







论文地址:arxiv-paper
实现代码:github
Introduction
DenseNet在ResNet的基础上(ResNet介绍),进一步扩展网络连接,**对于网络的任意一层,该层前面所有层的feature map都是这层的输入,该层的feature map是后面所有层的输入。**示意图如下:

原本 L L L层的网络有 L L L个连接,现在 L L L层的网络共有 C L + 1 2 = L ( L + 1 ) 2 C_{L+1}^2=\frac{L(L+1)}{2} CL+12=2L(L+1)个连接。
DenseNet有几个明显的优点:
- 减轻了梯度消失问题(vanishing-gradient problem)
- 增强了feature map的传播,利用率也上升了(前面层的feature map直接传给后面,利用更充分了)
- 大大减少了参数量
Related Work
在CNN模型里,传统的feed-forward架构可以视为状态模型,状态在层与层之间传播,每一层读取它上一层状态,改变状态并保留一些需要保留的信息并将装备传给下一层。ResNet通过增加额外的identity transformations让状态内需要保留的信息显性化。作者的另一篇paper指出ResNet中有一个非常有意义的现象:网络的许多层贡献较小并且在训练过程中可以被随机丢弃。
这里引用Lyken的回答,分析ResNet,其gradient的主要来源是residual分支;在测试过程中,即便移除掉正常链接(仅留下 shortcut),模型照样能保持较好的正确率。
本论文指出了residual connection实质是 highway network 的一种特殊例子,将 ResNet 展开以后,论文1指出带 Residual Connection 的深网络可以“近似地”看作宽模型(印证了为什么移除主干连接不会大幅影响正确率)。
ResNet再分析
但是ResNet和真正的宽模型还是不同的:Forward 时两者可以看做相同,但 backward 时有部分 gradient 路径无法联通。也就是说, ResNet 在回传 gradient 时,尚有提升的空间,这就是为什么 ResNeXt,Wide-ResNet 等文章能有提升的原因:因为 ResNet 并不是真正的宽模型。
以ResNet中一个Residual unit的gradient回传为例,示意图如下:
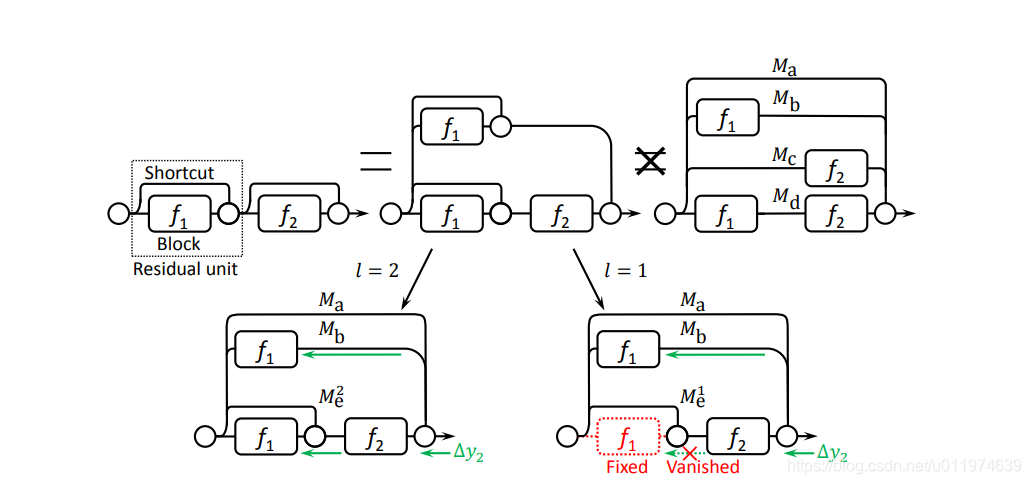
KaTeX parse error: No such environment: align at position 7: \begin{̲a̲l̲i̲g̲n̲}̲ y_2 &= y_1+f_2…
注意上式的不等于,为什么backward的部分gradient路径无法联通?这是因为 f 2 ( ⋅ ) f_2(·) f2(⋅)是非线性的,即变现为 f 2 ( y 0 + f 1 ( y 0 , w 1 ) , w 2 ) ≠ f 2 ( y 0 , w 2 ) + f 2 ( f 1 ( y 0 , w 1 ) , w 2 ) f_2(y_0+f_1(y_0,w_1),w_2)≠ f_2(y_0,w_2)+f_2(f_1(y_0,w_1),w_2) f2(y0+f1(y0,w1),w2)̸=f2(y0,w2)+f2(f1(y0,w1),w2)。
DenseNet的Insight
既然 Residual Connection 能够让模型趋向于宽网络,那么为什么不直接来个狠得,这就是 Densenet论文核心思想:对每一层的前面所有层都加一个单独的 shortcut到该层,使得任意两层网络都可以直接“沟通”。即下图:

这一举看似粗暴,实则带来不少好处:
- 从feature来考虑,每一层feature 被用到时,都可以被看作做了新的 normalization,论文3可以看到即便去掉BN, 深层 DenseNet也可以保证较好的收敛率。
- 从perceptual field来看,浅层和深层的field 可以更自由的组合,会使得模型的结果更加robust。
- 从 wide-network 来看, DenseNet 看以被看作一个真正的宽网络,在训练时会有比 ResNet 更稳定的梯度,收敛速度自然更好(paper的实验可以佐证)
DenseNet
记模型的输入图片为 x o x_o xo,模型由 L L L层组成,每层的非线性转换函数为 H l ( ⋅ ) H_l(·) Hl(⋅), l l l是层的序号。将 l t h l^{th} lth层的输出记为 x l x_l xl。
Dense connectivity
DenseNet中每层的输入是前面的所有层,故任何两层之间都有连接。但在实际情况下,因为多层之间feature maps大小不同,不便于任何两层之间的组合,受到GoogleNet的启发,**论文提出了Dense Block,即在每个Block内,所有layer都保持dense connectivity,而在Block之间是没有dense connectivity,而是通过transition layer连接的。**如下图:

Composite function
即单个Block内,层与层之间的非线性转换函数
H
l
(
⋅
)
H_l(·)
Hl(⋅)就是Composite function,,每个Composite function的结构如下:
B
N
→
R
e
L
U
→
C
o
n
v
(
3
×
3
)
BN \rightarrow ReLU \rightarrow Conv_{(3×3)}
BN→ReLU→Conv(3×3)
Transition layer
不同层的feature map大小不同,考虑到池化层在CNN模型内的重要性,提出一个Transition layer用于连接Block与Block,每个Transition layer的结构如下:
B
N
→
C
o
n
v
(
1
×
1
)
→
A
v
g
P
o
o
l
(
2
×
2
)
BN \rightarrow Conv_{(1×1)} \rightarrow Avg \ \ Pool_{(2×2)}
BN→Conv(1×1)→Avg Pool(2×2)
Growth rate
如果一个 H l H_l Hl输出 k k k个feature maps,那么 l t h l^{th} lth层有 k 0 + k × ( l − 1 ) k_0+k×(l-1) k0+k×(l−1)个feature maps输入。 k 0 k_0 k0是输入层的通道数。如果 k k k太多,即feature map太多,从而导致模型参数太多。这里我们定义Growth rate就是超参数 k k k,用于控制feature maps的数量。
DenseNet-BC
Bottleneck layers
尽管每层只产生
k
k
k个feature maps,但还是很多。**这里就要用到
1
×
1
×
n
1×1×n
1×1×n的小卷积来降维了。**作者发现在DenseNet上使用
1
×
1
×
n
1×1×n
1×1×n小卷积很有效,并定义了Bottleneck layers,结构如下:
B
N
→
R
e
L
U
→
C
o
n
v
(
1
×
1
)
→
B
N
→
R
e
L
U
→
C
o
n
v
(
3
×
3
)
BN \rightarrow ReLU \rightarrow Conv_{(1×1)} \rightarrow BN \rightarrow ReLU \rightarrow Conv_{(3×3)}
BN→ReLU→Conv(1×1)→BN→ReLU→Conv(3×3)
并将使用Bottleneck layers的DenseNet表示为DenseNet-B。(在paper实验里,将 1 × 1 × n 1×1×n 1×1×n小卷积里的 n n n设置为 4 k 4k 4k)
Compression
考虑到feature maps的数量多,为了进一步的提高模型的紧凑性,我们可以在transition layers上下手,如果Dense Block内包含 m m m个feature maps,那么可以通过transition layers减少feature maps。
这里让transition layers输出 ⌊ θ m ⌋ \left \lfloor \theta m \right \rfloor ⌊θm⌋个feature maps,这样就能通过控制参数 θ \theta θ来控制feature maps的数量了。我们把参数 θ \theta θ定义为compression factor。
一般 0 < θ < 1 0<\theta<1 0<θ<1,在paper的实验中, θ = 0.5 \theta=0.5 θ=0.5,使用compression factor的DenseNet记为DenseNet-C。同时使用compression factor 和 Bottleneck layers的DenseNet记为DenseNet-BC。
Implementation Details
非ImageNet数据集
- 使用3个Dense Block
- 每个Block都有相同的层数
- 模型为DenseNet,配置为 { L = 40 , k = 12 } , \{L=40,k=12\}, {L=40,k=12}, { L = 100 , k = 12 } , \{L=100,k=12\}, {L=100,k=12}, { L = 100 , k = 24 } \{L=100,k=24\} {L=100,k=24}
- 模型为DenseNet-BC,配置为 { L = 100 , k = 12 } , \{L=100,k=12\}, {L=100,k=12}, { L = 250 , k = 24 } , \{L=250,k=24\}, {L=250,k=24}, { L = 190 , k = 40 } \{L=190,k=40\} {L=190,k=40}
- 在送入第一个Dense Block前,会先送到一个16通道的卷积层
- 使用 3 × 3 3×3 3×3的小卷积,采用zero-padding保持feature map尺寸
- 最后一个Dense Block后接一个global average pooling,再跟softmax分类。
ImageNet数据集
-
使用的是DenseNet-BC
-
使用4个Dense Block
-
在送入第一个Dense Block前,会先送到一个 7 × 7 × 2 k 7×7×2k 7×7×2k的 s t r i d e = 2 stride=2 stride=2的卷积层
-
所有的layers的feature map都设置为 k k k
在ImageNet上,具体的DenseNet-BC如下图:

Experiments
Training Details
所有的网络都是使用SGD训练的,具体的batch和learning rate设置如下:
| 数据集 | description |
|---|---|
| CIFAR and SCHN | batch size 64 for 300 and 40 epochs learning rate初始设置为0.1,在epoch执行到50%和75%的时候降低10倍 |
| ImageNet | batch size 256 for 90 epochs learning rate初始设置为0.1,在epoch执行到30和60的时候降低10倍 |
| DenseNet-161 考虑到GPU显存问题 | mini-batch size 128 for 100 epochs learning rate初始设置为0.1,在epoch执行到90的时候降低10倍 |
| 其他设置 | description |
| weight decay | 1 0 − 4 10^{-4} 10−4 |
| Nesterov momentum | 0.9 |
| dropout | 在C10,C100,SVHN上,没有使用data augmentation,则在每个卷积层后添加dropout layer(除了第一个),并设置为0.2 |
实验结果
DenseNet在CIFAR和SVHV上的表现如下:

L L L表示网络深度, k k k为growth rate。蓝色字体表示最优结果, + + +表示对原数据库进行data augmentation。DenseNet相比ResNet取得更低的错误率,且参数更少。
DenseNet在ImageNet上的表现如下:

可以看到DenseNet相比于ResNet有着更少的参数,更好的测试结果。
Conclusion
DenseNet的优点在前面讲过了,总结的来说就是Feature Reuse,模型Robustness。这里主要关注DenseNet的缺点。
DenseNet 的缺点

在图中可以看到,DenseNet-100层增长率为24时(无BottleNeck的最早版),parameter快要是ResNet-1001的三倍了。一般显卡根本塞不下更深的DenseNet。在不断的优化后,DenseNet 的显存问题已大有改善。
但Flops消耗问题仍令人头疼。本来 DenseNet 的实时性尚还可以(拓扑序跟普通网络一样),但由于其过多的Dense 的num_filters,计算量就超过了很多卡的上限。为了优化这两个问题,论文中采用了bottleneck和compression来大幅压缩filters数目。(将DenseNet实用–>bengio组的DenseNet for segmentation )
为什么会很耗费显存
引用taineleau的回答。首先,无论是什么 framework的NN,都由forward和backward两部分构成。假设只考虑一个 feed-forward network,并且移除所有 in-place 操作(如 ReLU),那么内存依赖大概是这个样子的:

i n p u t i = f w i ( i n p u t i − 1 ) g r a d I n p u t i = b w i ( i n p u t i − 1 , g r a d I n p u t i + 1 ) input_i = fw_i(input_{i-1}) \\ gradInput_i = bw_i(input_{i-1}, gradInput_{i+1}) inputi=fwi(inputi−1)gradInputi=bwi(inputi−1,gradInputi+1)
对于 Backward 来说,深红色的 g r a d I n p u t gradInput gradInput算完一块就可以扔掉(它的出度为1),这也是几乎所有16 年以后新framework都会做的 shareGradient 优化。
但是浅红色的内存块因为要在backward的时候还会被用到,所以不能扔,那肿么办?[1] 说可以用时间换空间,即在需要用粉红块的时候,重新计算即可。而对于 DenseNet 来说,每个 DenseLayer (Concat-BN-ReLU-Conv),Concat 和 BN 两层的 output 全扔掉就可以省下很多内存,却只多花了 15% 的计算量。

现在已经整理出来的干净代码有 Torch 版本,见PyTorch版,有不同 level 的优化,最多能省 70% 的显存。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









