






公众号 系统之神与我同在
http://link.zhihu.com/?target=https%3A//ojs.aaai.org/index.php/AAAI/article/view/17678
https://ojs.aaai.org/index.php/AAAI/article/view/17678
http://link.zhihu.com/?target=https%3A//ojs.aaai.org/index.php/AAAI/article/view/17678
个人知识库问答中无法回答的问题更正
摘要
人们经常遇到需要从日常生活中回忆过去的经历。本文旨在构建一个问答系统,使人们能够在个人知识库中查询过去的经验。以往关于知识库问题研究主要关注于可以回答的问题。然而,在现实世界中,人们常常混淆事实,提出那些知识库无法回答的问题。本文提出了一个由问答模型和问题生成模型组成的新系统。它不仅回答可回答的问题,而且必要时纠正不可回答的问题。我们的问答模式承认与个人知识库状态不一致的问题,并可以构成可行问题的事实。然后,通过问题生成模型将事实转换为可回答的问题。针对重写问题,提出了一种基于强化学习的问题生成模型。实验结果表明,本系统能有效地纠正个人知识库问题回答中不可回答的问题。
导言
知识库问题回答(KBQA)是以自然语言问题为输入,使用自由库(Bollacker et ai.2008)和DBpedia(Auer et ai.2007)等结构化知识库来回答事实答案的任务。前人关于知识库问答的研究(Bordes et ai.2015; Bao et ai.2016; lyyer, Yih, Chang 2017; Sorokin and Gurevych 2018; Loo et ai.2018)集中于通过知识库检索关于世界知识的信息。人类生活支持的应用,使人们能够检索个人知识,如日常生活经验和关于自己的事实,仍有待探索。
个人知识库答疑(PKBQA)是一个新兴的研究课题,为那些可能难以回忆过去的经历者提供支持。随着时间的推移,人们往往会忘记一些事情,并遇到需要回忆日常生活中过去经历的情况。从生活中忘记确切实体的名字是很常见的。Memex(Bush 1945),Vannevar Bush在1945年提出的生活记录的概念,是一个假设的系统,用来组织一个人一生的知识。该系统旨在为以灵活和有效的方式查询他/她的生命日志的个人提供记忆帮助。Yenet ai(2019a)提出一种多模式联合学习方法,通过从社交媒体帖子中提取个人生活事件来构建个人的个人知识库(KB)。利用Yen、Huang和Chen(2019a;2019b)发布的公共个人知识库(KB),我们讨论构建允许用户通过个人知识库(KB)用自然语言查询的过去经验的系统。例如,用户忘记了他去年访问的地方的名称。服务试图通过搜索有关个人生活事件的知识库(KB)来识别地方的名称。
然而,在实际的应用场景中,人们可能会提出无法回答的问题,因为人们无法记住她/他过去的经历中的每一条信息,从而形成正确的问题。知识库不能回答问题的原因可包括:(1)知识库(KB)不完整以涵盖问题所需的所有事实(熊等2019),(2)用户生成的问题形式不健全,例如实体或谓词缺失,并包含非语法短语(Christmann等,2019),(3)问题模棱两可且具有多个谓词关系,(4)问题中提到的实体和/或关系与知识库中的事实不一致。本文主要研究解决由最后一个原因引起的无法回答的问题,即问题中表达的事件与个人知识库中的事实不一致。
近年来,无法回答的问题引起了人们的关注。Rajpurkar et ai(2018)发布了一个名为SQuAD 2.0的机器阅读理解数据集,其中包含可回答和不可回答的问题。在SQuAD 2.0中,问题的答案是给定段落中的一部分。无法回答的问题被定义为答案不是上下文一部分的场景。因此,模型无法选择问题的文本范围。与SQuAD 2.0不同,本文的问题需要跨知识库(KB)中的多个事实进行推理,而不是在单个段落中筛选句子的答案。此外,向用户推荐他们可能想问的问题比不给用户回复答案要好得多。
