







语音预习矫正汉语拼写错误
张瑞清,庞超,张传强,王朔欢,何忠军、孙宇、吴华和海峰[1]
百度公司。中国北京上地10号街10号,100085{张瑞青奥尔,庞曹04,张川强,王寿环}@http://baidu.com{Hezhongjun, sunyu02, Wu_hua, wanghaifeng}@http://baidu.com
摘要
中文拼写改正(CSC)是一项重要而富有挑战性的任务。现有的最先进的方法要么只使用预先训练的语言模型,要么将语音信息作为外置词知识。本文提出了一种新的端到端汉语拼写改正方法(CSC)模型,利用强大的预训练和微调方法,将语音特征整合到语言模型中。在训练语言模型中,我们用语音特征和语音相似词来代替传统的特殊标记来掩蔽词。我们提出了一个自适应加权目标来联合训练误差检测和校正。实验结果表明,我们的模型对SIGHAN数据集有显著的改进,优于以往的先进方法。
导言
拼写错误在实践中很常见,并且在下游任务中将会加大错误。因此,拼写校正对于许多NLP应用是重要的,诸如搜索优化(Martins和Silva,2004;Gao等,2010)、机器翻译(Belinkov和Bisk,2017)、词性标记(Van Rooy和Schafer,2002;Sak-aguchi等,2012)等。拼写纠正需要全面掌握单词相似性、语言建模和推理,使其成为NLP中最具挑战性的任务之一。
本文主要研究汉语拼写改正(CSC)。与字母语言不同,如果没有输入系统:例如汉语拼音(基于发音的输入方法)或自动语音识别(ASR)的帮助,汉字就不能被输入。因此,类似发音的字符打字经常出现在中文文本中。据Liuet ai(2010)称,网上83%的中文拼写错误来自
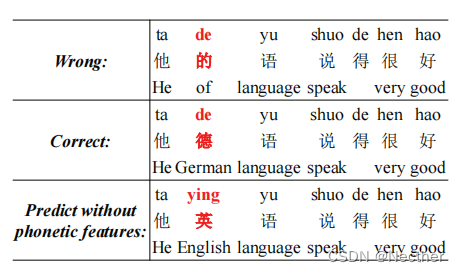
图1:中文拼写校正(CSC)的一个例子。每行包含三行,汉语拼音,汉字和光泽。汉字“德(de, Gennan)被错误地打成同音字“的(de, of)”。汉语拼写改正(CSC)模型不考虑语音的相似性,而是用“英(ying, English)”代替汉字,产生一个流利、错误的句子。
音韵上相似的字符。如图1所示,字符“德(de, German)”被错误地输入为其同音字“的(de, of)”。[2]
传统的中文拼写纠正方法(CSC)首先检测拼写错误字符,并通过语言模型生成候选,然后使用语音模型或规则来过滤错误的候选(Chang,1995;Chen等,2013;Dong等,2016)。为了提高汉语拼写改正(CSC)的性能,主要研究两个问题:1)如何改进语言模型(Wu et ai, 2010; Dong et ai, 2016; Zhang et ai, 2020)和2)如何利用语音相似性的外部知识(Jiaet ai, 2013; Yu and Li, 2014; Wang et ai, 2018; Cheng et ai, 2020)。语言模型用于生成流畅的句子,语音特征可以防止模型产生发音偏离原词的预测。如图1所示,原“错误”句包含一个不正确的词“的(de, of)”。中文拼写改正(CSC)模式将“的(de,of)”改为“英(ying,english)”。然而,这两个词的发音是完全不同的,因为模型忽略了语音特征。
2250
计算语言学协会的发现:ACL-IJCNLP 2021。第2250-2261页
计算语言学协会
最近的研究使用深层神经网络来解决这个问题。Hong et ai.(2019)使用预先训练的语言模型BERT(Devlin et ai.,2019)来生成候选并训练具有语音特征的分类器来选择最终校正。Wang et ai.(2019)将汉语拼写校正(CSC)看作一个sequence-to-sequence任务,并且从混淆集2而不是整个词汇表生成候选。这些方法以语音信息为外在知识,但离散的候选选择阻碍了语言模型通过反向传播直接学习。Zhang et ai(2020)通过修改BERT的掩码机制,提出了一个端到端的中文拼写纠正(CSC)模型。然而,他们没有使用任何语音信息,这对于探索词汇相似性很重要。
