







1.其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
话说计算机是由美国佬搞出来的嘛,他们觉得一个字节(可以表示256个编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前127个编码)。后来欧洲人不干了,法国人说:我需要在小写字母加上变音符号(如:é),德国人说:我也要加几个字母(Ä ä、Ö ö、Ü ü、ß)。于是,欧洲人就将ASCII没用完的编码(128-255)为自己特有的符号编码(后来称之为“扩展字符集”)。等到我们中国人开始使用计算机的时候,尼玛,256个编码哪够?我泱泱大中华,汉字起码也得N多万吧,就连小学生都得要求掌握两三千字。国标局最后拍板:一个字节不够,那我们就用多个字节来为汉字编码吧,但是,国情那么穷,字节那么贵,三个字节伤不起,那就用俩字节吧,先给常用的几千汉字编个码,等以后国家强盛了人民富裕了,咱再扩展呗---于是GB2312就产生了。台湾同胞一看,尼玛,全是简体字,还让不让我们写繁体字的活了,于是台湾同胞也自己弄了个繁体字编码---大五码(Big-5)。同时,其它国家也在为自己的文字编码。最后,微软苦逼了:顾客就是上帝啊,你们的编码我都得满足啊,这样吧,卖给美国国内的系统默认就用ASCII编码吧,卖给中国人的系统默认就用GBK编码吧,卖给韩国人的系统默认就用EUC-KR编码,...但是为了避免你们误会我卖给你们的系统功能有差异,我就统一把你们的默认编码都显示成ANSI吧。---本故事纯属虚构,但“ANSI编码”确实只存在于Windows系统。
2.所谓本地编码,就是像 GBK、Big5、Shift-JIS 等这样的国家编码(地区编码);针对不同国家发行的操作系统,默认的本地编码一般不同。简体中文本的 Windows 默认的本地编码是 GBK。站在专业的角度讲,源文件使用的字符集被称为编码字符集,也就是写代码的时候使用的字符集;程序中的字符或者字符串使用的字符集被称为运行字符集,也就是程序运行后使用的字符集。源文件需要保存到硬盘,或者在网络上传输,使用的编码要尽量节省存储空间,同时要方便跨国交流,所以一般使用 UTF-8,这就是选择编码字符集的标准。程序中的字符或者字符串,在程序运行后必须被载入到内存,才能进行后续的处理,对于这些字符来说,要尽量选用能够提高处理速度的编码,例如 UTF-16 和 UTF-32 编码就能够快速定位(查找)字符。编码字符集是站在存储和传输的角度,运行字符集是站在处理或者操作的角度,所以它们并不一定相同。
3.转义字符以\或者\x开头,以\开头表示后跟八进制形式的编码值,以\x开头表示后跟十六进制形式的编码值。对于转义字符来说,只能使用八进制或者十六进制。转义字符既可以用于单个字符,也可以用于字符串,并且一个字符串中可以同时使用八进制形式和十六进制形式。
4.表达式必须有一个执行结果,这个结果必须是一个值;以分号;结束的往往称为语句,而不是表达式
5.取余,也就是求余数,使用的运算符是 %。C语言中的取余运算只能针对整数,也就是说,% 的两边都必须是整数,不能出现小数,否则编译器会报错。
另外,余数可以是正数也可以是负数,由 % 左边的整数决定:
- 如果 % 左边是正数,那么余数也是正数;
- 如果 % 左边是负数,那么余数也是负数
6.在 printf 中,% 是格式控制符的开头,是一个特殊的字符,不能直接输出;要想输出 %,必须在它的前面再加一个 %,这个时候 % 就变成了普通的字符,而不是用来表示格式控制符了。
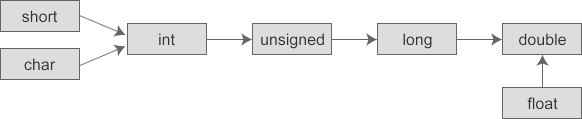
7.在不同类型的混合运算中,编译器也会自动地转换数据类型,将参与运算的所有数据先转换为同一种类型,然后再进行计算。转换的规则如下:
- 转换按数据长度增加的方向进行,以保证数值不失真,或者精度不降低。例如,int 和 long 参与运算时,先把 int 类型的数据转成 long 类型后再进行运算。
- 所有的浮点运算都是以双精度进行的,即使运算中只有 float 类型,也要先转换为 double 类型,才能进行运算。
- char 和 short 参与运算时,必须先转换成 int 类型。
下图对这种转换规则进行了更加形象地描述:
8.可以自动转换的类型一定能够强制转换,但是,需要强制转换的类型不一定能够自动转换
9.