我们处理PKBQA中无法回答的问题,旨在建议用户更正的问题。我们构建了一个活跃的PKBQA系统,它不仅从个人知识库(KB)中检索可回答问题的答案,而且还对无法回答的问题提出了可能的修正。以下简称PKBQAC(Personal Knowledge Base Qualition with Correction)。图1显示了当问题无法回答时,个人知识库问答系统(PKBQAC)的使用情况。用户试图回忆起她去年与朋友一起参观的宫殿的名字。然而,她混淆了朋友的名字。这导致一个问题与存储在她自己的个人知识库(KB)中的任何事件不匹配。我们的系统基于个人知识库(KB)纠正无法回答的问题,以帮助用户回忆体验。
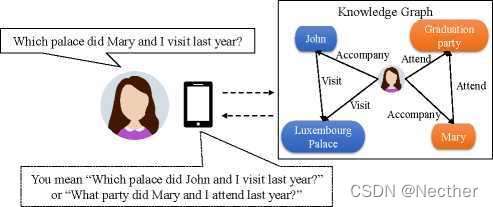
图1:不可回答问题的个人知识库问答改正方案(PKBQAC)。
图1:不可回答问题的个人知识库问答改正方案(PKBQAC)。
具体来说,我们的个人知识库问答改正系统由问答模型和问题生成模型组成。问题回答模型旨在通过生成n个候选查询图{gi,gi,…,gn},从个人知识库(KB)中提取答案。如果gi(1<i<n)中没有一个是知识图的子图,即候选查询图不能回答问题,则触发问题生成模型根据校正的查询图g′和原始问题生成问题。
本文的主要挑战有两个:(1)用户如何表达问题,以回顾过去的经验;(2)如何评价修正后的问题是否反映了用户的意图。由于召回问题和无法回答问题的纠正难以收集,我们利用Yenet ai(2019a;2019b)发布的公共可用个人知识库(KB)构建了问答数据集。我们手动标记问答对,以模拟人们询问经验的场景。数据集包含几个问题类型,包含无法回答的问题及其可能的修正。细节将在数据集构建部分中描述。
(1)将无法回答问题的检测推广到基于个人知识库(KB)的纠正,(2)构建了基于个人知识库(KB)的无法回答问题纠正数据集,(3)提出了基于强化学习(RL)的具有编辑机制的问题生成模型。实验结果表明,该方法具有良好的性能。
相关工作
在这项工作中,我们致力于构建一个能够回答用户关于他/她过去的个人知识库(KB)经验的问题的系统。核心任务可视为一般知识库问题回答(KBQA)的构建。知识库问题答疑(KBQA)的研究大多集中于从世界知识库中提取答案。最近,一些研究试图开发人们回忆过去记忆的系统。Jiang et ai(2017)构建了由真实世界个人相册问题组成的MemexQA数据集,提出了一种多模式端到端神经网络模型,并引入关注力核用于回答问题。Gurrin et ai(2016;2017;2019)和Dang-Nguyen et ai(2019)引入了用于生活日志检索系统的评估数据集,用于查询生命日志记录者的生命中的特定时刻。我们构建了基于个人知识库(KB)的问答数据集,而不是关注于从视觉数据中检索生活事件。
前人关于世界知识库(KB)问答或终身检索的研究主要集中于可回答的问题。在现实世界中,人们回忆自己的经历时,可能会问一些无法回答的问题。一些研究者处理了机器阅读理解中不可回答的问题。Huet ai(2019)提出了一种通过计算目标函数中的无答案损失来检测不可回答问题的方法。Sun et ai(2018)提出了一个多任务学习模型,用于识别问题的不可回答性。与仅回答正确问题相反,本系统旨在正确回答知识库(KB)上的问题,并基于他/她的个人知识库(KB)主动生成与用户想要问什么相关的纠正问题。
