






来自百度、谷歌搜索:
1、Softmax vs. Softmax-Loss: Numerical Stability
本文对这段文字The softmax loss layer computes the multinomial logistic loss of the softmax of its inputs. It’s conceptually identical to a softmax layer followed by a multinomial logistic loss layer, but provides a more numerically stable gradient.的闲聊。中心思想是:在数值计算(或者任何其他工程领域)里,知道一个东西的基本算法和写出一个能在实际中工作得很好的程序之间还是有一段不小的距离的。
caffe 是一个很常用的 C++/CUDA 的 Deep Convolutional Neural Networks (CNNs) (深度卷积神经网络)的库。
经典的 Deep Neural Networks 顶层其实本来也就是一个 Logistic Regression (逻辑回归)分类器。
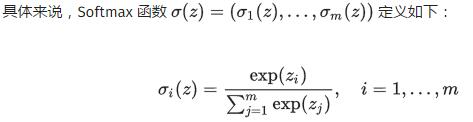
作用是将线性预测值转化为类别概率。
如果是在设计 Deep Neural Networks 的库,则可能会倾向于将两者分开来看待:因为 Deep Learning 的模型都是一层一层叠起来的结构,一个计算库的主要工作是提供各种各样的 layer,然后让用户可以选择通过不同的方式来对各种 layer 组合得到一个网络层级结构就可以了。比如用户可能最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax Layer,而不一定要进行 Multinomial Logistic Loss 操作;或者是用户有通过其他什么方式已经得到了某种概率似然值,然后要做最大似然估计,此时则只需要后面的 Multinomial Logistic Loss 而不需要前面的 Softmax 操作。因此提供两个不同的 Layer 结构比只提供一个合在一起的 Softmax-Loss Layer 要灵活许多。
这里自然地就出现了一个问题:numerical stability(算法的数值稳定性实验)
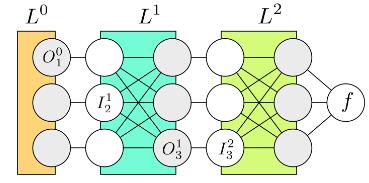
对于普通的神经网络,通常每一层进行的计算都是一个线性映射再经过一个 sigmoid 的非线性操作S,例如:
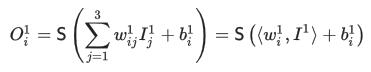
后面是写成向量/矩阵的形式,一般会显得更简洁。现在如果要对参数
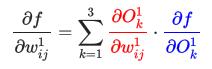
同样地,根据 Chain Rule 我们可以计算:

计算出来的将会作为
传递到
层,整个过程就叫做 Back Propagation(反向传播),其实说白了就是 Chain Rule,只是涉及的符号有点多,容易搞混淆。
本文介绍介绍TensorFlow中模型的基本组成部分,同时将构建一个CNN(卷积神经网络)模型来对MNIST数据集中的数字手写体进行识别。
文中讲到MNIST手写体识别任务,”这个任务相当于是机器学习中的HelloWorld程序“。MNIST数据集一共包含三个部分:训练数据集(55,000份,mnist.train)、测试数据集(10,000份,mnist.test)和验证数据集(5,000份,mnist.validation)。一般来说,训练数据集是用来训练模型,验证数据集可以检验所训练出来的模型的正确性和是否过拟合,测试集是不可见的(相当于一个黑盒),但我们最终的目的是使得所训练出来的模型在测试集上的效果(这里是准确性)达到最佳。一张图片是一个28*28的像素点矩阵,我们可以用一个同大小的二维整数矩阵来表示。如下:
这里我们可以先简单地使用一个长度为28 * 28 = 784的一维数组来表示图像,因为下面仅仅使用softmax regression(Softmax回归)来对图片进行识别分类(尽管这样做会损失图片的二维空间信息,所以实际上最好的计算机视觉算法是会利用图片的二维信息的)。所以MNIST的训练数据集可以是一个形状为55000 * 784位的tensor,也就是一个多维数组,第一维表示图片的索引,第二维表示图片中像素的索引(”tensor”中的像素值在0到1之间)。
词向量的编码方式其实挺有讲究的。最简单的编码方式叫做one-hot vector:假设我们的词库总共有n个词,那我们开一个1*n的高维向量,而每个词都会在某个索引index下取到1,其余位置全部都取值为0。词向量在这种类型的编码中如下图所示:图9991
在”Softmax Regression模型“部分讲到:
Softmax Regression是一个简单的模型,很适合用来处理得到一个待分类对象在多个类别上的概率分布。所以,这个模型通常是很多高级模型的最后一步。
Softmax Regression大致分为两步(暂时不知道如何合理翻译,转原话):
Step 1: add up the evidence of our input being in certain classes;
Step 2: convert that evidence into probabilities.
梯度下降是一个简单的计算方式,即使得变量值朝着减小代价函数值的方向变化。TensorFlow也提供了许多其他的优化算法,仅需要一行代码即可实现调用。
接下来,进行模型的训练。每一次的循环中,我们取训练数据中的100个随机数据,这种操作成为批处理(batch)。然后,每次运行train_step时,将之前所选择的数据,填充至所设置的占位符中,作为模型的输入。以上过程成为随机梯度下降,在这里使用它是非常合适的。因为它既能保证运行效率,也能一定程度上保证程序运行的正确性。(理论上,我们应该在每一次循环过程中,利用所有的训练数据来得到正确的梯度下降方向,但这样将非常耗时。)
怎样评价所训练出来的模型?显然,我们可以用图片预测类别的准确率。利用tf.argmax()函数来得到预测和实际的图片label值,再用一个tf.equal()函数来判断预测值和真实值是否一致。
文章给出了利用Softmax模型实现手写体识别的完整代码:
__author__ = 'chapter'
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
print("Download Done!")
x = tf.placeholder(tf.float32, [None, 784])
# paras
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
# loss func
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# init
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# train
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuarcy on Test-dataset: ", sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.initialize_all_variables())for i in range(20000):
batch = mnist.train.next_batch(50) if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={ x:batch[0], y_: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})print("test accuracy %g"%accuracy.eval(feed_dict={ x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))最终,模型在测试集上的准确率大概为99.2%,性能上要优于之前的Softmax Regression模型。
3、Google Deep Learning Notes(TensorFlow教程)
TensorFlow教程06:MNIST的CNN实现——源码和运行结果
Tensorflow | CNN |卷积神经网络入门| MNIST
[译]与TensorFlow的第一次接触(五)之多层神经网络
TensorFlow人工智能引擎入门教程之二 CNN卷积神经网络的基本定义理解
TensorFlow 03: MNIST and CNN(英文)
LSTM language model with CNN over characters in TensorFlow
vrv committed with tensorflower-gardener Merge changes from github
更多未完待续……















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