本文提出了一种新的汉语拼写改正端到端模型。该模型将语音信息融合到语言模型中,并利用了训练前和精调框架。具体来说,我们首先修改预训练掩蔽语言模型的学习任务(Devlin等,2019)。我们不用不分青红皂白的符号“[MASK]”代替字符,而是用拼音或类似的读音字符来掩盖字符。这使得语言模型能够探索字符与拼音之间的相似性。然后,我们利用两个网络的模型对纠错数据进行微调,检测网络预测每个单词的拼写错误概率,并且校正网络通过将单词嵌入和拼音嵌入与概率融合作为输入来生成纠错。我们在统一的框架下联合优化检测和校正网络。
本文件的贡献概述如下:
本文提出了一种将语音特征融入语言表达的端到端汉语拼写改正模型。该模型在共享空间中对汉字和拼音符号进行编码。
语音信息的集成极大地促进了汉语拼写改正(CSC)。在基准SIGHAN数据集上的实验结果表明,我们的方法明显优于以前的先进方法。
相关工作
关于中文拼写校正(CSC)的较早工作遵循错误检测、候选者生成和候选者选择的流水线(Wu et ai.,2010;Jiaet ai.,2013;Chen et ai.,2013;Chiu et ai.,2013;Liu et ai.,2013;Xin et ai.,2014;Yu and Li,2014;Dong et ai.,2016;Wang et ai.,2018)。这些方法主要采用无监督的语言模型和规则来选择候选者。
随着端到端网络的发展,一些工作提出了将纠错性能直接优化为具有条件随机场(CRF)(Wuet ai,2018)和递归神经网络(RNN)(Zheng et ai,2016;Yang et ai,2017)的序列标记任务。Wang et ai(2019)使用具有复制机制的顺序到顺序框架来直接从为错误单词准备的混淆集复制校正结果。Cheng et ai(2020)在BERT之上建立了图卷积网络(GCN)(Devlin et ai.,2019),并且该图由混淆集构造。Zhang et ai(2020)提出了一种软掩蔽BERT模型,该模型首先预测每个单词的拼写错误概率,然后利用该概率进行软掩蔽单词嵌入校正。然而,他们没有使用任何语音信息。
我们的工作与张爱玲(2020)最相关,但有一些重要的差异。我们将在第3.4节中进一步讨论这个问题。
方法:方法
形式上,中文拼写改正任务是将包含拼写错误的序列xw = (xw1 , xw2 , …, xwN )映射到另一个正确的序列 y = (yˆ1, yˆ2, …, yˆN )其中xwi和yˆi (1 ≤ i ≤ N)均为汉字。
本文提出了一种由检测与校正两部分组成的端到端汉语拼写校正模型。检测模块将xw作为输入,并预测每个字符的拼写错误的概率。校正模型以xw的嵌入及其对应的拼音序列xp = (xp1 , xp2 , …, xpN )的组合作为输入,并预测正确的序列y。我们提出了一种使用拼写错误概率作为权重来融合xw和xp的嵌入向量(Embeddings)的方法。
遵循预训练和微调框架,
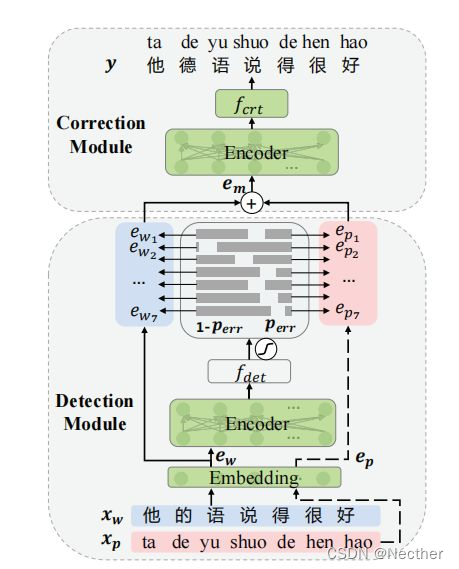
图2:我们中文拼写校正(CSC)模型的说明。给定输入字序列xw,检测模块首先预测所有字符的错误概率perr。然后,校正模块将字嵌入ew和拼音嵌入ep结合到嵌入融合em,并发送它以产生最终校正y。嵌入、编码器和frt的参数通过具有语音特征的预先训练的语言模型来初始化。两个编码器的结构和参数相同。
我们首先通过学习从类似发音的字符和拼音中预测原字符,来预训练一个MASK语言模型:MLM-phonetics(MLM-发音)。然后在微调中,联合优化检测和校正模块。
在本节中,我们首先介绍了模型结构(Sec.3.1),优化方法(Sec.3.2)以及MLM-phonetics的预训练(Sec.3.3)然后总结我们方法的新颖性(第3.4节)。
模型体系结构
图2显示了我们的模型结构,下面是错误检测模块,上面是校正模块。两者都建立在transformer上。
错误检测模块:给定序列xw = (xw1 , xw2 , …, xwN ),错误检测模块的目标是检查一个字符xwi (1 ≤ i ≤ N)是否正确。对于这个标记问题,我们使用标签1和0来分别标记拼写错误的字和正确的字。
我们将检测模块形式化如下:
yd = softmax(fdet(E(ew))) (1)
