







一、anyq容器host模式运行
由于anyq容器,后期还会有其他端口需要访问,比如solr的webapp页面端口就是8900,等等。所以可以采用host方法run一个新的容器。
#提交anyq镜像,生成新镜像anyq-host,并run新的anyq-host容器
docker stop anyq
docker commit anyq anyq-host
#使用--privileged=true和/usr/sbin/init参数确保在容器中可以用systemctl命令
docker run -itd --name=anyq-host --privileged=true --network=host anyq-host /usr/sbin/init
docker exec -it anyq-host /bin/bash
二、在容器anyq-host中启动solr
##5.进入home目录
cd home
##6.配置java环境
export PATH=`pwd`/jdk1.8.0_171/bin:$PATH
##7.进入AnyQ/build目录
cd AnyQ
cd build
##8.启动solr
sh solr_script/anyq_solr.sh solr_script/sample_docs
三、在浏览器中查看solr的webapp面板
1.打开面板
打开浏览器,输入http://192.168.99.100:8900/solr/即可。192.168.99.100是win7中docker-machine默认ip地址。*nix(或Ubuntu桌面版)中应该是http://127.0.0.1:8900/solr/。如下图所示,表明solr运行成功。
 2.通过左下角选择器选择集合collection1
2.通过左下角选择器选择集合collection1
 3.在Documents选项卡中上传文档(上传数据)
3.在Documents选项卡中上传文档(上传数据)
 4.在Query选项卡中查询数据
4.在Query选项卡中查询数据
 以上演示solr数据的上传及查询,这也表明solr可以动态添加数据。solr对于大型索引,优化需要一些时间才能完成,但是通过将许多小段文件合并为一个更大的文件,搜索性能将会提高。不建议一条一条添加数据,可以合并一次性并进行优化操作,对于搜索性能是好的。
以上演示solr数据的上传及查询,这也表明solr可以动态添加数据。solr对于大型索引,优化需要一些时间才能完成,但是通过将许多小段文件合并为一个更大的文件,搜索性能将会提高。不建议一条一条添加数据,可以合并一次性并进行优化操作,对于搜索性能是好的。
四、solr 从数据库导入数据,全量索引和增量索引
此处内容主要参考博客:https://blog.csdn.net/u013378306/article/details/50761610及相关solr知识。
1.在docker或者宿主机中安装数据库
由于我是在云服务器CentOS7.2中测试的,服务器中安装有小皮面板(phpstudy linux),确实好用,必须给小皮打个广告,安装mysql那是一键安装并默认配置好,个性化配置也方便。
设置字段如下: 其中数据初始如下:
其中数据初始如下: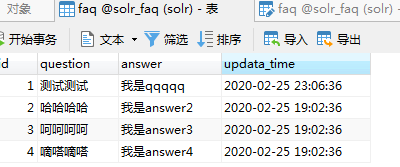
2.更改solr配置文件/home/AnyQ/build/solr-4.10.3-an
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2943
2943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