一些工作通过重写或转换句子结构的输入查询来提高知识库问答的表现。Dong et ai(2017)提出了一种重写输入问题的方法,以增加获得正确答案的概率。Yahya et ai(2016)提出了一种框架,通过重写来放松用户查询范围,以实现更高的召回。熊等(2019)利用输入问题表示和知识库(KB)知识转换问题形式查询。Buck et ai(2018)提出一种基于强化学习(RL)的系统来重新转换原始问题,以检索更多的候选答案。这些工作旨在通过结合查询扩展机制提高检索拼接答案的能力。然而,扩展或放松无法回答的问题不适合我们的工作,因为原始问题中描述的事件与个人知识库(KB)不一致。本文基于个人知识库(KB),将不可回答的问题纠正为可回答的问题。
我们的工作与问题生成任务之间的差异(Nema等人,2019年;Elsahar、Gravier和Laforest)
1.以及序列编辑(Zhao et ai.2019;Malmi et ai)。
2.就是基于知识库中的事实,重点生成语法问题和可回答问题。许多问题生成模型生成的问题存在生成句法不正确或不完整的问题的问题。Seq2seq模型(Nema et ai.2019;Chen、Wu和Zaki 2020)使用具有基线算法的REINFORCE用external
3.l奖励得分来增强,可以生成更多有效的问题。受此启发,我们提出了一种基于强化学习的且带有问题编辑功能的问题生成模型。
数据集结构

表1:复杂问题组合的实例。(t)表示时间戳。)
我们利用公开可用的个人知识库(KB)(Yen、Huang和Chen 2019a、b)来构建数据集1。个人知识库(KB)137个关系和15, 525个中文事件组成,其从18个用户所收集的。在数据集的构建中,我们参考Dubey et ai(2019)的注释工作流程。我们首先根据来自个人知识库(KB)的事件应用几个手工制作的模板来生成种子问题集。手工制作的模板生成七类问题,包括“谁”、“什么”、“在哪里”、“何时”、“多少”、“持续时间”和“真或假”。对于每种类型的问题,我们构建4个模板。因此,我们总共有28个模板。我们还允许人类注释者在生成的问题是非语法的或有影响的情况下自己编写问题。这样,生成的问题被人类注释者检查和解释,以确保问题是语法正确的。注意,实体可以具有多个表面形式,并且知识库(KB)关系可以以各种自然语言形式表达。除了语法的释义外,还要求人类注释家对问题中的主语、宾语和谓语进行释义,以避免个人知识库中的实体和关系描述完全匹配。
问题类型可进一步分为简单问题和复杂问题。简单的问题(Bordeset ai.2015)意味着可以仅基于知识库中的一个关系来回答问题。相反,回答复杂问题(Baoet ai.2016)可以通过在知识库(KB)中经由两个或三个关系从一个实体搜索到其他实体。存在两种类型的复杂问题,EaEb和EaEbEc,其中符号Ea、Eb和Ec表示知识库(KB)中的不同实体。例如,EaEbEc意味着通过使用个人知识库(KB)中的三个实体来回答问题。在事件Ea中,答案必须是主题、对象或时间。表1显示了从个人知识库(KB)生成的两种组合的示例。
真或假问题可以由上述规则生成。以表1的第一行为例,真正的问题是“Have I ever been to the Eiffel Tower for Espresso?”错误的问题可以通过替换其中一个事件来生成。例如,我们将(User, Ingestion, Espresso, ts) 替换为(User, Ingestion, Tequila, ts),这样错误的问题是“Have I ever been to the Eiffel Tower to drink Tequila?”
上述过程产生了可回答的问题。与产生假问题的想法类似,不可回答的问题是通过在可回答的问题中替换一事件或事件的时间而产生的。例如,替换表1中第二行的事件B,无法回答的问题是“Where did I go after I went to the Champ de Mar to drink Tequila?”为了避免产生用户永远不会问的问题,我们基于问题应该包含从知识库(KB)中选择的至少一个实体的原则来生成不可回答的问题。也就是说,我们假设用户在实际操作中询问的问题至少包含一个以前经历的事件。这样,无法回答的问题不是由简单的问题产生的。注释器被要求检查新组合是否肯定不同于原始组合,并且与用户体验过的内容无关。
