







一、理论知识
Seq2Seq模型的基本思想:使用一个循环神经网络读取输入句子,将这个句子的信息压缩到一个固定维度的编码中;再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder),所以也称为 encoder-decoder 模型。
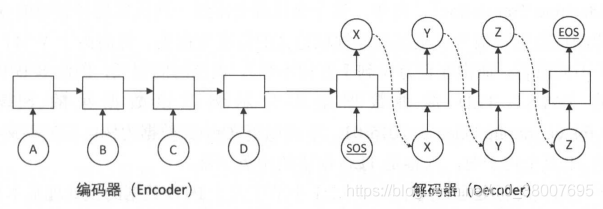
解码器部分的结构与语言模型几乎完全相同:输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为 log perplexity。可以理解为是一个以输入编码为前提的语言模型(Conditional Language Model)。
编码器部分更为简单。与解码器一样拥有词向量层和循环神经网络,但是由于在编码阶段并未输出,因此不需要softmax层。
在训练过程中,编码器顺序读入每个单词的词向量,然后将最终的隐藏状态复制到解码器作为初始阶段。解码器的第一个输入是一个特殊的(Start-Of-Sentence)字符,每一步预测的单词时训练数据的目标句子,预测序列的最后一个单词是与语言模型相同的(End-Of-Sentence)字符。
二、数据的预处理(TED演讲数据集)
转化为单词编号
TED演讲数据集下载地址:http://wit3.fbk.eu/mt.php?release=2015-01 (以英文-中文数据为例)
英文-中文训练数据包含约21万个句子对,内容是TED演讲的中英字幕。
对于数据的预处理,步骤和上一篇文章(TensorFlow学习之LSTM —语言模型(PTB数据集的处理))的预处理基本上是一样的。首先,需要统计预料中出现的单词,为每个单词分配一个ID,将词汇表存入一个 vocab 文件,然后将文本转换为用单词编号的形式来表示。
与上篇文章不同的是,下载的文本没有经过切词。所以首先需要进行切词。切词后的文本我已经上传到百度云盘可进行下载。
链接: https://pan.baidu.com/s/1v0JHJGQg9aYz6uZ0Ihj6Eg
提取码: 7a8c
完成切词后,再使用上篇文章中处理PTB数据相同的方法,分别生成英文文本和中文文本词汇文件,再将文本转化为单词编号。生成词汇文件时,需要注意将<sos>、<eos>、<unk>这三个词手动加入到词汇表中,并且要限制词汇表大小,将词频过低的词替换为 <unk>。相应代码已经上传至GitHub。
填充(padding)和 batching
在PTB数据中,由于句子之间有上下文关联,因此可以直接将连续的句子连接起来成为一个大的段落。而在机器翻译的训练样本中,每个句子对通常时作为独立的数据来训练的。由于每个句子的长短不一致,因此在将这些句子放到同一个batch时,需要将较短的句子补齐到与同 batch 内最长句子相同的长度。用于填充长度而填入的位置叫做填充(padding)。在TensorFlow中,tf.data.Dataset 的 padded_batch 函数提供了这一功能。
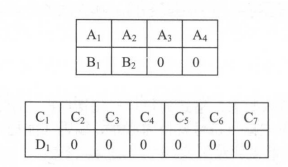
下表给出了一个填充示例。假设一个数据集中有4句话,分别是
“
A
1
A
2
A
3
A
4
”
“
B
1
B
2
”
“
C
1
C
2
C
3
C
4
C
5
C
6
C
7
”
和
“
D
1
”
“A_1A_2A_3A_4” “B_1B_2” “C_1C_2C_3C_4C_5C_6C_7” 和“D_1”
“A1A2A3A4”“B1B2”“C1C2C3C4C5C6C7”和“D1”,将它们加入必要的填充并组成大小为2 的batch后,得到的batch如下图所示:
循环神经网络在读取数据时会将填充位置的内容与其他内容一样纳入计算,因此为了不让填充影响训练,有两方面需要注意:
第一,循环神经网络在读取填充时,应当跳过这一位置的计算。以编码器为例,如果编码器在读取填充时,像正常输入一样处理填充输入,那么在读取
“
B
1
B
2
00
”
“B_1B_200”
“B1B200”之后产生的最后一位隐藏序列就和读取
“
B
1
B
2
”
“B_1B_2”
“B1B2”之后的隐藏状态不同,会产生错误的结果。
TensorFlow提供了 tf.nn.dynamic_rnn 方法来实现这一功能。dynamic_rnn 对每一个batch的数据读取两个输入:输入数据的内容(维度为[batch_size, time])和输入数据的长度(维度为[time])。对于输入batch里的每一条数据,在读取了相应长度的内容后,dynamic_rnn就跳过后面的输入,直接把前一步的计算结果复制到后面的时刻。这样可以保证padding是否存在不影响模型效果。
注意:使用dynamic_rnn时每个batch的最大序列长度不需要相同。例如上面的例子,第一个batch的维度是2x4,而第二个batch的维度是2x7。在训练中dynamic_rnn会根据每个batch的最大长度动态展开到需要的层数,这就是它被称为“dynamic”的原因。
