







 本文是数学之美阅读笔记的一部分,主要探讨统计语言模型在自然语言处理中的应用,如二元模型和N元模型。此外,还介绍了信息熵的概念及其在消除不确定性中的作用。文中提及香农的信息熵和互信息理论,并简述了布尔代数在搜索引擎中的应用,以及图论在网络爬虫中的深度优先和广度优先搜索策略。最后,提到了PageRank算法作为衡量网页质量的经典方法。
本文是数学之美阅读笔记的一部分,主要探讨统计语言模型在自然语言处理中的应用,如二元模型和N元模型。此外,还介绍了信息熵的概念及其在消除不确定性中的作用。文中提及香农的信息熵和互信息理论,并简述了布尔代数在搜索引擎中的应用,以及图论在网络爬虫中的深度优先和广度优先搜索策略。最后,提到了PageRank算法作为衡量网页质量的经典方法。
大一的时候就开始看吴军博士第一版的《数学之美》,苦于那时年少无知不懂事,加上自身数学知识的体系不健全,翻着翻着也就没有了后文。现在读了研究僧,也许是换了个视野,看到书的开头“中国教育最失败的就是学生从上课的第一天到考试结束,都不知道学的东西能干什么。”,果然是大实话,私以为学习的原动力在于内心的诉求,当有应用的需求时,学习起来就会更带劲。趁着在校时光,安安静静读读书写写字,所以决定将这本书的精髓地方整理整理形成笔记,健忘症发作时就可以随手看看电子版。
1.统计语言模型
基于统计语言的数学模型是自然语言处理(NLP)的基础,贾里尼克的出发点是:一个句子是否合理,看它出现的可能性大小。假定S表示一个有意义的句子,且由一连串顺序排列的词组成(英文中有空格隔开,中文则需要进行分词),出现的可能性则是计算P(S),若直接使用频数统计S在所有语料库中出现的概率,则肯定行不通,利用条件概率展开P(S):
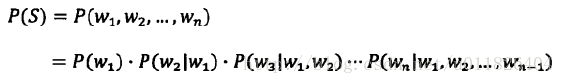
从计算来看,计算前几个条件概率还十分容易,但到了后面根本无法进行估算。俄国的马尔科夫提出了一种偷懒的方法,即假设任意一个词出现的概率只和它前面的那个词有关。这样P(S)就变得十分简单:
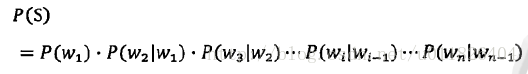
这就是统计语言模型中的二元模型(Bigram Model),如果假设一个词由前面的N-1个词决定,则成为N元模型。接下来计算则变得十分美妙:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









