







目录:
1. 基于统计的机器翻译模型
2. 基于RNN的机器翻译模型
3. GRU(2014)
4. LSTM(1997)
5. 总结
\newline
\newline
1. 基于统计的机器翻译模型
目前基于统计的机器翻译系统要具备以下几点:
- 源语言(source language) 比如要被翻译的法语French-f;
- 目标语言(target language) 比如我们要翻译成的语言English-e
- 贝叶斯概率公式:
e ^ = a r g m a x e p ( e ∣ f ) = a r g m a x e p ( f ∣ e ) p ( e ) \hat{e}=argmax_ep(e|f)=argmax_ep(f|e)p(e) e^=argmaxep(e∣f)=argmaxep(f∣e)p(e)
其中p(f|e)为翻译模型,是通过平行语料库训练(统计)出来的;
其中的p(e)为语言模型,是通过目标语言训练(统计)出来的;
上式中的等式推导是利用的贝叶斯概率公式:
p ( e ∣ f ) = p ( f ∣ e ) p ( e ) p ( f ) p(e|f)={p(f|e)p(e) \over p(f)} p(e∣f)=p(f)p(f∣e)p(e)
后验概率=先验概率*似然/边缘概率,这里的边缘概率可以是源语言(已经给定),因此p(f)=1
翻译模型的流程框架图如下:
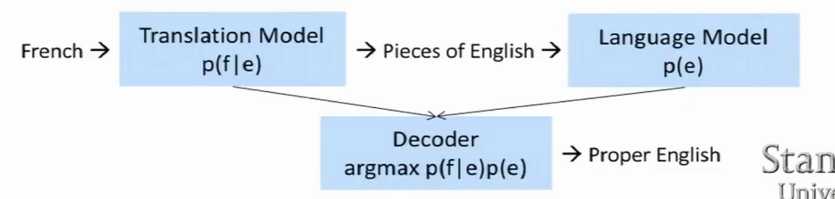
直观上我们做机器翻译就是找到一个最佳匹配的过程,下面我们就把上面的过程拆分成两部分来描述
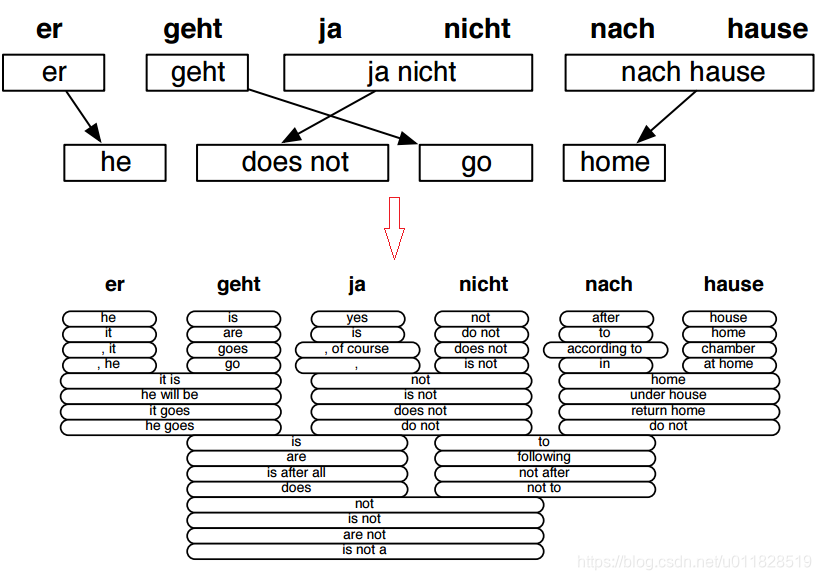
步骤一:Alignment(匹配)
此步骤是针对上面谈到的翻译模型,目的是知道源语言中的某个单词或者短语会被翻译成目标语言中的哪些单词或短语。但是这会面临很多问题:

这些问题会导致组合的爆炸,非常难解决。当然这肯定难不住一直奋斗在这一领域的先贤们,他们理应词组和语法,而不仅仅是单词去构造复杂的匹配系统完成匹配,最终得到了我们想要的匹配结果(一个单词或者词组可能会匹配到若干个单词或词组),整个步骤一如下图:
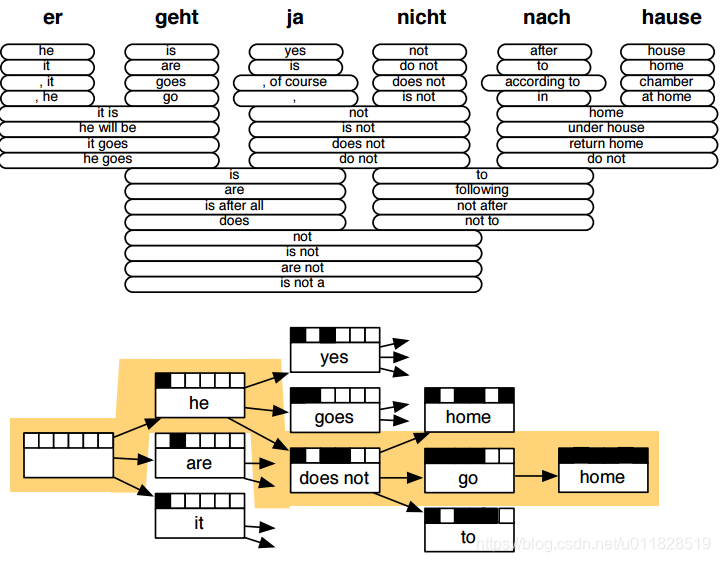
步骤二:Decoder(解码)
在步骤一中因为源语言中的某个短语或单词在目标语言可能会匹配到若干个单词或词组,所以我们需要解码器去找到最好的组合,形成翻译结果。解码过程如下图:
传统机器翻译模型的总结:
(1)需要大量的人工特征去构造翻译系统
(2)需要大量的时间和人力去构造翻译系统