第二,在这几损失函数时需要特别将填充位置的损失的权重设置为0,这样在填充位置产生的预测不会影响梯度的计算。
下面的代码使用 tf.data.Dataset.padded_batch 来进行填充和 batching,并记录每个句子的序列长度以用作dynamic_rnn的输入。与上篇文章PTB的例子不同,这里没有将所有的数据读入内存,而是使用Dataset从磁盘动态读取数据。
import tensorflow as tf
MAX_LEN = 50 # 限定句子的最大单词数量
SOS_ID = 1 # 目标语言词汇表中<sos>的ID
# 使用Dataset从一个文件中读取一个语言的数据。
# 数据的格式为每一句话,单词已经转化为单词编号
def MakeDataset(file_path):
dataset = tf.data.TextLineDataset(file_path)
# 根据空格将单词编号切分开并放入一个一维向量
dataset = dataset.map(lambda string: tf.string_split([string]).values)
# 将字符串形式的单词编号转化为整数
dataset = dataset.map(lambda string: tf.string_to_number(string, tf.int32))
# 统计每个句子的单词数量,并与句子内容一起放入Dataset
dataset = dataset.map(lambda x: (x, tf.size(x)))
return dataset
# 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和batching操作
def MakeSrcTrgDataset(src_path, trg_path, batch_size):
# 首先分别读取源语言数据和目标语言数据
src_data = MakeDataset(src_path)
trg_data = MakeDataset(trg_path)
# 通过zip操作将两个Dataset合并为一个Dataset,现在每个Dataset中每一项数据ds由4个张量组成
# ds[0][0]是源句子
# ds[0][1]是源句子长度
# ds[1][0]是目标句子
# ds[1][1]是目标句子长度
dataset = tf.data.Dataset.zip((src_data, trg_data))
# 删除内容为空(只包含<eos>)的句子和长度过长的句子
def FilterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FilterLength)
# 解码器需要两种格式的目标句子:
# 1.解码器的输入(trg_input), 形式如同'<sos> X Y Z'
# 2.解码器的目标输出(trg_label), 形式如同'X Y Z <eos>'
# 上面从文件中读到的目标句子是'X Y Z <eos>'的形式,我们需要从中生成'<sos> X Y Z'形式并加入到Dataset
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0)
return ((src_input, src_len), (trg_input, trg_label, trg_len))
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据
dataset = dataset.shuffle(10000)
# 规定填充后的输出的数据维度
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([])) # 目标句子长度是单个数字
)
# 调用padded_batch方法进行batching操作
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batched_dataset
三、Seq2Seq模型的代码实现
简单介绍Seq2Seq模型的实现,接下来主要给出 Seq2Seq + Attention 的代码实现。
与上篇文章语言模型相比,Seq2Seq模型的代码主要变化有以下几点:
- 增加了一个循环神经网络作为编码器
- 使用 Dataset 动态读取数据,而不是直接将所有数据读入内存
- 每个 batch 完全独立,不需要在batch之间传递状态
- 每训练200步便将模型参数保存到一个 checkpoint 中。
将训练好的模型保存到checkpoint中,下面讲解怎么样从checkpoint中读取模型并对一个新的句子进行翻译。
在解码器中,需要循环的将上一步的输出作为当前的输入,这个过程需要使用一个循环结构来实现。在TensorFlow中,循环结构是由 tf.while_loop 来实现的。tf.while_loop的使用方法如下:
# cond 是一个函数,负责判断继续执行循环的条件
# loop_bofy 是每个循环体内执行的操作,负责对循环状态进行更新
# init_state 为循环的起始状态,它可以包含多个 Tensor 或者 TensorArray
# 返回的结果是循环结束时的循环状态
final_state = tf.while_loop(cond, loop_body, init_state)
如果使用伪代码来表示运行逻辑的话,那 tf.while_loop的功能与下面的代码相当:
def while_loop(cond, loop_body, init_state):
state = init_state
while(cond(state)) # 使用cond函数判断循环结束条件
state = loop_body(state) # 使用loop_body函数对state进行更新
return state
但是与上面的代码不同的是,tf.while_loop 建立计算图的过程中并没有真的进行循环,而是建立了一个包含循环逻辑的计算节点。在建立计算图的过程中,loop_body函数内的代码只执行一次。
Seq2Seq的实现代码已放在 GitHub上。
四、注意力机制
注意力机制有多种模型:Attention,Multi-head attention,Self-attention。在这里主要讲解比较经典的attention,其他的令出篇章进行讲解。
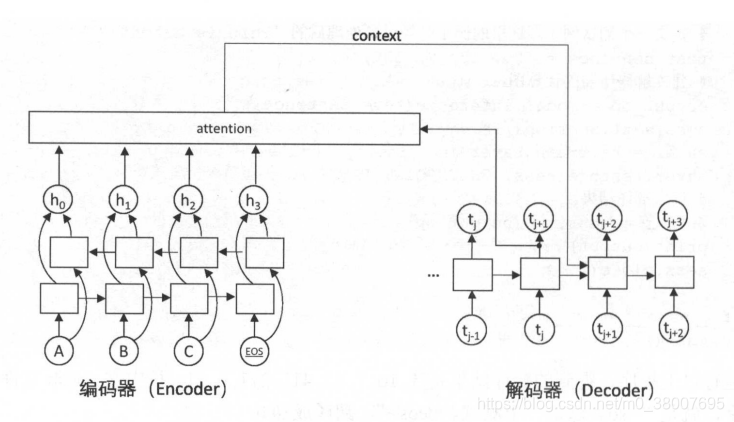
注意力机制允许解码器随时查阅输入句子中的部分单词或片段,因此不再需要在中间向量中存储所有信息。
下图展示了注意力机制的主要框架。
下图是注意力模型中的细节。
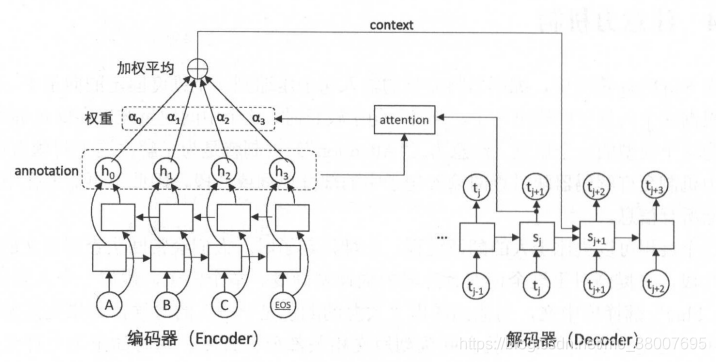
解码器在解码的每一步将隐藏状态作为查询的输入来“查询”编码器的隐藏状态,在每个输入的位置计算一个反映与查询输入相关程度的权重,再根据这个权重对输入位置的隐藏状态求加权平均。加权平均后得到的向量称为“context”,表示它是与翻译当前单词最相关的原文信息。在解码下一个单词时,将context作为额外信息输入到循环神经网络中,这样循环神经网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。
注意力机制的数学定义:
h
i
h_i
hi表示编码器在地
i
i
i个单词上的输出,
s
j
s_j
sj是编码器在预测第
j
j
j个单词时的状态。计算
j
j
j时刻的context的方法如下:
α
i
,
j
=
e
x
p
(
e
(
h
i
,
s
j
)
)
∑
i
e
x
p
(
e
(
h
i
,
s
j
)
)
α_{i,j} = \frac{exp(e(h_i, s_j))}{\sum_i{exp(e(h_i, s_j))}}
αi,j=∑iexp(e(hi,sj))exp(e(hi,sj))
c
o
n
t
e
x
t
j
=
∑
i
α
i
,
j
h
i
context_j = \sum_i{α_{i,j}h_{i}}
contextj=i∑αi,jhi
其中
e
(
h
i
,
s
j
)
e(h_i, s_j)
e(hi,sj)使计算原文各单词与当前解码器状态的“相关度”函数。最常用的
e
(
h
,
s
)
e(h, s)
e(h,s)函数定义是一个带有单个隐藏层的前馈神经网络:
e
(
h
,
s
)
=
U
t
a
n
h
(
V
h
+
W
s
)
e(h,s) = Utanh(Vh + Ws)
e(h,s)=Utanh(Vh+Ws)
其中 U,V,W是模型的参数,
e
(
h
,
s
)
e(h,s)
e(h,s)构成了一个包含一个隐藏层的全连接神经网络。这个模型时第一次提出注意力机制的论文中采用的模型(此处的相似度函数使用的感知机)。
除此之外,注意力机制还有多种其他设计:点积、拼接。无论相似度函数采用哪个模型,通过softmax计算权重α和通过加权平均计算context的方法都是一样的。
在计算得到第j步的context向量之后,context被加入到 j+1 时刻作为循环曾的输入。
Seq2Seq模型与Attention模型的区别:
第一:编码器采用了一个双向循环网络。这样编码器通过注意力查询一个单词时,可以同时包含左右两侧的信息。
第二:取消了编码器和解码器之间的连接,解码器完全依赖与注意力机制获取原文信息。取消这一连接使得编码器和解码器可以自由选择模型。
TensorFlow实现注意力机制
注意力机制的实现较为复杂。TensorFlow提供了几种预置的实现。tf.contrib.seq2seq.AttentionWrapper 将解码器的循环神经网络和注意力层结合,成为一个更高层的循环神经网络。每一步计算的 context 在相邻解码步骤之间的传递,可以视为一个隐藏状态在相邻时刻之间的传递。将注意力机制封装成循环神经网络后,就可以了使用 dynamic_rnn 调用新的包含注意力的循环神经网络。
由于代码量大,所以Attention机制的实现代码已经上传至GitHub上。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