其中ew = (ew1 , ew2 , …, ewN )是xw的字嵌入,E是预先训练的编码器,并且fdet是将语句表示映射到二进制序列yd = (yd1 , yd2 , …, ydN ), ydi ∈ {0, 1}的全连接层。
我们使用perri表示字符xwi是错误的概率:
perri = p(ydi = 1|xw; θd) (2)
其中θd是错误检测模块的参数。
校正模块:校正模块的目的是根据检测模块的输出生成正确的字符。我们不仅使用单词嵌入来输入,而且使用拼音嵌入来整合语音信息。具体而言,我们喜欢使用PyPinyin工具生成拼音序列xp,从嵌入层获得拼音嵌入ep,并通过线性组合将其与单词嵌入ew融合:
em = (1 − perr) · ew + perr · ep (3)
该组合使用检测模块预测的拼写错误概率作为权重来平衡语义特征(字符嵌入)和语音特征(拼音嵌入)的重要性。我们介绍了两个特殊情况:如果perri = 0,则表示检测到字符xwi是正确的,并且模型只使用其字嵌入em。如果perri = 1,意味着检测到字符是错误的,并且模型使用其拼音嵌入。
最后,通过完全连接层fcrt,预测校正结果y:
y = sof tmax(fcrt(E(em))) (4)
注意,嵌入的参数、编码器E和校正网络fcrt由MLM-phonetics初始化。在预修中,对MLM-phonetics进行训练,从常混淆的对应词和拼音中重构正确的字符,从而用融合嵌入进行变换。
联合微调
我们的模型有两个目标:训练检测参数fdet,调整检测和校正模块,以达到最佳平衡。我们共同优化检测损失Ld和校正损失Lc,即:
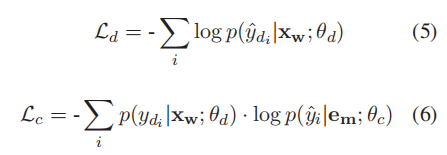
其中θd和θc分别是检测和校正模块的参数,yˆdi是实际真实的检测结果并且是检测模块的预测,它们都是0或1的二值值。
特别地,校正损失是通过检测结果的概率p(ydi |xw; θd) ∈ (0.5, 1]加权的负对数似然度,这是为了区分两个任务的责任。当检测模块给出低置信度预测,即p(ydi |xw; θd)接近0.5时,它们用相似权重融合语义I和语音特征。但是,我们希望检测模块能够提供对或错的明确判断,即p(ydi |xw; θd)接近1,使得它们可以由语义特征或语音特征控制。在这种情况下,错误词的改正将不会受到em中的语义特征的干扰,反之亦然。因此,我们惩罚由检测模块给出的低置信度预测。具体地,当检测结果的概率低时,Lc减小,并且模型将更加关注于优化Ld而当检测概率高时,模型平衡地优化Lc和Ld。
自适应加权目标使我们能够用两个损失函数之和共同训练我们的模型:
L = Ld + Lc (7)
在实验中,我们比较了不同的加权策略和自适应加权。
预训练模型MLM-phonetics
在本节中,我们介绍了我们的预先训练的语言模型,MLM-phonetics,1)整合语音特征,2)解决标准掩蔽语言模型在我们的汉语拼写纠正(CSC)结构中使用的问题。
预训练和微调框架(Devlin et ai.,2019)已被证明有效地促进下游NLP任务,包括句子分类、问答等。而汉字拼写改正(CSC)中的输入句与预训练样本的差异较大。到目前为止,有些工作通过避免将错误句子直接输入到预先训练的模型来避免输入分歧。例如,Zhang et ai(2020)在基于BERT的校正网络之前使用双向GRU进行错误检测。
为了充分利用预训练的技术,我们修改了预训练的任务。在标准掩蔽语言模型(MLM-base)的预训练中,通过预测15%的随机选择字符来训练模型,这些字符被[MASK]标记、随机字符和自身来代替,采样率分别为80%、10%和10%。
为了避免输入发散和综合语音特征,我们提出了两种预训练替代方法:混淆汉字和噪声拼音。我们使用图3来说明这些替换:[3]
[MASK]替换通过仅根据上下文恢复掩蔽字符来训练语言模型的推理能力。
随机汉字替换训练MLM-base来从随机单词中纠正单词(例如,从“不(bu)”中预测“得(de)”),这比从类似发音的字符中纠正更困难。然而,由于输入分布的不同,这种策略对汉语拼写改正效果不大。
相同的替换鼓励MLM-base复制输入字符(例如,替换“好(hao)”)。
