其中包含指定的键,且每个键对应的值都是None———")
dict2 = dict.fromkeys(["name","age"])
print(dict2)
print("---get方法:使用get来访问不存在的键,不会引发异常,而是返回None,也可指定默认值———")
dict2["name"] ="Bob"
dict2["age"] ="24"
print(dict2.get("name"),dict2.get("job","unKown"))
print("---items方法:返回一个包含所有字典项的内容,其中每个元素都为(key,value)的形式,排列顺序不确定———")
dict_item = dict2.items()
print(dict_item,type(dict_item))
print("---keys方法:返回字典的键列表———")
dict_key1 = dict2.keys()
print(dict_key1,type(dict_key1))
print("---values方法:返回字典的值列表———")
dict_value1 = dict2.values()
print(dict_value1,type(dict_value1))
print("---pop方法:根据字典的键删除内容,并返回对应键的值———")
value = dict2.pop("name")
print("value=",value,",dict2为",dict2)
print("---popitem方法:随机删除字典项内容,并返回删除的字典项———")
dict2["country"] = "中国"
dict2["degree"] = "本科"
pop_item = dict2.popitem()
print("删除字典项为:",pop_item,",删除后的字典为:",dict2)
print("---clear方法:清除字典所有内容———")
dict2.clear()
print(dict2)
运行结果如下:

七、作用域
变量名解析:LEGB原则,对于一个def语句:
1、变量名引用分为四个作用域进行查找:局部作用域 L (Local)–>>闭包函数外的函数中 E ( Enclosing ) -->> 全局作用域 G ( Global ) -->> 内建作用域 B (Built-in),并且在第一处能够找到这个变量名的地方停下来,如果没有搜索到,python会报错。
2、函数内部要修改一个变量,那么这个变量必须是内部变量,或者使用全局变量global进行声明!
3、global声明使用全局变量,nonlocal声明使用函数嵌套关系内层的变量,即闭包内部的变量。
注意:
1、python变量作用域取决于其函数代码块在整体代码中的位置,而不是被调用的位置!
2、当执行一条nonlocal语句时,nonlocal名称必须已经在一个嵌套的def作用域赋值过,否则会报错
3、nonlocal限制作用域查找仅为嵌套的def,nonlocal不会在嵌套的模块的全局作用域或所有def之外的内置作用域中查找,即便已经有了这些作用域
#作用域
X = 90 #全局变量
def func1():
X = 80 #局部变量
func2()
def func2():
print(X)
def func3():
X = 70
def func4():
print(X)
func4()
def func5():
X +=1
print(X)
def func6():
X = 60
def func7():
nonlocal X
X = 50
print(X)
print("调用func7前", X)
func7()
print("调用func7后",X)
func1() #返回结果为90,原因:python变量作用域取决于其函数代码块在整体代码中的位置,而不是被调用的位置!
func6() #调用func7前为60,调用func7为50,调用func7后为50,nonlocal限制作用域查找仅为嵌套的def
print(X) #返回结果为90,nonlocal限制作用域仅为嵌套的def,没有改变全局变量X
func3() #返回结果为70,
func5() #修改内容报错:函数内部要修改一个变量,那么这个变量必须是内部变量,或者使用全局变量global进行声明!