总而言之,有两类可回答的问题:(1)答案可以从知识库中检索;(2)答案可以用基于知识库的“真”或“假”来回答。其余的问题是无法回答的。结果,数据集包含41, 960个不同的问题,其中可回答和不可回答问题的数目分别为38, 201和3, 759。表2显示了不同组合的七个问题类型的分布。
带有纠错机制的个人知识库问答
图2显示了我们的个人知识库问题回答与纠正(PKBQAC)系统的整体结构。个人知识库问答改正系统由两个阶段组成。在第一阶段,问答模型旨在生成候选查询图以从输入问题的知识库(KB)提取答案。如果找不到答案,就会被认为是一个无法回答的问题。在校正查询图之后,第二阶段中的问题生成模型通过问题编辑来生成流畅的问题。我们将在以下各节中详细阐述每个阶段。
第一阶段:无法回答问题的识别
本文提出了一种基于语义分析的问答模型,以查询图的形式表示问题的语义结构。候选查询图被形成为树形图,其中树的根是
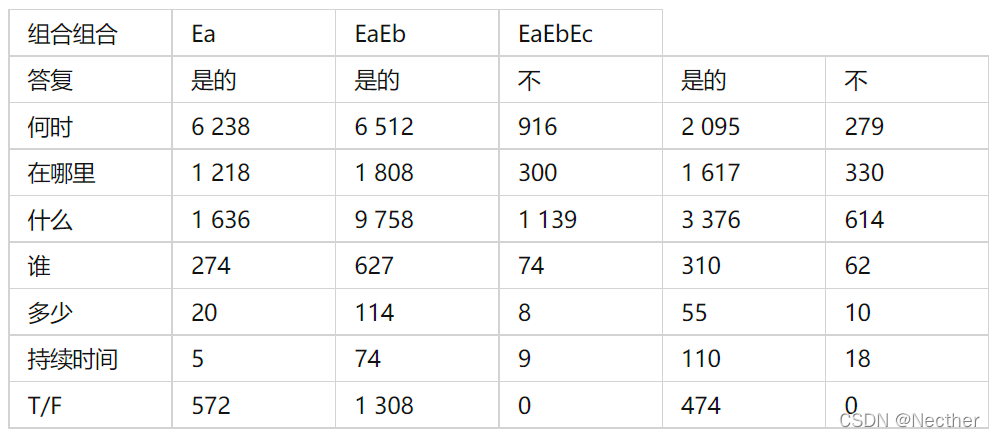
表二:数据集不同问题的分布

图2:我们个人知识库答疑改正系统概述。
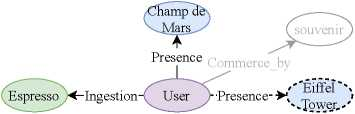
图3:候选查询图的示例。
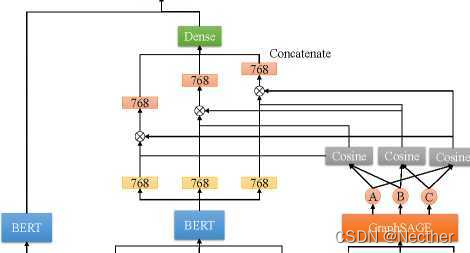
问答模型 问题回答模型图4显示了我们的问题回答模型的神经网络结构。在单词的层次上,我们用两个BERT模型对问题和查询图进行编码。注意,我们假设查询图最多由来自个人知识库(KB)的三个事件组成。当查询图只包括两个事件时,第三个输入事件表示为零向量。
表示真实问题答案实体的回答节点。树中的其他节点是从问题中提取的实体,其通过知识库(KB)中的关系来约束回答节点。我们计算问题和每个候选查询图之间的语义相似性。将报告得分最高的查询图作为答案。
事件的抽取 为了生成候选查询图,我们提出了一种基于BERT模型的文本标记器,利用条件随机字段层提取问题中提到的谓词和实体,并将它们转换为主题中的事件(主语、谓语、宾语、时间)。实体引用和谓词提取是BIO方案下的序列标记问题。
由于我们的数据集包含七种类型的问题,因此构造了另一个基于BERT的分类器来对问题的类型进行分类。这个任务被认为是多类分类。给定一个问题q,我们的目标是开发一个模型来预测q的类别,即,其中Q是我们数据集中七个问题类型的集合。我们使用softmax层来计算七个问题类型的概率。
查询图的生成 考虑到一个实体有多种表面形式,以及自然语言谓词与知识库(KB)关系之间的差距,我们提出了另一种基于BERT的模型,分别将所提取的谓词与个人知识库(KB)中的关系和实体对齐。通常,我们通过使用BERT模型将所提取的实体提及m与知识库(KB)中的实体e对齐,其中m和e由128个tokens表示。它们作为序列对输入到BERT模型,序列对带有起始和分离符token:([CLS]m[SEP]e[SEP])。将这些提取的谓词与知识库(KB)中的关系对齐的过程与上述方法相同。对于查询图的生成,我们将实体视作节点,关系是与两个节点连接的边缘。我们通过广度优先搜索(BFS)查找与e连接的实体,以生成n个候选查询图{gi, gz, …,例如,表1中的第二个问题的候选查询图如图3所示。实箭头和实圆表示从问题中识别的事件。虚线箭头表示与所识别的事件连接的可能路径。
A事件:B事件:C事件:字符级字符级字符级事件A事件
图4:我们的问题回答模型的结构。