混淆-汉字替换训练MLM-phonetics,以纠正其混淆集合中常见的混淆字符(例如,把“豪(hao)”预测成 “好(hao)”)。它为模型提供了纠正打字错误的样本的方法。
声拼音替换训练MLM-phonetics,从易混淆拼音的字符中预测原始字符(例如:从“de”预测“得(de)”)

图3:MLM基础和MLM语音的不同替换策略的示例。
它有助于用相应的拼音标记聚类类似发音的字符。
前三个替换用于标准MLM-base预处理,后两个替换用于模拟字符与拼音符号之间的相似性。在MLM-phonetics预处理中,我们的数据生成器随机选择训练样本中20%的令牌位置。如果第i th令牌被选择,我们经验性地将其替换为(1)40%概率[MASK]令牌,(2)30%概率替换为该令牌的噪声拼音,以及(3)30%概率替换为来自其混淆集的混淆汉字。然后对MLM语音进行训练,用替换词预测原句。[4]
两个训练前任务可以消除训练前与精调汉语拼写改正(CSC)模型之间的输入偏差。Confuse-Hanzi替换模拟检测模块的输入,并且两个替换一起便于预训练的模型适应融合嵌入(等式3)。
我们方法的新颖性
我们的方法最与张爱玲(2020)有关,但在以下几个方面不同。
首先,我们的模型结合了拼音和字符的嵌入来防止信息丢失,这更像是用问题词的发音来预测纠正的人类纠正过程。相反,Zhang et ai(2020)在发出线性校正之前必须添加残差连接,否则在将错误词的嵌入与[MASK]结合之后将忘记错误词的语音信息,
第二,我们提出新的预处理任务,共享预训练编码器的检测和校正,而张艾(2020)在检测中采用了未经预训练的双向GRU,以避免预训练和微调之间的输入偏差。
第三,提出了一种自适应加权策略来联合训练错误检测和纠正。该策略鼓励模型产生清晰的检测结果,使得融合嵌入由语义特征或语音特征主导,这接近于训练前的任务。相反,Zhang et ai(2020)提出将检测和校正损失与固定超参数线性组合。
实验
我们在SIGHAN数据集上进行了实验,这是一个用于中文拼写校正(CSC)的基准。
数据处理
训练集由两部分组成:1)30亿个汉语句子的预修语料库; 2)281K个句子对的汉语拼写纠正训练语料库。第一个语料库用于MLM语音的预训练,后者用于微调MLM语音初始化的汉语拼写纠正(CSC)模型。
对于培训前的语料库,我们从搜索引擎收集各种数据,如百科全书文章、新闻、科学论文和电影字幕。在我们的实验中使用的中文拼写校正(CSC)训练数据与Wang et ai(2019)和Cheng et ai(2020)相同,包括三个人工注释训练数据集(Wu et ai,2013;Yu et ai,2014;Tseng et ai,2015)以及利用Wang et ai(2018)中提出的方法自动生成的数据集。[5]
模型设置
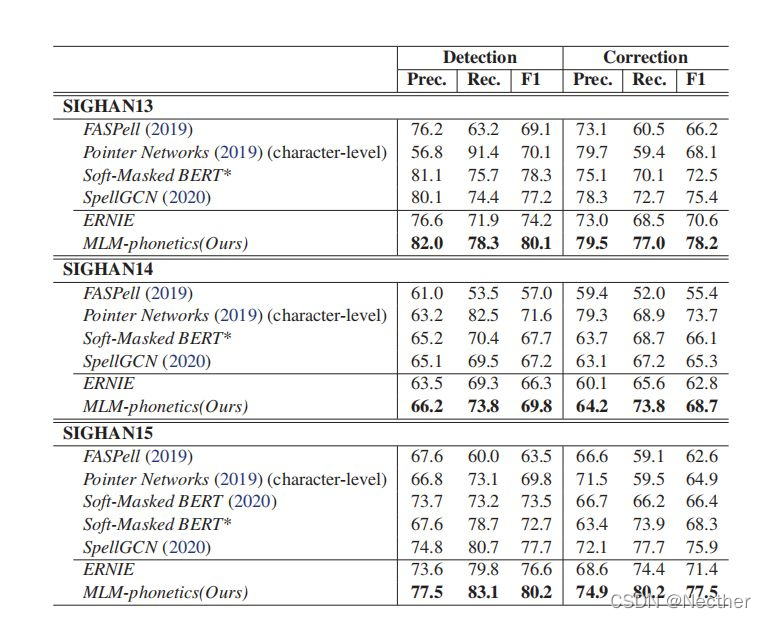
表1:SIGHAN13、SIGHAN14和SIGHAN15测试集的性能。软掩蔽误码率*我们是生产软掩蔽误码使用我们方法中的圣训数据软掩蔽误码对包含500万个句子的内部数据集及其自动产生错误的对应数据集进行了培训,如下文所述张等(2020),其中作者仅在SIGHAN15上提供了他们的结果。
我们将我们的方法与以前的先进方法相比较:
FASPell(Hong et ai.,2019)首先通过预先训练的MLM为输入句子中的每个字符生成候选,然后使用具有视觉和语音相似特征的填充模型来选择最佳候选。
指针网络(Wang et ai.,2019)基于每个正确单词包含在错误字符的混淆集中的约束使用seq2seq系统。
对于句子中的每个标记,软掩蔽BERT(Zhang et ai,2020)线性地结合其嵌入和[MASK]的嵌入,并且基于微调掩蔽语言模型从混淆集预测错误字符,并且对应于发音和形状相似性。
ERNIE(Sun et ai, 2020)直接从中文拼写校正(CSC)训练数据中找出标准掩蔽语言模型。
MLM-phonetics,我们提出的方法使用基于具有语音特征的预先训练的语言模型的端到端系统。