运行结果:

2、global 关键字:将变量设置为全局变量,可以在函数内使用/修改全局变量
X = "Spam"
def func():
global X
X = "NI"
func()
print(X) #输出结果为NI
八、继承
注意点:python支持多重继承,除非万不得已,否则应避免使用多重继承,因为如果多个超类以不同的方式实现了同一个方法,必须在class语句小心排列这些超类,因为前面的类方法将覆盖位于后面的类的方法:搜索顺序(D,B,C,A),类似广度优先算法
示例:
class A:
def meth(self):
print("A.meth")
def dispay(self):
print("A.dispaly")
def single(self):
print("A.single")
class C(A):
def meth(self):
print("C.meth")
def dispay(self):
print("C.dispaly")
class B(A):
def dispay(self):
print("B.dispaly")
class D(B,C):
pass
if __name__ =="__main__":
d = D()
d.meth()
d.dispay()
d.single()
运行结果:
C.meth
B.dispaly
A.single
九、静态方法、实例方法、类方法
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
场景:适合处理对层级中的每个类不同的数据
静态方法
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
场景:适用于处理一个类本地的数据
class Spam:
numInstances = 0
@classmethod
def count(cls):
cls.numInstances+=1
@staticmethod
def printNum():
print("Extra stuff ...",Spam.numInstances)
def __init__(self):
self.count()
class Sub(Spam):
numInstances = 0
def __init__(self):
Spam.__init__(self)
class Other(Spam):
numInstances = 0
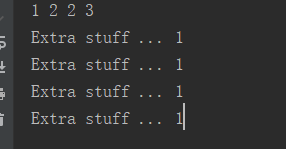
if __name__ == "__main__":
x =Spam()
y1,y2 = Sub(),Sub()
z1,z2,z3 = Other(),Other(),Other()
print(x.numInstances,y1.numInstances,y2.numInstances,z1.numInstances)
x.printNum(),y1.printNum(),y2.printNum(),z1.printNum()
运行结果:
十、参数及传递情况
1、参数类型
1)、位置参数:从左到右进行匹配
2)、关键字参数:通过参数名进行
匹配,使用:name =value这种语法
3)、默认参数:为没有
传入值得参数定义参数值,使用:定义函数时,使用name =value
4)、可变参数:收集任意多基于位置或关键字的参数,以字符*开头
5)、可变参数解包:传递任意多的基于位置或关键字的参数
6)、Keyword-only参数:参数必须按照名称传递。参数必须带有关键参数的名字(而不是位置)来传递。通用用于定义实际参数以外的配置选项
2、使用原则:
1)在函数调用中,参数必须以此顺序出现:任何位置参数(value),后面跟着任何关键字参数(name=value)和sequence形式的组合,后面跟着**dict形式
2)在函数头部,参数必须以此顺序出现:任何一般参数(name),紧跟着任何默认参数(name=value),后面是name的形式,后面跟着任何name =value keyword-only参数,后面跟着**name形式
#参数
def f(a,b,c=0):
print(a,b,c)
def f2(a,*param,c,**args): #关键字参数,位于*之后,使用时,必须为name = value形式
print(a,param,c,args)
f(1,2) #位置参数+默认参数,输出:1 2 0
f(a ='aa',b='bb',c ='cc') #关键字参数,输出:aa bb cc
f2(1,c="9",*(2,3,4),name="TOM",age="18") #位置参数,关键字参数,可变参数混合,1 (2, 3, 4) 9 {'name': 'TOM', 'age': '18'}
args = {'a':'sa','b':1}
args['c']='c3'
f(**args) #解包参数,输出:sa 1 c3
f(1,*(2,),**{'c':4}) #解包参数,输出:1 2 4
python的参数传递:对象的引用传递,不是指向一个具体的内存地址,而是指向一个具体的对象。
具体情况:
1、参数为可变对象时,当其改变,所有指向这个对象的变量都会改变
2、对象不可变时,简单的赋值只能改变其中一个变量的值,其余变量则不受影响。
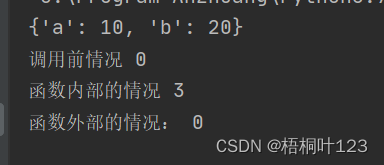
