







一、集合类简介
数组是很常用的一种的数据结构,我们用它可以满足很多的功能,但是,有时我们会遇到如下这样的问题:
1、我们需要该容器的长度是不确定的。
2、我们需要它能自动排序。
3、我们需要存储以键值对方式存在的数据。
如果遇到上述的情况,数组是很难满足需求的,接下来本章将介绍另一种与数组类似的数据结构——集合类,集合类在Java中有很重要的意义,保存临时数据,管理对象,泛型,Web框架等,很多都大量用到了集合类。
下面是一些集合类继承关系图:
类图一
类图二

类图三

类图四
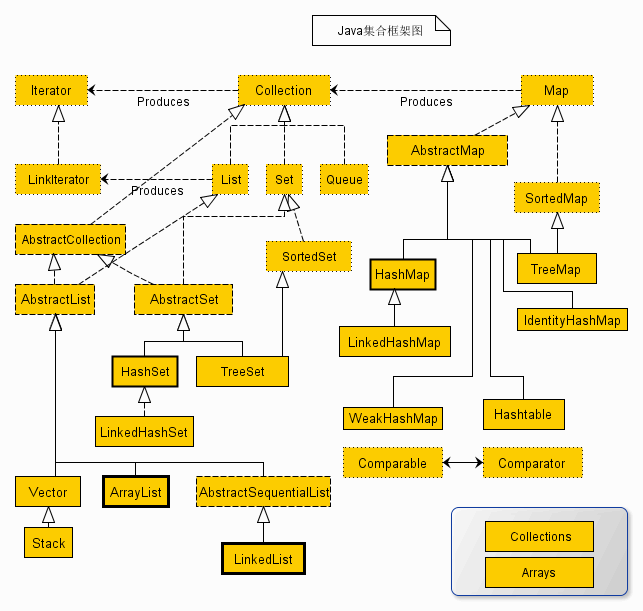
类图四

二、各集合特性总结
| 接口 | 简述 | 实现 | 操作特性 | 成员要求 |
| Set | 成员不能重复 | HashSet | 外部无序地遍历成员 | 成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeSet | 外部有序地遍历成员;附加实现了SortedSet, 支持子集等要求顺序的操作 | 成员要求实现caparable接口,或者使用 Comparator构造TreeSet。成员一般为同一类型。 | ||
| LinkedHashSet | 外部按成员的插入顺序遍历成员 | 成员与HashSet成员类似 | ||
| List | 提供基于索引的对成员的随机访问 | ArrayList | 提供快速的基于索引的成员访问,对尾部成员的增加和删除支持较好 | 成员可为任意Object子类的对象 |
| LinkedList | 对列表中任何位置的成员的增加和删除支持较好,但对基于索引的成员访问支持性能较差 | 成员可为任意Object子类的对象 | ||
| Map | 保存键值对成员,基于键找值操作,compareTo或compare方法对键排序 | HashMap | 能满足用户对Map的通用需求 | 键成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeMap | 支持对键有序地遍历,使用时建议先用HashMap增加和删除成员,最后从HashMap生成TreeMap;附加实现了SortedMap接口,支持子Map等要求顺序的操作 | 键成员要求实现caparable接口,或者使用Comparator构造TreeMap。键成员一般为同一类型。 | ||
| LinkedHashMap | 保留键的插入顺序,用equals 方法检查键和值的相等性 | 成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 | ||
| IdentityHashMap | 使用== 来检查键和值的相等性。 | 成员使用的是严格相等 | ||
| WeakHashMap | 其行为依赖于垃圾回收线程,没有绝对理由则少用 |
|
三、基本方法
1、Collection (集合的最大接口)继承关系
——List 可以存放重复的内容
——Set 不能存放重复的内容,所以的重复内容靠hashCode()和equals()两个方法区分
——Queue 队列接口
——SortedSet 可以对集合中的数据进行排序
Collection定义了集合框架的共性功能。
1,添加
add(e);
addAll(collection);
2,删除
remove(e);
removeAll(collection);
clear();
3,判断。
contains(e);
isEmpty();
4,获取
iterator();
size();
5,获取交集。
retainAll();
6,集合变数组。
toArray();
*add方法的参数类型是Object。以便于接收任意类型对象。
*集合中存储的都是对象的引用(地址)
2、List的常用子类
List:
特有方法。凡是可以操作角标的方法都是该体系特有的方法。
增
add(index,element);
addAll(index,Collection);
删
remove(index);
改
set(index,element);
查
get(index):
subList(from,to);
listIterator();
int indexOf(obj):获取指定元素的位置。
ListIterator listIterator();
3、各List特性
——ArrayList 线程不安全,查询速度快
——Vector 线程安全,但速度慢,已被ArrayList替代
——LinkedList 链表结果,增删速度快
4、Set接口
Set:元素是无序(存入和取出的顺序不一定一致),元素不可以重复。
|——HashSet:底层数据结构是哈希表。是线程不安全的。不同步。
HashSet是如何保证元素唯一性的呢?
是通过元素的两个方法,hashCode和equals来完成。
如果元素的HashCode值相同,才会判断equals是否为true。
如果元素的hashcode值不同,不会调用equals。
注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。
|——TreeSet:
有序的存放:TreeSet 线程不安全,可以对Set集合中的元素进行排序