| 格式控制符 | 说明 |
|---|---|
| %c | 输出一个单一的字符 |
| %hd、%d、%ld | 以十进制、有符号的形式输出 short、int、long 类型的整数 |
| %hu、%u、%lu | 以十进制、无符号的形式输出 short、int、long 类型的整数 |
| %ho、%o、%lo | 以八进制、不带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %#ho、%#o、%#lo | 以八进制、带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %hx、%x、%lx %hX、%X、%lX | 以十六进制、不带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字也小写;如果 X 大写,那么输出的十六进制数字也大写。 |
| %#hx、%#x、%#lx %#hX、%#X、%#lX | 以十六进制、带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字和前缀都小写;如果 X 大写,那么输出的十六进制数字和前缀都大写。 |
| %f、%lf | 以十进制的形式输出 float、double 类型的小数 |
| %e、%le %E、%lE | 以指数的形式输出 float、double 类型的小数。如果 e 小写,那么输出结果中的 e 也小写;如果 E 大写,那么输出结果中的 E 也大写。 |
| %g、%lg %G、%lG | 以十进制和指数中较短的形式输出 float、double 类型的小数,并且小数部分的最后不会添加多余的 0。如果 g 小写,那么当以指数形式输出时 e 也小写;如果 G 大写,那么当以指数形式输出时 E 也大写。 |
| %s %p | 输出一个字符串
|
%-9d中,d表示以十进制输出,9表示最少占9个字符的宽度,宽度不足以空格补齐,-表示左对齐。
10.printf() 格式控制符的完整形式如下:
%[flag][width][.precision]type:width 表示最小输出宽度,.precision 表示输出精度(也可以用于整数和字符串,用于整数时,.precision 表示最小输出宽度与 width 不同的是,整数的宽度不足时会在左边补 0,而不是补空格,用于字符串时,.precision 表示最大输出宽度,或者说截取字符串当字符串的长度大于 precision 时,会截掉多余的字符;当字符串的长度小于 precision 时,.precision 就不再起作用)flag 是标志字符。例如,%#x中 flag 对应 #,%-9d中 flags 对应-。下表列出了 printf() 可以用的 flag:
| 标志字符 | 含 义 |
|---|---|
| - | -表示左对齐。如果没有,就按照默认的对齐方式,默认一般为右对齐。 |
| + | 用于整数或者小数,表示输出符号(正负号)。如果没有,那么只有负数才会输出符号。 |
| 空格 | 用于整数或者小数,输出值为正时冠以空格,为负时冠以负号。 |
| # |
|
11.可以说,输入输出的“命门”就在于缓存。
12.scanf 是 scan format 的缩写,意思是格式化扫描,也就是从键盘获得用户输入,和 printf 的功能正好相反。 本质上讲,用户输入的内容都是字符串,scanf() 完成的是从字符串中提取有效数据的过程。scanf() 不会跳过不符合要求的数据,遇到不符合要求的数据会读取失败,而不是再继续等待用户输入scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串
13.
scanf() 格式控制符汇总
| 格式控制符 | 说明 |
|---|---|
| %c | 读取一个单一的字符 |
| %hd、%d、%ld | 读取一个十进制整数,并分别赋值给 short、int、long 类型 |
| %ho、%o、%lo | 读取一个八进制整数(可带前缀也可不带),并分别赋值给 short、int、long 类型 |
| %hx、%x、%lx | 读取一个十六进制整数(可带前缀也可不带),并分别赋值给 short、int、long 类型 |
| %hu、%u、%lu | 读取一个无符号整数,并分别赋值给 unsigned short、unsigned int、unsigned long 类型 |
| %f、%lf | 读取一个十进制形式的小数,并分别赋值给 float、double 类型 |
| %e、%le | 读取一个指数形式的小数,并分别赋值给 float、double 类型 |
| %g、%lg | 既可以读取一个十进制形式的小数,也可以读取一个指数形式的小数,并分别赋值给 float、double 类型 |
| %s | 读取一个字符串(以空白符为结束) |
gets() 和 scanf() 的主要区别是:
- scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。
- gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。
14.缓冲区其实就是一块内存空间,它用在硬件设备和用户程序之间,用来缓存数据,目的是让快速的 CPU 不必等待慢速的输入输出设备,同时减少操作硬件的次数。缓冲区位于用户程序和硬件设备之间,用来缓存数据,目的是让快速的 CPU 不必等待慢速的输入输出设备,同时减少操作硬件的次数。对于 IO 密集型的网络应用程序,比如网站、数据库、DNS、CDN 等,缓冲区的设计至关重要,它能十倍甚至一百倍得提高程序性能,根据数据刷新(也可以称为清空缓冲区,就是将缓冲区中的数据“倒出”)的时机,可以分为全缓冲、行缓冲、不带缓冲。当遇到 scanf() 函数时,程序会先检查输入缓冲区中是否有数据:空白符在大部分情况下都可以忽略,前面的两个例子就是这样。但是当控制字符串不是以格式控制符 %d、%c、%f 等开头时,空白符就不能忽略了,它会参与匹配过程,如果匹配失败,就意味着 scanf() 读取失败了。
- 如果没有,就等待用户输入。用户从键盘输入的每个字符都会暂时保存到缓冲区,直到按下回车键,产生换行符
\n,输入结束,scanf() 再从缓冲区中读取数据,赋值给变量。 - 如果有数据,那就看是否符合控制字符串的规则:
- 如果能够匹配整个控制字符串,那最好了,直接从缓冲区中读取就可以了,就不用等待用户输入了。
- 如果缓冲区中剩余的所有数据只能匹配前半部分控制字符串,那就等待用户输入剩下的数据。
- 如果不符合,scanf() 还会尝试忽略一些空白符,例如空格、制表符、换行符等:
- 如果这种尝试成功(可以忽略一些空白符),那么再重复以上的匹配过程。
- 如果这种尝试失败(不能忽略空白符),那么只有一种结果,就是读取失败。
15.清空输出缓冲区很简单:fflush(stdout);
16.使用 getchar() 清空缓冲区
getchar() 是带有缓冲区的,每次从缓冲区中读取一个字符,包括空格、制表符、换行符等空白符,只要我们让 getchar() 不停地读取,直到读完缓冲区中的所有字符,就能达到清空缓冲区的效果。请看下面的代码:
- int c;
- while((c = getchar()) != '\n' && c != EOF);
另外一种清空输入缓冲区:scanf("%*[^\n]"); scanf("%*c");















 5295
5295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