指针网络在编码器和解码器中都使用LSTM。所有其他方法都把中文拼写校正(CSC)作为序列标记问题,用预先训练的12层变压器作为编码器。FASPell和软掩码BERT使用预先训练的BERT,而ERNIE和MLM语音使用预先训练的ERNIE进行初始化。我们使用句子级和字符级fl评分来评估不同的系统。在句子层面,只有在检测到或校正了句子中的所有错误时才认为预测是正确的。因此,句子级的评价更加严格,结果得分较低。紧随程艾(2020年)[6]
使用(Hong et ai.,2019)中的脚本来计算句子级结果。
总体成果
表1显示了三个SIGHAN测试集的检测和校正性能。除指针网络外,所有方法都提供句子级别的结果,指针网络提供特征级别的结果。
结果表明,MLM语音方法明显优于其它语音系统。例如,在SIGHAN 15上,检测Fl-score与先前最佳方法SpellGCN相比具有2.5点改进(77.7->80.2),并且校正Fl-score具有1.6点改进(75.9->77.5)。在校正分数方面,我们的方法也比ERNIE提高了6分以上,验证了我们的训练前策略的有效性。
除指针网络外,所有列出的方法都使用预训练模型来初始化,但是只有FASPell、SpellGCN和我们的方法才考虑语音信息。FASPell使用孤立的语音特征和语言模型,这必然导致性能下降。SpellGCN通过在BERT之上构建图卷积网络将语音知识融入语言模型。它被证明是有效的,但是该图是从一个准备好的混淆集导出的。因此,模型的性能取决于该组的完整性。如表1所示,SpellGCN的精度接近MLM-语音,但是在召回方面存在显著差距。该方法在拼音符号辅助下,将语音特征融合到单词嵌入中,提高了模型的通用性。软掩蔽误码率纠正句子没有语音特征。它的检测和校正性能不如我们的。这可能部分归因于语音相似性的缺乏以及模型结构的差异。另外值得注意的是,MLM语音方法的训练数据与指针网络、软掩蔽BERT*、SpellGCN和ERNIE的训练数据一致,但是软掩蔽BERT和FASPEll使用不同的训练数据。一些案例研究见附录C。
培训前任务
为了分析三个替换任务(MASK, Confuse-Hanzi, Noisy-pinyin)在MLM语音学前训练中的作用
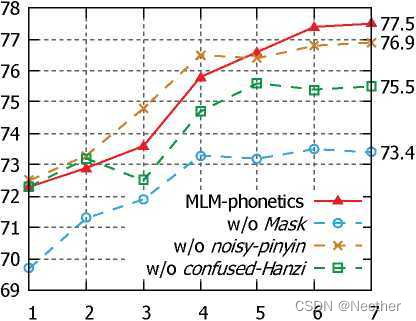
比较三个模型,每个模型只训练三个任务中的两个,概率相等。
环氧树脂
图 4:在 SIGHAN 15 测试集上评估的 4 个预先训练的模型的语句级更正 F1 评分。
在微调期间,SIGHAN 15上的测试曲线如图4所示。MLM-语音学表现最佳,在第7代达到77.5分。然而,有趣的是,它的性能不如预先训练的模型,在开始时没有(w/o)噪声-拼音。这是由预处理和微调差异造成的。
模型w/o噪声拼音只学习预习[MASK]和混淆汉字中的原始字符。所以拼音嵌入直到微调才初始化。因此,在纤网融合阶段,拼音嵌入可视为噪声。这种嵌入接近其预处理输入分布,因此预训练模型w/o噪声拼音在开始时表现良好。相反,MLM-语音学被训练为在预训练中基于汉字嵌入或拼音嵌入来重构单词。但是需要通过微调融合来预测,因此需要更长的训练时间来适应。随着训练的继续,模型从嵌入融合中获益,最终达到0.6点改进(76.9~>77.5)。
此外,另外两个预训练的模型表现相对较低。训练前模型w/oconfiked-Hanzi在训练前和微调时存在输入偏差。直到finetuning阶段,模型才被训练来从拼写错误中纠正单词。预先训练的模型w/o[MASK]表现最差,这显示了
使用[MASK]预测增强语义理解。
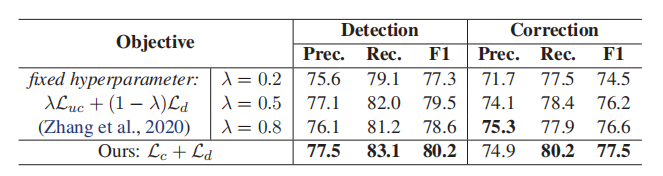
表2:SIGHAN15上使用不同目标的句子级表现。
平衡检测和纠正的目标
接下来,我们探讨微调中平衡这两个目标的加权策略的影响。在我们的中文拼写校正(CSC)模型中,检测和校正都是序列标记任务。我们使用检测概率来平衡两个任务,如等式(6)所示。相反,Zhang et ai.(2020)用固定的超参数λ: λLuc+(1−λ)Ld (其中Luc是未加权的负对数校正可能性)来平衡这两个任务:
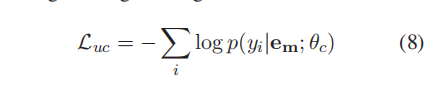