def func1(d):
d['a'] = 10
d['b'] = 20
d = {'a': 1, 'b': 2}
func1(d) #可变对象,修改了指向该变量的值
print(d)
def func2(a):
a =3
print("函数内部的情况",a)
a =0
print("调用前情况",a)
func2(a) #非可变对象,简单的赋值操作不会影响其他变量
print("函数外部的情况:",a)
十一、匿名函数lambda
1)概念:lambda是一个表达式,而不是一个语句,返回了一个值(一个新的函数)
2)用法:关键字lambda,之后使一个或多个参数(与一个def头部内用括号括起来的参数列表及其相似),紧跟的是一个冒号,之后是一个表达式
lambda匿名函数
L =[lambda x: x ** 2,
lambda x : x ** 3,
lambda x : x ** 4]
for f in L:
print(f(2)) #打印:4,8,16
print(L[0](8)) #打印:64
def action(x):
print("x=",x)
return (lambda y:x + y)
act = action(99) #将99赋值给x,输出x=99
print(act(3)) #将3赋值给y,输出102
十二、序列中映射函数map
map()是python内置的高阶函数,它接收一个函数f和迭代器(一个或多个),并通过把函数f依次作用在迭代器的每个元素上,得到一个新的迭代器并返回。根据提供的函数对指定序列做映射。
1)用法:
map(function,iterable,…)
2)返回结果:
python 2,返回列表
python3,返回为迭代器
#map函数
def show(x,y,z):
return x,y,z
print(map(show,[1,2,3,4,5])) #注意map返回结果为迭代器,如<map object at 0x000001F7F0081A90>
print(list(map(show,[1,2,3,4],[6,2,3,1],["a","b","c"]))) #打印:[(1, 6, 'a'), (2, 2, 'b'), (3, 3, 'c')]
十三、列表解析
概念:
根据已有列表,高效创建新列表的方式。
列表解析是Python迭代机制的一种应用,它常用于实现创建新的列表,因此用在[]中。
语法:
[expression for iter_val in iterable]
[expression for iter_val in iterable if cond_expr]
示例:
#获取0-4整数范围内的偶数
def func():
res = []
for i in range(5):
if i % 2 ==0:
res.append(i)
return res
print(func()) #普通for写法,输出[0,2,4]
print(list(filter(lambda x: x % 2 ==0,range(5)))) #结合了lambda
print([x for x in range(5) if x % 2 ==0]) #列表解析
十四、深浅拷贝
1、浅拷贝中的元素,是原对象中子对象的引用,因此,如果原对象中的元素是可变的,改变其也会影响拷贝后的对象,存在一定的副作用。
方式一:使用数据类型本身的构造器。
方式二:对于可变的序列,我们还可以通过切片操作符’:'完成浅拷贝。
方式三:copy.copy(对象),适用于任何数据类型。
import copy
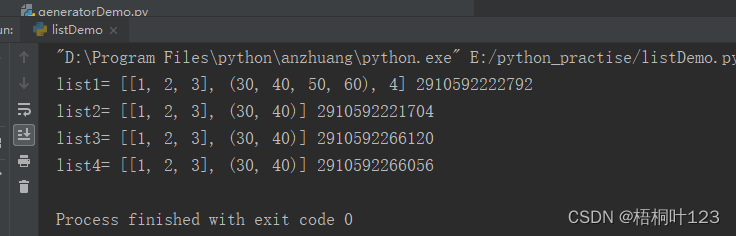
list1 = [[1, 2], (30, 40)]
list2 =list(list1) #构造函数浅拷贝
list3 = list1[:] #切片浅拷贝
list4 = copy.copy(list1) #copy方法浅拷贝
list1.append(4)
list1[0].append(3)
list1[1]+=(50,60)
print("list1=",list1,id(list1))
print("list2=",list2,id(list2))
print("list3=",list3,id(list3))
print("list4=",list4,id(list4))
执行结果
2、深度拷贝则会递归地拷贝原对象中的每一个子对象,因此拷贝后的对象和原对象互不相关。另外,深度拷贝中会维护一个字典,记录已经拷贝的对象及其 ID,来提高效率并防止无限递归的发生。
方式:copy.deepcopy(对象)
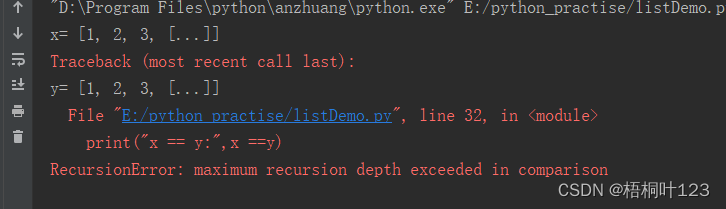
注意事项:无限嵌套拷贝时,进行 相等比较(==),会报错,提示:maximum recursion depth exceeded in comparison
import copy
x =[1,2,3]
x.append(x)
y = copy.deepcopy(x)
print("x=",x)
print("y=",y)
print("x == y:",x ==y)
结果:















 7654
7654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