(3)传统的机器翻译模型最主要的问题是,它不仅仅是一个复杂的系统,它还需要有多个机器学习模型(翻译模型、语言模型等)来组成,而深度学习的end-to-end方式完全碾压它。
2. 基于RNN的机器翻译模型
既然传统的机器翻译模型如此复杂,那么深度学习模型RNN是否能够在这一领域大放异彩呢,我们首先来看一下RNN是如何来做机器翻译的:
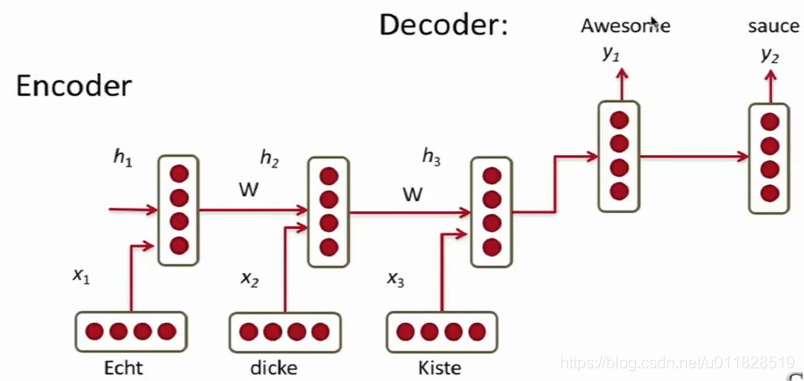
此处编码器和解码器为一个RNN单元(PS:先入为主,以前看过机器翻译,刚开始以为两个RNN不是一个,原来先贤们是从同一个RNN刻画编码和解码开始尝试的,后面的改进才变成两个RNN)。
- 编码器的作用是,讲要翻译的内容通过RNN编码成一个固定维度的向量。
- 解码器的作用是,将编码器的结果作为输入,通过RNN进行解码翻译。
由于编码器将整个要翻译的内容编码成了一个固定为度的向量,所以编码器RNN输出的结果最好要能够捕捉到整个要翻译内容的特征,但是实际上只能捕捉到五六个单词的特征,所以翻译效果不是很好,后面我们会通过LSTM、GRU对这个问题进行改进。
下面我们先通过公式来定义一个基础的基于RNN机器翻译模型:
编码器:
h
t
=
ϕ
(
h
t
−
1
,
x
t
)
=
f
(
W
h
h
h
t
−
1
,
W
h
x
x
t
)
h_t=\phi(h_{t-1},x_t)=f(W^{hh}h_{t-1},W^{hx}x_t)
ht=ϕ(ht−1,xt)=f(Whhht−1,Whxxt)
解码器:
h
t
=
ϕ
(
h
t
−
1
)
=
f
(
W
h
h
h
t
−
1
)
h_t=\phi(h_{t-1})=f(W^{hh}h_{t-1})
ht=ϕ(ht−1)=f(Whhht−1)
y
t
=
s
o
f
t
m
a
x
(
W
(
S
)
h
t
)
y_t=softmax(W^{(S)}h_t)
yt=softmax(W(S)ht)
损失函数采用交叉熵损失:
l
o
s
s
=
m
a
x
θ
1
N
∑
n
=
1
N
l
o
g
p
θ
(
y
(
n
)
∣
x
(
n
)
)
loss=max_{\theta}{1\over N}\sum_{n=1}^Nlogp_{\theta}(y^{(n)}|x^{(n)})
loss=maxθN1n=1∑Nlogpθ(y(n)∣x(n))
基于RNN机器翻译模型的一系列拓展:
(1)将模型中的编码器和解码器变为不同的两个RNN,即训练两个不同权重的RNN单元,一个用于编码,一个用于解码;
(2)改变解码器的输入,解码器的公式变为:
h
D
,
t
=
ϕ
D
(
h
t
−
1
,
c
,
y
t
−
1
)