这两个战略的结果见表2。我们的方法通常优于使用固定超参数进行组合的结果。在具有固定超参数的三个系统中,λ = 0.8的系统具有最高的校正fl-分数,λ = 0.5的系统具有最好的检测fl-分数。注意,基于校正结果(即,仅将校正字符视为检测)而不是基于检测模块的预测来评估检测Fl得分。因此,对于设置λ = 0.2需要花费很多检测成本,但是其检测fl-score是最差的,这一点并不奇怪。这也为我们提供了检测和校正需要协调的提示。将λ设置为0.2可以改善检测模块的性能,但是较差的校正模块将降低最终检测性能。
相反,我们的方法根据检测模块给出的置信度动态平衡Lc和Ld,并且达到最佳性能。与λ = 0.8的固定超参数策略相比,我们的F1得分在检测上有1.6分(78.6~>80.2)的提高,在校正上有0.9分(76.6~>77.5)的提高,表明我们的动态平衡策略在缓解两个任务之间的不平衡问题方面的有效性。
误差分析
为了分析预测误差,我们收集错误预测的样本并将其分类为两类:
检测模块产生错误预测,即:ydi ≠ y ˆ di
检测模块生成正确的预测,但是校正模块未能生成正确的字符,即
。
在SIGHAN15测试集上归纳了两类,检测误差和校正误差的比例分别为83.6%和16.4%。这表明大多数错误预测是检测错误。
进一步探讨了检测性能差的原因。这主要是因为无法检测许多错误(假阴性错误),还是检测模块对错误(假阳性错误)作出不正确的预测?将83.6%的检测误差分解为两种类型,发现false negative误差和false positive误差分别占41.1%和42.5%。两种错误类型的比例几乎相等。一个可能的原因是一些同音异义词无法区分,如“的”、“地”和“得”。这三个字符都有“de”的发音,在许多句子中,无论是语音还是语义上,使用这些候选词都有意义。Cheng et ai(2020)也提出了这个问题,这需要进一步微调,以减少难辨性。在这种情况下,检测模块产生许多与地面真值结果不同的预测,影响检测性能。
结论
本文提出了一种新的具有语音预训练功能的汉语拼写改正端到端框架。铟
该模型以传统的流水线系统为核心,将字符的语音信息融入到预训练中。我们首先训练一个带有语音特征的掩蔽语言模型,以提高模型理解拼写错误的句子的能力,并模拟字符和拼音符号之间的相似性。此外,我们提出了一个端到端框架,将检测和校正集成到一个模型中。在基准数据集上的实验表明,我们的模型显著地优于以前的最新状态。具有语音特征的汉字拼写校正(CSC)模型可用于减少语音识别和翻译系统的错误。将来,我们将把中文拼写校正(CSC)应用到更具挑战性的场景中,如自动同声翻译的流式自动语音识别(ASR)纠错,以及可变长度校正。
致谢
我们谨感谢匿名评论员所作的洞察力评论,并感谢我们的同事陈英在写作方面的建议。
参考文献
Yonatan Belinkov和Yonatan Bisk.2017年。合成噪声和自然噪声均破坏神经机器翻译。arXiv预印arXiv:1711.02173。
Chao-Huang Chang.1995。一种新的自动中文拼写校正方法。《自然语言处理太平洋边缘研讨会论文集》,第95卷,第278-283页。Citeser。
陈光裕,李鸿成,李仲涵,王新民,陈新喜。汉语拼写检查的语言建模研究。《第七届SIGHAN中文处理工作会议记录》,第79-83页,日本名古屋。亚洲自然语言处理联合会。
郑兴义,徐伟迪,陈昆龙,江少华,王凤,王太峰,朱伟,袁琪。2020年。SpellGCN:将语音和视觉相似性结合到语言模型中,用于中文拼写检查。计算语言学协会第五十八届年会记录,第871-881页,在线。计算语言学协会。
赵宣文、吴建成、张学勤。基于统计机器翻译的中文拼写检查器。《第七届SIGHAN中文处理工作会议记录》,第49-53页,日本名古屋。亚洲自然语言处理联合会。
Jacob Devlin, Ming-Wei Chang, Kenton Lee和Kristina Toutanova。BERT:对深层双向转换器进行语言理解预训练。计算语言学协会北美分会2019年会议记录:人类语言技术,第1卷(长短文),第4171-4186页,明尼苏达州明尼阿波利斯。计算语言学协会。