图神经网络已被证明在答问任务中是有效的(Dhingra et ai.2018;Xiao et ai.2019)。除了语义表示之外,GraphSAGE(Hamilton、Ying 和 Leskovec 2017)生成的节点嵌入也结合到我们的问答模型中,以丰富特征。GraphSAGE是一个归纳框架,它利用节点本地相邻节点的特性来生成嵌入。我们利用GraphSAGE获得每个节点在知识库中的嵌入。我们计算事件A、B和C的对象节点之间的余弦相似性。
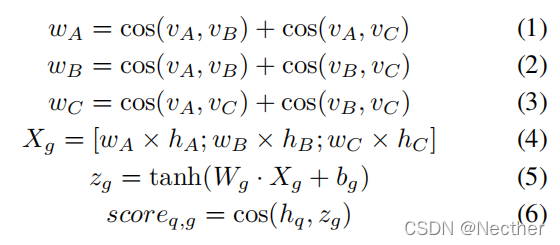
其中,vа是从GraphSAGE生成的事件a中对象的节点嵌入,a表示A、B或C的事件,并且ha是从输入事件a的BERT输出的最终隐藏状态。我们乘以每个事件的隐藏状态以它自己的权重作为特征表示。然后,通过连接每个事件的特征表示并与密集层连接,获得候选查询图g的最终表示zg。如果事件不相关,则事件的权重将较低。这使得事件向量对密集层没有贡献。符号scoreq,g表示问题hq的最终隐藏状态与zg之间的相似性得分。我们将此模型称为图加权语义匹配网络(GWSMNet)。
如果将问题预测为“谁”、“什么”、“在哪里”或“何时”的类型,则提取候选查询图g的最高相似性得分作为答案。如果问题被预测为“多少”或“持续时间”的类型,我们计算给定具有最高相似性得分的候选查询图的事件的频率或持续时间。对于被预测为“真或假”类型的问题,如果最高相似性得分高于0.5,则系统返回“真”。否则,系统反驳“假”。如果问题的类型没有被预测为“真或假”,并且最高相似性得分低于0.5,则问题被回归为不可回答的。
对于那些无法回答的问题,我们的目标是生成与用户可能想要问什么相关的问题。图5显示了一个无法回答问题的两个修正查询图g’的示例。蓝色和绿色圆圈表示用户的两个不同事件,它们彼此无关。用颜色填充的圆圈表示问题中提到的实体。最后,将用户的个人知识图转换为邻接矩阵A,通过计算Ak找出从给定实体节点到连接节点的所有可能的路径作为修正查询图。每个校正的查询图g′被输入到问题生成模型,用于转换成自然语言问题。
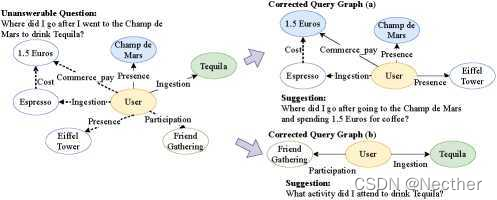
图5:来自不可回答问题的更正查询图的示例。
第二阶段:问题产生
提出一种基于强化学习(RL)的提问生成模型,通过编辑问题生成可行问题。它包括问题构造模型和问题编辑模型。网络结构如图6所示。
基于问题生成模型带有编辑问题的强化学习 构造模型以修正的查询图g′和问题类型作为输入,构造自然语言问题q’。将问题类型作为输入,使经更正的问题类型与不可回答的问题类型一致。首先,我们将校正后的查询图中的事件转换为以下称为事件序列的字序列。以图5中修正后的查询图(b)为例,事件序列是“I Presence Eiffel Tower I Ingestion Espresso”。给定事件序列和问题类型,问题构造模型生成初步问题。由于问题中可能存在信息错误,我们提出了一种基于序列到序列结构(seq2seq)的问题编辑模型,用于修正初步问题。问题生成模型称为Du-alGenNet,用于确保两个生成模型都用到了。
算法1详细阐述了基于强化学习(RL)的具有问题编辑的问题生成模型的训练过程。在每个epoch,我们首先将n个事件序列的示例和问题类型输入到问题构造模型,用于生成初步问题g’。利用对数似然作为问题构造模型的目标函数Closs来更新参数。
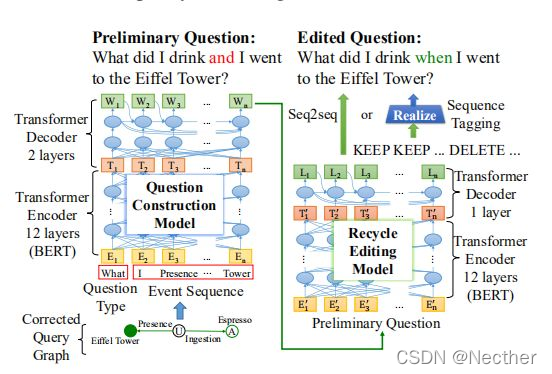
图6:问题生成模型的结构。

问题编辑模型以q’作为输入,以生成编辑的问题作为最终结果。为了奖励改进问题的问题编辑模型,使其优于初步问题,我们首先使用BLEU评估流畅度,并使用Nema和Khapra(2018)提出的分数评估可回答性。奖励函数在等式7中定义。
R(.)=可回答性+BLEU4 (7)