通过compareTo或者compare方法来保证元素的唯一性,元素以二叉树的形式存放。
5、Object类
*在实际开发中经常会碰到区分同一对象的问题,一个完整的类最好覆写Object类的hashCode()、equals()、toString()三个方法。
6、集合的输出
——4种常见的输出方式
——Iterator: 迭代输出,使用最多的输出方式
——ListIterator: Iterator的子接口,专门用于输出List中的内容
——Enumeration
——foreach
在迭代时,不可以通过集合对象的方法操作集合中的元素,因为会发生ConcurrentModificationException异常,所以,在迭代器时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。
该接口只能通过List集合的listIterator方法获取。
7、Map接口
*Correction、Set、List接口都属于单值的操作,而Map中的每个元素都使用key——>value的形式存储在集合中。
Map集合:该集合存储键值对。一对一对往里存。而且要保证键的唯一性。
1,添加。
put(K key, V value)
putAll(Map<? extends K,? extends V> m)
2,删除。
clear()
remove(Object key)
3,判断。
containsValue(Object value)
containsKey(Object key)
isEmpty()
4,获取。
get(Object key)
size()
values()
entrySet()
keySet()
8、Map接口的常用子类
Map
|HashMap:底层是哈希表数据结构,允许使用 null 值和 null 键,该集合是不同步的。将hashtable替代,jdk1.2.效率高。
|--TreeMap:底层是二叉树数据结构。线程不同步。可以用于给map集合中的键进行排序。
四、使用
1.Java.util.ArrayList(类)
import java.awt.*;
import java.util.*;
public class CollectionTest
{//List是一个能包含重复元素的已排序的Collection,有时list也称为序列,List第一个元素的下标为0
public String colors[]={"red","white","blue"};//定义一个字符数组
//构造函数
public CollectionTest()
{
ArrayList list=new ArrayList();//实例化一个ArrayList
list.add(Color.magenta);//向里面添加一个元素,这里是颜色
for(int count=0;count<colors.length;count++)
list.add(colors[count]);//加入开始声明的数组中的元素
list.add(Color.cyan); //颜色 导入awt包
System.out.println("\nArrayList");
for(int count=0;count<list.size();count++)
System.out.println(list.get(count)+" ");//从arrayList中读取 元素
removeString(list);
System.out.println("\n\nArrayList after calling"+"removeString:");
for(int count=0;count<list.size();count++)
System.out.println(list.get(count)+" ");
}
public void removeString(Collection collection)
{
Iterator itrator=collection.iterator(); //声明一个迭代
//调用itrator的hasNext方法判断Collection是否还包含元素
while(itrator.hasNext())
{
//调用itrator的next方法获得下一个元素的引用
if( itrator.next() instanceof String ) // instanceof 判断是否是String 的实例
itrator.remove(); //如果是的 则删除
}
}
public static void main(String[] args)
{
new CollectionTest();
}
} 该例示范了ArrayList的使用 先声明了一String类型的数组,里面存储了“颜色”,是用字符串写出的颜色,将这个字符串数组存入ArrayList实例,同时还存入了awt包内的颜色实例,全部存入后利用迭代,删除不符要求的假数据,也就是我们用字符串写的颜色,也用到了 instanceof 它是一个二元操作符,类似于equals用于判断instanceof左边 的对象 是否是 右边对象的实例,若是 返回真,这里就可以判断 ArrayList里面的真假颜色,假颜色是 字符串的 实例,所以我们通过迭代 一个个对比。只要是String的实例就将其从数组中删除,所以最后 ArrayList里面仅仅剩下二个元素,运行效果如下:

2.java.util.HashSet(类)
//Set是包含独一无二元素的Collection,HashSet把它的元素存储在哈希表中,而TreeSet把它的元素存储在树中
import java.util.*;
public class SetTest
{
private String colors[]={"orange","tan","orange","white", "gray"};
public SetTest()
{
ArrayList list;
list=new ArrayList(Arrays.asList(colors));
System.out.println("ArrayList:"+list);
printNonDuplicates(list);
}
public void printNonDuplicates(Collection collection)
{
//构造HashSet删除Collection中多余的元素
HashSet set=new HashSet(collection);
// 将coolection放入HashSet后即会消除重复元素
System.out.println("set:"+set);
Iterator itrator=set.iterator();
System.out.println("\nNonDuplicates are:");
while(itrator.hasNext())
System.out.println(itrator.next()+" ");
System.out.println();
}
public static void main(String[] args)
{
new SetTest();
}
}输出的结果为:

可以看到重复元素orange除去了。
3.java.util.Set(接口)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
class TestSet
{
public static void main(String args[])
{
Set set = new HashSet();
set.add("aaa");
set.add("bbb");
set.add("aaa");//后面加入的重复性元素均无效
set.add("bbb");
set.add("aaa");
set.add("bbb");
set.add("aaa");
set.add("bbb");
set.add("aaa");
set.add("bbb");
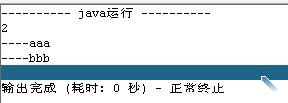
Iterator ite=set.iterator();
System.out.println(set.size());//the result is 2
while(ite.hasNext())
{
System.out.println("----"+ite.next());
}
}
}
输出结果为:
4.java.util.List(接口)
package tt;
import java.util.Arrays;
import java.util.Collections;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class ListTest {
public static void baseUse(){
//链表实现
List list = new LinkedList();
//数组实现
//List list = new ArrayList();
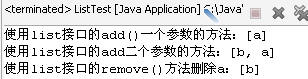
list.add("a");//向列表的尾部追加"a"
System.out.println("使用list接口的add()一个参数的方法:"+list);
list.add(0,"b");//在指定位置插入"b"
System.out.println("使用list接口的add二个参数的方法:"+list);
list.remove("a");//移除列表中"a"
System.out.println("使用list接口的remove()方法删除a:"+list);
}
public static void useSort(){
String[] strArray = new String[] {"z", "a", "c","C"};
List list = Arrays.asList(strArray);
System.out.println(list);
Collections.sort(list);//根据元素自然顺序排序
System.out.println("自然顺序:"+list);
Collections.sort(list, String.CASE_INSENSITIVE_ORDER);//根据指定的字母方式排序
System.out.println("指定字母方式:"+list);
Collections.sort(list, Collections.reverseOrder());//根据反转自然顺序方式排序
System.out.println("反转自然顺序:"+list);
Collections.sort(list, String.CASE_INSENSITIVE_ORDER);
System.out.println(list);
Collections.reverse(list);//反转列表排序
System.out.println(list);
}
public static void main(String[] args) {
baseUse();
// useSort();
}
}运行
5.java.util.TreeSet(类)
package tt;
import java.util.Iterator;
import java.util.TreeSet;
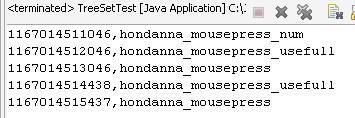
public class TreeSetTest {
public static void main(String args[]){
TreeSet a = new TreeSet();
a.add("1167014513046,hondanna_mousepress");
a.add("1167014512046,hondanna_mousepress_usefull");
a.add("1167014511046,hondanna_mousepress_num");
a.add("1167014515437,hondanna_mousepress");
a.add("1167014514438,hondanna_mousepress_usefull");
Iterator iterator = a.iterator();
while(iterator.hasNext())
System.out.println(iterator.next());
}
}
运行结果:
6.java.util.Map(接口)
遍历Map对象的4种方法
方法一、在for-each循环中使用entrySet来遍历
这是最常见的并且在大多数情况下也是最可取的遍历方式。在键值都需要时使用。
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
如果只需要map中的键或者值,你可以通过keySet或values来实现遍历,而不是用entrySet。
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
//遍历map中的键
for (Integer key : map.keySet()) {
System.out.println("Key = " + key);
}
//遍历map中的值
for (Integer value : map.values()) {
System.out.println("Value = " + value);
}方法三、使用Iterator遍历
使用泛型:
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}不使用泛型:
Map map = new HashMap();
Iterator entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry entry = (Map.Entry) entries.next();
Integer key = (Integer)entry.getKey();
Integer value = (Integer)entry.getValue();
System.out.println("Key = " + key + ", Value = " + value);
}方法四、通过键找值遍历(效率低)
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (Integer key : map.keySet()) {
Integer value = map.get(key);
System.out.println("Key = " + key + ", Value = " + value);
}总结
如果仅需要键(keys)或值(values)使用方法二。如果你使用的语言版本低于java 5,或是打算在遍历时删除entries,必须使用方法三。否则使用方法一(键值都要)。















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