董世超,蒲昌凤,李宾阳,彭宝林,廖明,朱佳和黄锦辉。2016年。ACE:汉语自动口语化、排版及正字错误检测。在《2016学报》上,第26届计算语言学国际会议:系统演示,194197页,日本大阪。2016COLING组织委员会。
高建峰,李小龙,米科尔,奎克和孙旭。2010。基于排名器的大规模搜索查询拼写校正系统。第二十三届计算语言学国际会议论文集,第358-366页,北京,中国。2010年组委会。
余中红,祥国宇,嫩河,刘楠,刘俊辉。2019。FASPell:基于DAE-decoder范例的快速、适应性强、简单、强大的中文拼写检查器。在第五届“噪声用户生成文本”工作会议记录(W-NUT 2019),第160-169页,中国香港。计算语言学协会。
贾仲业、王佩璐、赵海等。中文拼写检查的图形模型。《第七届SIGHAN中文处理工作会议记录》,第88-92页,日本名古屋。亚洲自然语言处理联合会。
刘超林,赖敏华,庄一宣,李嘉颖。2010。在视觉和语音上相似的字符在错误的简体中文。2010年:海报,第739-747页,北京,中国。2010年组委会。
刘小东、程凯文、罗燕燕、杜凯文、松本裕二。使用语言模型和统计机器翻译与重新排序的混合汉语拼写校正。《第七届SIGHAN中文处理工作会议记录》,第54-58页,日本名古屋。亚洲自然语言处理联合会。
Bruno Martins和Mario J Silva.2004。对搜索引擎查询进行拼写校正。在自然语言处理国际大会(西班牙),第372-383页。斯普林格。
Keisuke Sakaguchi、Tomoya Mizumoto、Mamoru Ko-machi和Yuji Matsumoto。联合英语拼写错误纠正和词性标记为语言学习者写作。《COLING 2012学报》,第2357-2374页,印度孟买。COLING 2012组织委员会。
余孙,王朔欢,李宇昆,冯世昆,郝田,吴华和海丰。2020年。Ernie2.0:语言理解的持续培训前框架。1/1/W,第8968-8975页。
曾俊欣,李龙浩,张立平,陈新喜。2015。SIGHAN 2015中文拼写检查介绍。《第八届SIGHAN汉语加工研讨会论文集》,第32-37页,北京,中国。计算语言学协会。
Bertus Van Rooy和Lande Schafer.2002。自动pos标记时Leamer错误对pos标记错误的影响。南部非洲语言和应用。语言研究,20(41:325-335)。
王定民,严松,李京,韩嘉龙,张海松。2018。一种用于中文拼写检查的自动语料库生成混合方法。2018年自然语言处理经验方法会议记录,第2517-2527页,比利时布鲁塞尔。计算语言学协会。
王定民,李泰和李忠。2019年。用于中文拼写检查的模糊集引导指针网络。计算语言学协会第五十七届年会记录,第5780-5785页,意大利佛罗伦萨。计算语言学协会。
吴世雄,陈永志,杨炳哲,徐库,刘超林。2010。降低汉字错误检测和纠正的误码率。CIPS-SIGHAN中文处理联席会议。
吴世雄,刘超林,李龙浩。2013年SIGHAN bake-off中文拼写检查评估。第七届SIGHAN汉语加工研讨会论文集,第35-42页,日本名古屋。亚洲自然语言处理联合会。
吴世雄,王军伟,陈良璞,杨平切。2018。CYUT-III组汉语语法错误诊断系统报告在NLPTEA-2018CGED共享任务中。第5期教育应用自然语言处理技术讲习班论文集,第199-202页,澳大利亚墨尔本。计算语言学协会。
杨欣,海兆,王玉竹,和贾中业。一种改进的中文拼写检查图形模型。第三次CIPS-SIGHAN中文处理联席会议记录,第157-166页,武汉,中国。计算语言学协会。
杨毅,谢鹏军,陶俊,徐光伟,李林林和罗思。2017年。阿里巴巴在IJCNLP-2017任务1:将语法特征嵌入LSTM,用于汉语语法错误诊断任务。在《国际JCNLP 2017会议录》中,共享任务,第41-46页,台湾台北。亚洲自然语言处理联合会。
余俊杰和李正华。基于语言模型、发音和形状的汉语拼写错误检测和纠正。第三次CIPS-SIGHAN中文处理联席会议记录,第220-223页,武汉,中国。计算语言学协会。
梁智瑜,李龙浩,曾俊欣,陈新喜。2014。SIGHAN2014中文拼写检查概要。第三次CIPS-SIGHAN中文处理联席会议记录,第126-132页,武汉,中国。计算语言学协会。