通过比较细化前后的问题来计算奖励函数。这样,问题编辑模型将学习如何在训练过程中怎样去编辑由问题生成模型生成的初步问题,使最终生成的问题更加流畅。
然后,我们使用“用基线加强”算法(Williams 1992)来奖励问题编辑模型。训练损失Eloss结合了极大-似然函数和奖励得分,定义如下。
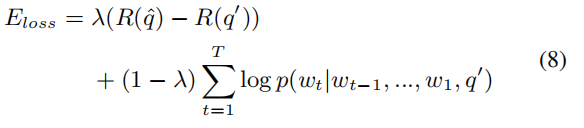
{0,1}是对数似然性和回报之间的权衡。在使用验证数据调整之后,我们将
设置为0.6。总而言之,对数似然得分用于测量所生成的问题是否类似于原问题。它是训练序列生成模型的基本功能。奖励得分用于测量问题编辑模型是否能够细化初始问题中的错误。它鼓励问题编辑模型生成更流利的问题。
为了确定问题构造模型和问题编辑模型的超参数,我们用编码器和解码器层从1到12。最后,问题构造模型将BERT编码器与12个self-attention层结合起来以及位于BERT编码器顶部的2层Transformer解码器相结合。在问题编辑模型中,编码器是12层BERT基模型,解码器是单层Transformer解码器。我们使用 Adam 优化器,学习率为 0.002,并训练我们的模型 20 epochs。
序列标注作为问题编辑 由LASERTAGGER(Malmi等,2019)启发下的编辑问题(Question Editing)模型,通过标记保存、删除和添加单词三个操作来进行文本编辑。我们将此问题生成模型称为GenTagNet,它在生成器之后使用序列标记模型。在GenTagNet中,标记标记器生成的编辑标记被用作训练的基本真值。在从问题编辑模型获得预测的标签序列之后,我们实现生成了问题。
我们的标签标记器通过在初步问题中为每个标记分配标签来生成标签序列,该标签序列与LASERTAGGER:KEEP、DELETE和ADD字相同。KEEP和DELETE指示是否在输出问题中保留token。ADD单词表示应该将哪个单词x插入到前面的问题中。x属于词汇表W,该词汇表W是通过基于数据集中的单词的频率对单词进行排序,并挑选能够覆盖80%token的顶级N个单词而构造的。一个不在W中的单词将不会被放入标签序列。虽然这可能导致不完整的问题,但问题编辑模型产生的大多数问题比初步问题更合理。标记编辑操作的好处是,当只有少量的人类注释数据集可用时,我们可以用更小的词汇表来训练模型。
预训练问题编辑模型 除了仅在数据集上训练问题编辑模型之外,我们在ClueWebO9语料库上预训练该模型(Callan et ai.2009)。我们首先从ClueWebO9语料库中收集问题。然后,我们生成由问题构造模型生成的非语法问题。具体地说,根据我们对问题构造模型生成的问题观察,我们手动生成非语法问题。非语法问题中的主要错误模式是重复短语和不正确的措辞。因此,我们根据观测到的错误模式,从语料库中转述问题,产生非语法问题。最后,我们构建了一百万个(非语法问题,正确问题)对来预先训练问题编辑模型,其中正确问题是非语法问题的基本真理。换句话说,语法正确的问题是ClueWebO9语料库中的原始问题。序列标记模型和seq2seq模型中的正确问题分别是来自标签标注器的标签序列和语料库中的原始问题。
实验在本部分中,我们分别评估了问题回答模型和问题生成模型在个人知识库改正问答系统中的表现。最好的表现是粗体。辨别是否是不可回答问题模型的评价
本节介绍我们的问答模型的性能。训练、验证和测试集的大小分别为18、137、9、103和14, 720个问题。测试集包括13, 415个可回答的问题和1, 305个不可回答的问题。性能见表3。我们采用hit@1, hit@3, 平均倒数秩(MRR)作为可回答问题,采用精确度作为不可回答问题。
比较了基于不同层次特征的三种模型。我们将Looet ai(2018)提出的模型作为基线模型再现在我们的数据集上。Looet ai(2018)和BERT提出的模型是语义匹配网络,仅计算问题和候选查询图在语义层面的相似性。