h_{D,t}=\phi_D(h_{t-1},c,y_{t-1})
hD,t=ϕD(ht−1,c,yt−1)
其中编码器的输入不再仅仅是上一时刻的隐向量
h
t
−
1
h_{t-1}
ht−1,而是变成了:
h
t
−
1
h_{t-1}
ht−1:上一时刻的隐向量
c:编码器最后的输出
y
t
−
1
y_{t-1}
yt−1:上一时刻的输出
结构图如下:

(3)训练多层的RNN or 训练双向的编码器
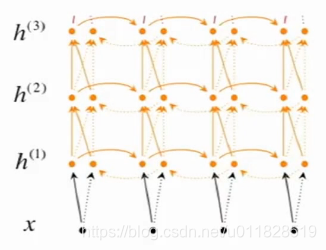
(4)将输入逆序去训练编码器,即把A B C→X Y改为C B A→X Y,课中说在翻译时把对应的单词放近一点,防止梯度消失。(PS:我认为,序列太长的时候,这样在解码阶段就会防止解码器忘记要翻译句子的前面的部分,但是这样的话,虽然A距离X比以前进了,但是原来C距离Y一个序列长度,现在double了,感觉像是拆了东墙补西墙,效果也不会好到哪儿去)
3. GRU(2014)
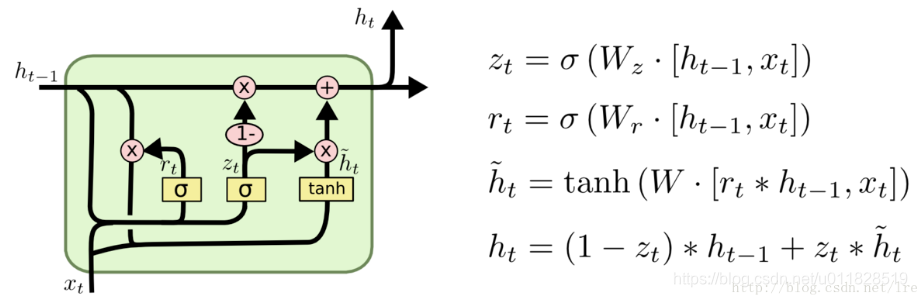
这里改进主要的思想是使RNN单元更复杂,加入了‘门’的概念,这样做:
(1)使RNN单元能够保留住长距离依赖的记忆
(2)基于输入,RNN单元能够使一些错误信息或者无用的信息消失
标准的RNN不经过任何门,直接通过此时输入
x
t
x_t
xt和上一时刻的隐状态
h
t
−
1
h_{t-1}
ht−1计算,如下式:
h
t
=
ϕ
(
h
t
−
1
,
x
t
)
=
f
(
W
h
h
h
t
−
1
,
W
h
x
x
t
)
h_t=\phi(h_{t-1},x_t)=f(W^{hh}h_{t-1},W^{hx}x_t)
ht=ϕ(ht−1,xt)=f(Whhht−1,Whxxt)
但是此时GRU复杂化了这个过程,完成了上面的两个改进思想;
GRU基于此时输入
x
t
x_t
xt和上一时刻的隐状态
h
t
−
1
h_{t-1}
ht−1计算出了自己设计的更新门(update gate)和重置门(reset gate);
更新门(update gate)的计算公式:
z
t
=
σ
(
W
(
z
)
h
t
−
1
+
U
(
z
)
x
t
)
z_t=\sigma(W^{(z)}h_{t-1}+U^{(z)}x_t)
zt=σ(W(z)ht−1+U(z)xt)
重置门(reset gate)的计算公式:
r
t
=
σ
(
W
(
r
)
h
t
−
1
+
U
(
r
)
x
t
)
r_t=\sigma(W^{(r)}h_{t-1}+U^{(r)}x_t)
rt=σ(W(r)ht−1+U(r)xt)