张少华、黄浩然、刘继聪和李恒。2020年。用软掩蔽误码率进行拼写纠错。计算语言学协会第五十八届年会记录,第882-890页,在线。计算语言学协会。
博正、万向切、姜国及丁刘。2016年。长短记忆网络的汉语语法错误诊断。第3期教育应用自然语言处理技术研讨会论文集(NLPTEA2016),第49-56页,日本大阪。2016COLING组织委员会。
数据集
所有使用过的数据集都列在表3中。训练前语料库包含30亿个句子,其余四个语料库总共包含281K<error, correct>句子对。三个SIGHAN数据集是人标注并且利用自动语音识别(ASR)和OCR技术自动生成(Wang et ai,2018)。[7]
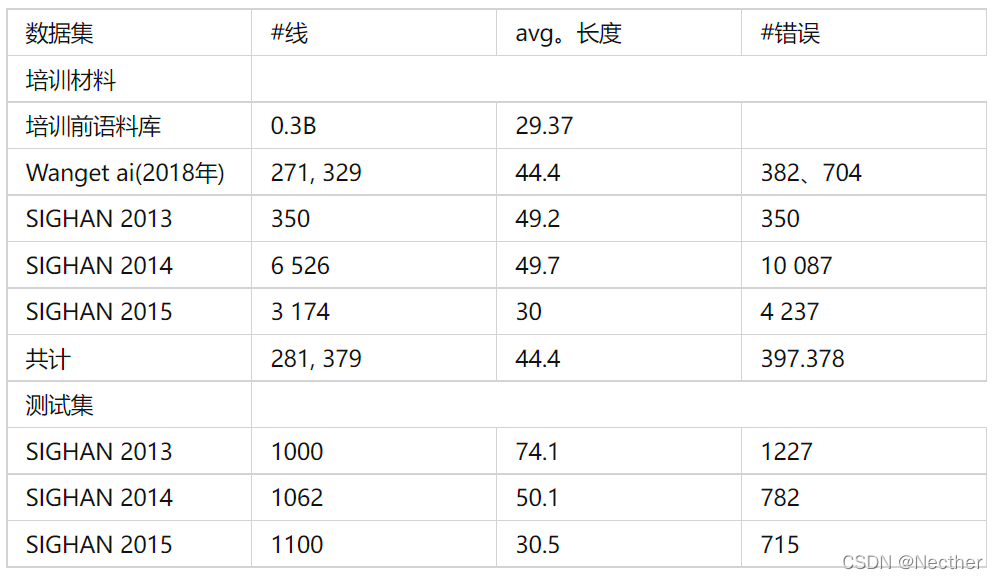
表3:实验数据统计信息。
B 误码率和误码率的差异
我们在SIGHAN测试集上评估两个预先训练的模型(BERT(Devlin等,2019)和ERNIE(Sun等,2020)的性能。对于两者,我们使用基本版本的发布模型(隐藏大小为768的12层)。[8]
零击性能列于表4。在此设置中,我们直接使用所释放的模型来进行纠错,而不需要finc-luiiing。结果表明,ERNIE在检测和校正方面均优于BERT。这是由BERT的一个预测问题引起的,在大多数情况下,BERT将lirsl字符修正为周期符号(°)。我们推测,这是由于BERT中文数据预处理错误,即当一个段落被划分为多个句子时,它总是将句子的结束期划分为下一个句子的开始。因此,许多句子错误地预测开始字符为周期符号。
然后对两种预训练模型的281K汉语拼写改正(CSC)训练数据进行了整理。表5显示两种模型的性能基本相同。SIGHAN13、SIGHAN14和SIGHAN15上的BERT和ERNIE之间的差别分别为+0.4、-2.0和+1.6。因此,利力仑后误码率与误码率的差异是微不足道的。
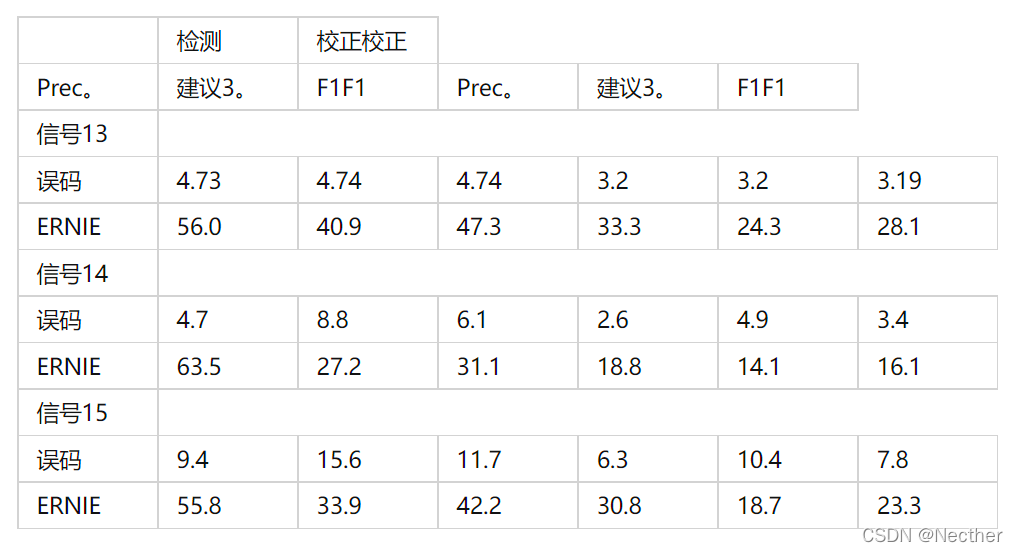
表4:零点误码率和ERNIE的性能。
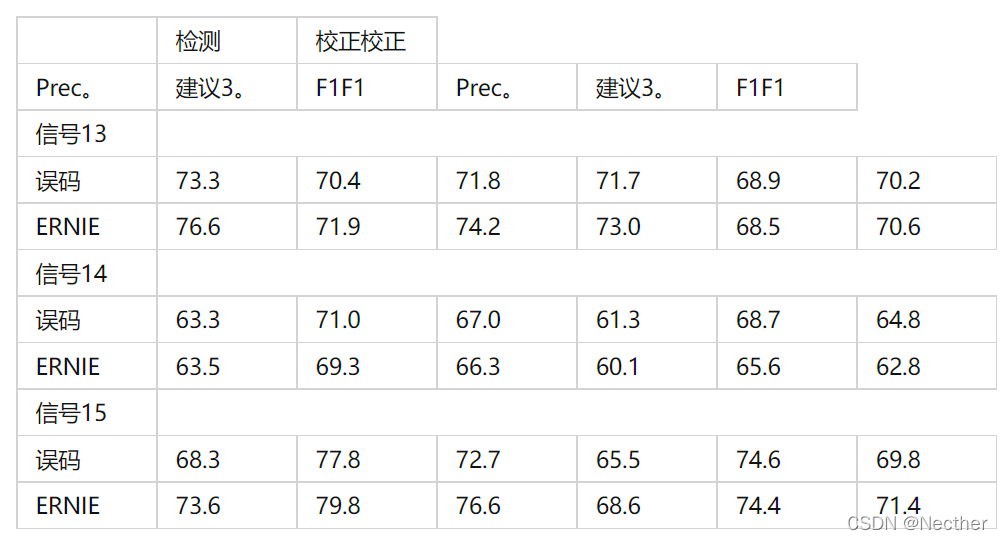
表5:带有微调的预训练模型的性能。
C消融研究
我们将我们的方法与在表3所示的相同数据集上训练的ERNIE和软掩蔽BERT进行比较。表6和表7显示,MLM-语音在生成语义上连贯和相似的发声校正方面表现得更好。
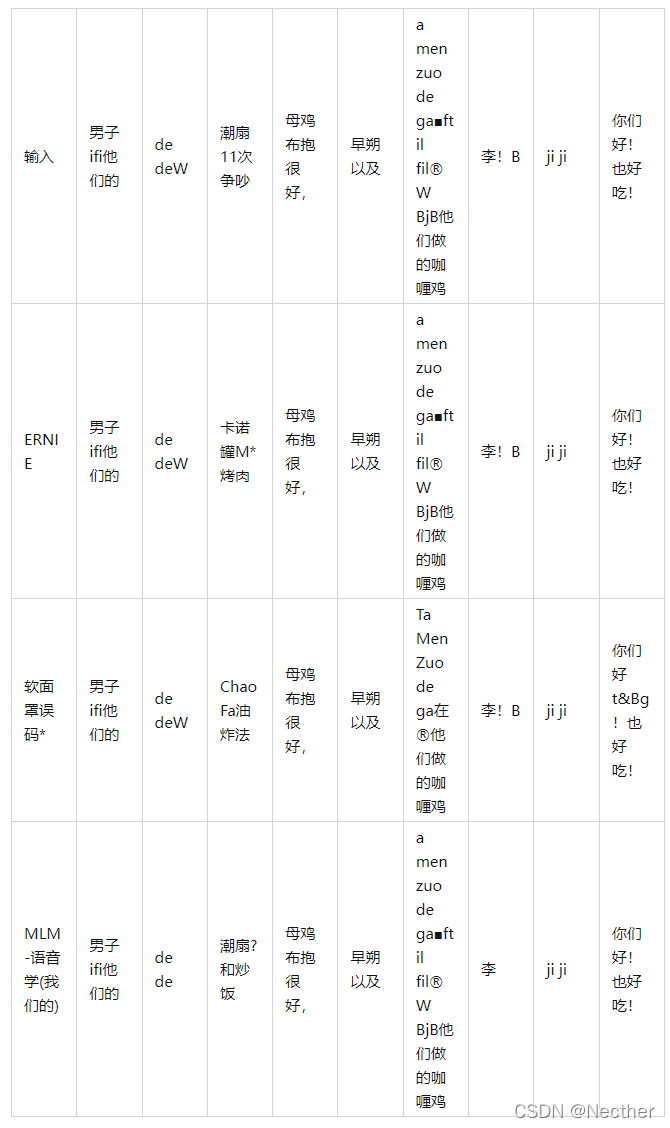
表6:SIGHAN15测试集的一个示例。错误标记为红色,正确的纠正为蓝色。这三种方法都能准确地检测出拼写错误,但只有MLM语音才能得到正确的结果。ERNIE更改(“chao fan”)到不同的发音(“kao can”),而软面BERT更改 ffl”到(“chao fa”,fried 方法),听起来类似,但在语义连贯的tentenns中的(炸米)。
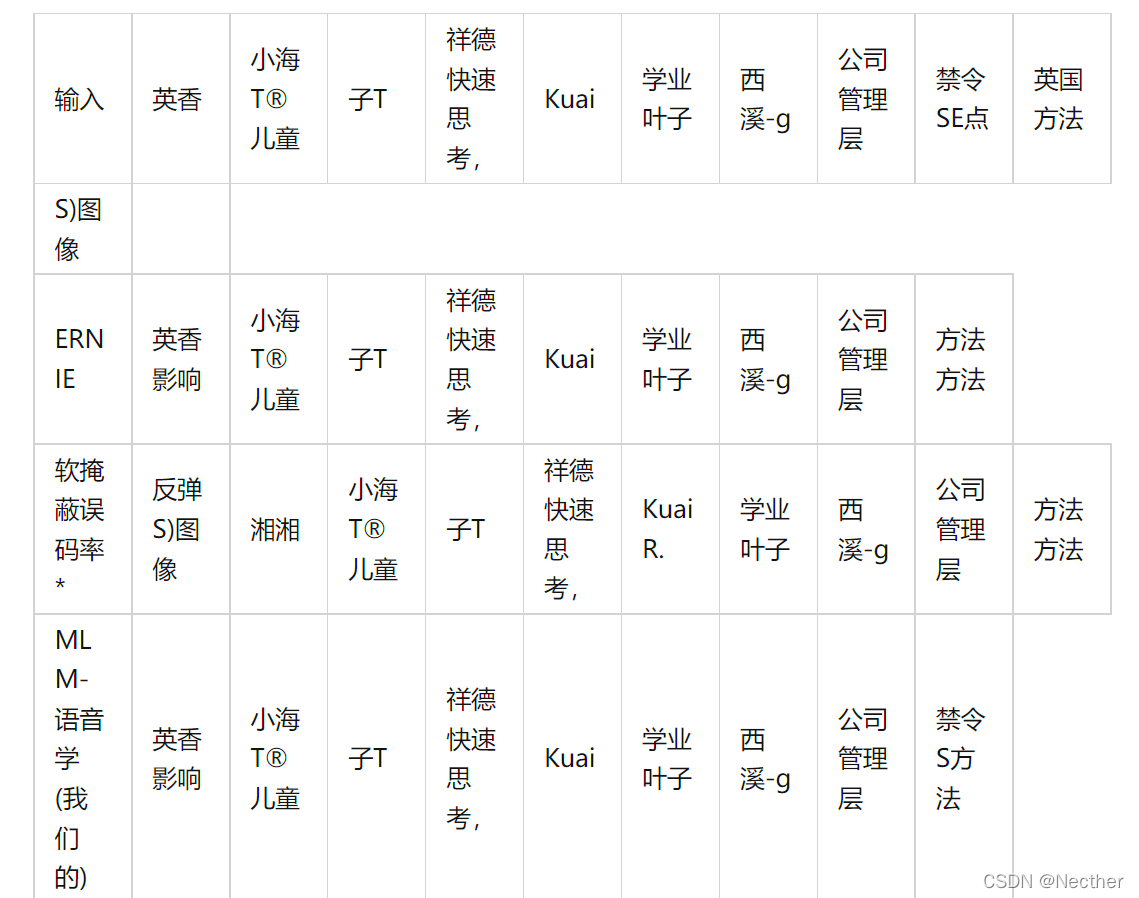
表7:SIGHAN15测试集的另一个示例。同样,MLM-语音学预测语音相似和语义相干校正。但ERNIE和软掩蔽的BERT都用“7j”(fang)代替了“SE”(ban)。
*来文人。
2Confusion集是一组类似的字符。 ↑
在本文中,我们忽略了拼音的语调,使用同音符来表示拼音相同的字符。 ↑
汉字是汉字的音译。↑
对于混淆集中的多个字符,在替换中随机选择它们/它们的拼音。 ↑
有关培训语料库的细节,请参见附录A。 ↑
BERT和ERNIE在flne调优方面的差异是微不足道的。 ↑
281K个句子对可在https://github.com/ACL2020SpellGCN/SpellGCN/tree/master/data/univate下载。 ↑
ERNIE发布的模型:https://github.com/PaddlePaddle/ERNIE。BERT的释放模型:https://github.com/google-researcli/bert↑

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