表3:不可回答问题辨认的表现。
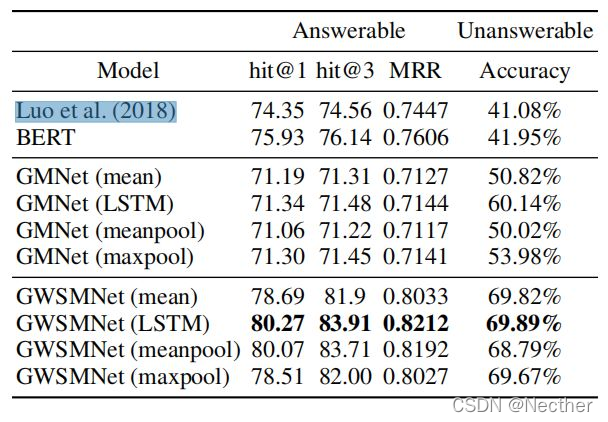
图形匹配网络(GMNet)通过计算问题语义特征与修正后的查询图中节点嵌入之间的相似性提取答案。图形加权语义匹配网络(GWSMNet)结合语义和图形层次的特征提取答案。我们还比较了在GraphSAGE中使用不同的聚合函数,包括平均算子、LSTM体系结构和池方法。我们观察到,具有LSTM聚合器的图形匹配网络(GMNet)优于其它聚合器。原因可能是LSTM聚合器具有较大表达能力的优点。
在表3中,使用LSTM聚合器的图形加权语义匹配网络(GWSMNet)在可回答的问题上达到了0.8212的MRR评分,在不可回答的问题上达到了69.89%的准确率,并且利用McNemar检验显著地优于p<0.001的所有基线模型。我们发现,结合语义和图形层次的信息能够丰富特征表达,提高可回答和不可回答问题的性能。
问题生成模型的评价
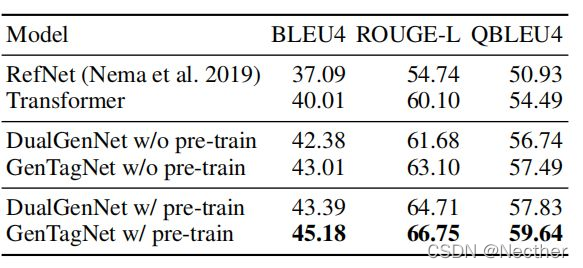
我们的数据集包含32, 425个可回答问题的查询图,以及3, 514个可回答问题的校正查询图。通过将邻接矩阵k的幂设置为2来收集校正的查询图,用于从实体提取到所连接的实体的2长度路径。为了评估问题编辑模型,我们使用3, 514个校正的查询图作为测试数据。在可回答的问题中,90%的查询图用于培训,10%用于验证。表4显示了问题生成模型的性能。
在实验中,我们采用光束尺寸为3的光束搜索。基于BLEU4、ROUGE-L和Q-BLEU4(Nema和Khapra 2018)来评估模型。我们使用Transformer作为seq2seq基线模型。编码器和解码器都是基于BERT的模型。最新的问题生成模型RefNet(Nema et ai.2019)也作为基线模型复制在我们的数据集上。为了将RefNet应用于数据集,我们将答案实体输入到答案编码器,并输入单词序列
表表4:问题产生的表现。
向通道编码器保留校正的查询图。
对培训前问题编辑模式的影响也进行了确认。在表4中,基于增强学习(RL)的模型的性能优于所有基线模型。比较Du-alGenNet和GenTagNet, 发现用序列标记作为问题编辑模型比用seq2seq模型更好。此外,问题编辑模型的预训练提高了性能。
本文还结合两个阶段的最佳模型——图形加权语义匹配网络(GWSMNet)问答和GenTagNet问答器,对流水线工作流的表现进行了评价。问题生成模型的性能由
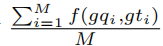
测量,其中M是图形加权语义匹配网络(GWSMNet)(LSTM)正确预测的不可回答问题的数目,gqi是GenTagNet生成的第i个问题,gti是基本真问题,f是度量(例如,BLEU4)。在误差传播的影响下,GenTagNet的BLEU4、ROUGE-L和QBLEU4分别为44.72、65.31和59.11。
讨论
在本部分中,我们首先分析了问答模型对不同类型可回答和不可回答问题的表现。然后,分析了问题生成模型在管线工作流中以及端到端方式训练的表现。最后,分析了不同奖励函数对问题生成模型的影响。
不同类型问题回答模型的评价
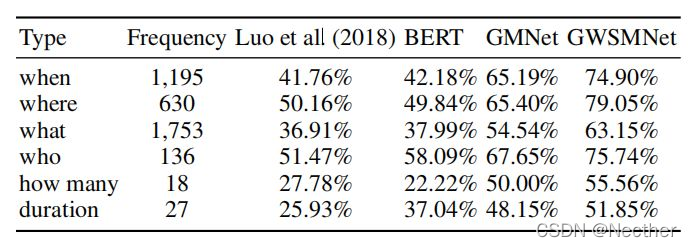
如表2所示,问题类型的分布不平衡。进一步分析了问答模型在不同问题类型下的性能。可回答和不可回答问题的表现分别示于表5和表6。比较了Looet ai(2018)、BERT、图形匹配网络(GMNet)和图形加权语义匹配网络(GWSMNet)模型的性能。实验结果表明,不同问题类型的不平衡影响模型的表现。然而,我们发现,与“何时”和“what”这两个较大的问题类型相比,所有模型在问题类型“T/F”上均取得了良好的表现。此外,结合图形级信息的模型,即图形匹配网络(GMNet)和图形加权语义匹配网络(GWSMNet),在“多少”和“持续时间”的问题类型上实现了更好的性能,这需要知识库中多个事件之间的推理。