SIGMOD函数会使更新门和重置门会计算出两个值在0-1之间的权重向量
下面我们就来看看这两个门是如何发挥作用的:
-
重置门计算出当前时刻输入的新记忆:
h t ^ = t a n h ( W x t + r t ⨀ U h t − 1 ) \hat{h_t}=tanh(Wx_{t}+r_t \bigodot Uh_{t-1}) ht^=tanh(Wxt+rt⨀Uht−1)
其中 ⨀ \bigodot ⨀是哈达玛集(对应位置元素相乘);
如果重置门的 r t r_t rt权重值为0,则计算出来的 h ^ t \hat h_t h^t忽略前面时刻传入的信息,只保留输入的 x t x_t xt的信息。 -
更新门帮助计算出当前时刻形成的最终的记忆(上一时刻传过来的记忆+当前时刻输入的记忆):
h t = z t ⨀ h t − 1 + ( 1 − z t ) ⨀ h ^ t h_t=z_t\bigodot h_{t-1} + (1-z_t)\bigodot \hat h_t ht=zt⨀ht−1+(1−zt)⨀h^t
更新门的 z t z_t zt的权重值越接近1,则说明最终记忆更依赖于前面时刻传入的记忆;反之,则说明最终记忆更依赖于当前时刻传入的新记忆。
GRU的流程图如下:
4. LSTM(1997)
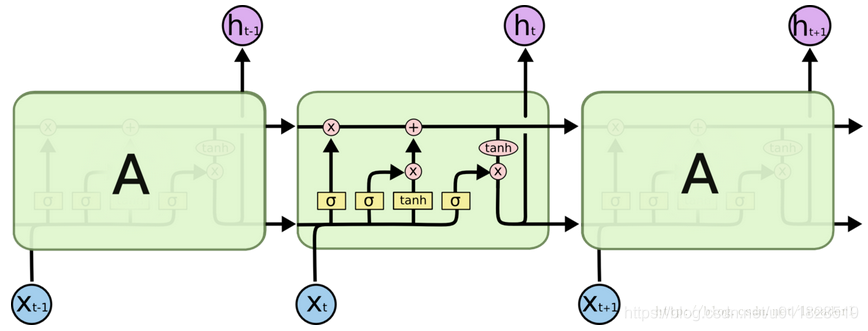
有了GRU,下面我们来介绍其拓展–更加复杂的LSTM(其实GRU是LSTM之后提出的,GRU是在LSTM基础上简化出来的)。
首先看一下LSTM提出的几个门:
(1)输入门(input gate)
i
t
=
σ
(
W
(
i
)
x
t
+
U
(
i
)
h
t
−
1
)
i_t=\sigma(W^{(i)}x_t+U^{(i)}h_{t-1})
it=σ(W(i)xt+U(i)ht−1)
(2)遗忘门(forget gate)
f
t
=
σ
(
W
(
f
)
x
t
+
U
(
f
)
h
t
−
1
)
f_t=\sigma(W^{(f)}x_t+U^{(f)}h_{t-1})
ft=σ(W(f)xt+U(f)ht−1)
(3)输出门(output gate)、
o
t
=
σ
(
W
(
o
)
x
t
+
U
(
o
)
h
t
−
1
)
o_t=\sigma(W^{(o)}x_t+U^{(o)}h_{t-1})
ot=σ(W(o)xt+U(o)ht−1)
以上三个门都是三个0-1权重值的向量;
- 遗忘门:通过此时刻的输入 x t x_t xt和上一时刻出传过来的 h t − 1 h_{t-1} ht−1计算出,上一时刻传过来的cell细胞状态(记忆)要忘掉哪些;比如上一时刻传入的cell记忆中包含主语,而新的输入 x t x_t xt也包含主语,此时就要忘记上一时刻传入的记忆中的主语,其对应的权重值也将变小。