表5:回答不同问题类型可回答问题的答问表现。
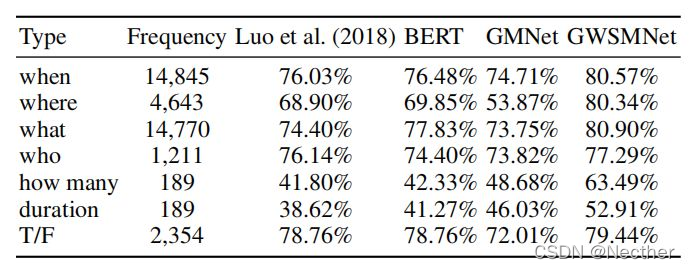
表6:对不同类型不可回答问题的答问情况。
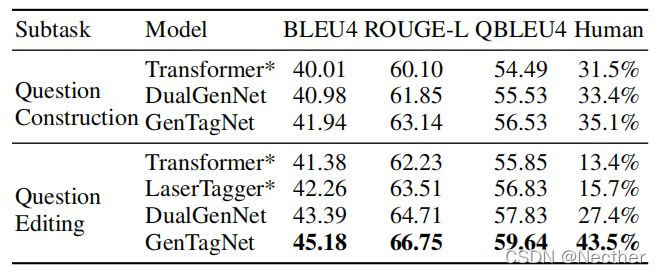
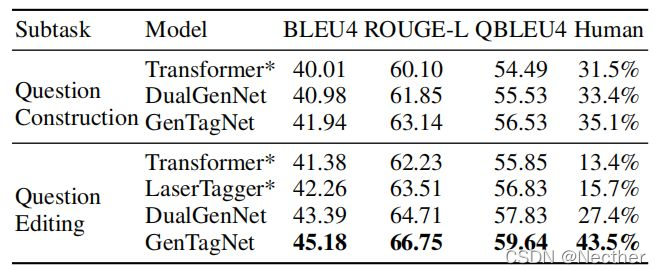
问题生成模型中管道模型和端到端模型的评价
基于增强学习(RL)的模型,如DualGenNet和GenTag-Net,是端到端可训练模型。我们实现transformer和LASERTAGGER作为基线模型。也就是说,在问题生成模型中,将问题构造和问题编辑看作两个子任务。表7显示了流水线工作流中以及端到端方式的模型的性能。后跟*符号的模型表示在流水线工作流中训练的模型。实验结果表明,采用带基线算法的REINFORCE,基于问题构造模型的输出对问题编辑模型进行奖励,最终效果良好。
表7:管道工作流中的模型性能和端到端方式。
还进行人类评价以验证测量。我们从数据集中随机抽取了100个校正后的查询图。从两个子任务中的模型产生的问题显示给三个注释器,并且要求它们选择哪个更好地考虑完整性、流畅性和回答性。我们报告注释者偏爱每个模型生成的问题的评估结果。在问题构造和问题编辑中,注释者更喜欢GenTagNet,尤其是在问题编辑中。
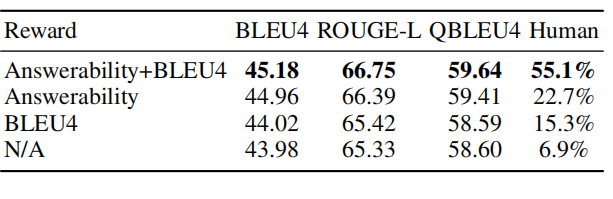
回报函数的性能
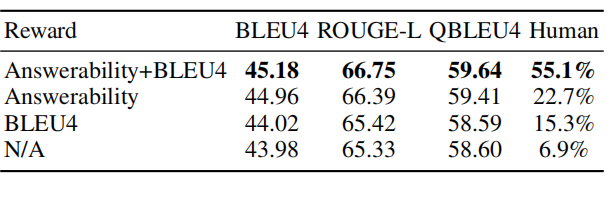
在问题生成模型中,我们使用奖励函数,将可回答性评分和BLEU相结合。可回答性评分衡量问题是否包含问题类型、实体和关系。相反,BLEU评分测量了候选句和参考句中n-gram的重叠。在本节中,我们进行切除研究来分析奖励功能的影响。在表8中,我们比较了在不同奖励函数下的问题生成模型GenTagNet。N/A表示模型中不使用奖励函数。
表8显示,当不同时考虑可回答性和流利性的奖励函数时,性能降低。我们随机抽样100个纠正的查询图,并将GenTagNet生成的带有四个奖励函数的问题显示给三个注释器。注释器被要求选择哪个更好。因此,注释者更倾向于使用可回答性和流利性作为奖励函数的GenTagNet模型,评价结果表明,可回答性评分能更好地评价生成的问题是否流利和合理。
表8:GenTagNet中不同回报的表现。
结论
本文主要研究开发一套完整的PKBQA查询系统,作为PKBQA的应用。由于人们经常混淆事件,提出个人知识库(KB)无法回答的问题,我们讨论基于个人知识库(KB)纠正无法回答的问题。我们提出了一个由问答模型和问题生成模型组成的系统。问题回答模型通过生成候选查询图基于个人知识库(KB)提取答案。对于无法回答的问题,将建议与用户意图相关的修正查询图。问题生成模型以修正的查询图作为输入,生成自然语言可回答的问题。实验结果表明,该方法具有良好的应用前景。
在这项工作中,我们的系统纠正了无法回答的问题,帮助用户只用单句询问他们想要知道的事实。通过用户交互纠正无法回答的问题是今后要解决的一个挑战性问题。
致谢
这项研究得到了台湾科技部的部分支持,其赠款为MOST-109-2634-F-002-040-、MOST-109-2634-F-002-034-、MOST-109-2218-E-009-014-,并得到台湾中央研究院的AS-TP-107-M05。














 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