- 输入门:通过此时刻的输入 x t x_t xt和上一时刻出传过来的 h t − 1 h_{t-1} ht−1计算出,此刻输入的信息应该保留哪些;比如上一时刻传入的cell记忆中包含主语,而新的输入 x t x_t xt也包含主语,此时就要记住此刻传入的记忆中的主语,以便代替遗忘门忘掉的主语。
- 输出门:通过此时刻的输入 x t x_t xt和上一时刻出传过来的 h t − 1 h_{t-1} ht−1计算出,此刻输出的信息应该保留哪些;比如,输出判断是一个动词,那么我们需要根据代词是单数还是负数,进行动词的词形变化。
(4)新的细胞状态
c
^
\hat c
c^
c
t
^
=
t
a
n
h
(
W
(
c
)
x
t
+
U
(
c
)
h
t
−
1
)
\hat{c_t}=tanh(W^{(c)}x_t+U^{(c)}h_{t-1})
ct^=tanh(W(c)xt+U(c)ht−1)
通过此时刻的输入
x
t
x_t
xt和上一时刻出传过来的
h
t
−
1
h_{t-1}
ht−1确定细胞状态所存放的新信息
(5)t时刻最终的记忆
c
t
=
f
t
⨀
c
t
−
1
+
i
t
⨀
c
^
t
c_t=f_t\bigodot c_{t-1} +i_t\bigodot \hat c_t
ct=ft⨀ct−1+it⨀c^t
最终记忆=上一时刻传入的记忆(忘掉一些信息后)+此刻形成的新记忆(输入门筛选后)
(6)t时刻输出的隐状态
h
t
=
o
t
⨀
t
a
n
h
(
c
t
)
h_t=o_t\bigodot tanh(c_t)
ht=ot⨀tanh(ct)
我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门
o
t
o_t
ot的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
LSTM流程图如下:
5. 总结
其实站在现在的角度来看,以前做的一些尝试有点傻瓜或者不值得。但是先贤们仍然通过不断的尝试将NLP推进到了现在的这一步,科研可能就是这样,通过不断的尝试,用事实或者结果来说话;就像现在深度学习的效果,虽然很难解释,但是事实证明深度神经网络已经攻占了各个领域,就让我们站在巨人的肩膀上来增加巨人的高度吧~~














 3541
3541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









