






公众号 系统之神与我同在
信息提取:
我们通常从非结构化源提取的结构类型分为四种类型:实体、实体之间的关系、描述实体的形容词以及高阶结构(如表和列表)。实体通常是名词短语,并且包括在非结构化文本中的一个到几个标记。关系是以预定义的方式在两个或多个实体上定义的。在许多应用中,我们需要将给定的实体与描述该实体的形容词的值相关联。这个形容词的价值通常需要通过组合遍布实体周围许多不同单词的软线索来导出。现在,提取系统的范围已经扩大,以包括从不同类型的文档中提取不是这样的原子实体和平坦记录,而是更丰富的结构,例如表、列表和树。
标签非结构文本:
许多提取系统通过标记的非结构化文本播种。标记非结构化文本的集合需要冗长的标记工作。然而,这种努力并非完全可以避免,因为即使当提取系统被手动编码时,为了评估其准确性,也需要基础真值。标记的非结构化源比结构化数据库显著更有价值,因为其提供关于实体的上下文信息,还因为实体在非结构化数据中出现的形式通常是其在数据库中出现的非常嘈杂的形式。
提取方法:
我们将用于信息提取的方法分为两个维度:手工编码或基于学习、基于规则或统计。手工编码的系统需要人类专家定义规则或正则表达式或程序片段来执行提取。基于规则的提取方法由硬谓词驱动,而统计方法则基于谓词命中的加权和做出决策。基于规则的方法更容易解释和开发,而统计方法对非结构化数据中的噪声更具鲁棒性
实体提取:基于规则的方法
规则的形式和表述
基于规则的系统具有悠久的使用历史,并且许多不同的规则表示格式多年来已经演变。这包括公共模式规范语言(CSPL)[10]及其衍生物,如JAPE[72],如Rapier[43]中的模式项和列表,如WHISK[195]中的正则表达式,如Avatar[113, 179]中的SQL表达式,以及如DBLife[190]中的Datalog表达式。我们以通用的方式描述规则,捕捉大多数这些语言的核心功能。
基本原则的形式是:“语境模式——>行动”。上下文模式由一个或多个标记模式组成,这些标记模式捕获一个或多个实体的各种属性以及它们在文本中出现的上下文。标记模式由模式组成,该模式大致是在文本中标记的特征上定义的正则表达式和可选的标签。这些特性可以是token的任何属性、上下文或token出现的文档。
规则的动作部分用于表示各种类型的标签动作:将一个实体标签分配给一系列token,将一个实体标签的开始或结束插入某个位置,或分配多个实体标签。大多数基于规则的系统是级联的;在多个阶段中应用规则,其中每个阶段将输入文档与作为下一阶段的输入特征的注释相关联。例如,从规则注释器的两个阶段创建联系人地址的提取器:第一阶段使用实体标签如人名、地理位置如道路名、城市名和电子邮件地址来标记token。第二阶段以第一阶段的输出作为附加特征定位地址块。
token的特点
句子中的标记通常与通过以下标准中的一个或多个获得的特征包相关联:
- 表示token的字符串。
- 符号的正字类型,可以取形式大写词、小写词、混合格词、数字、特殊符号、空间、标点等值。
- 记号的一部分。
- token出现的字典列表。通常,这可以被进一步细化以指示token是否与字典的开始、结束或中间词匹配。例如,与城市名称字典的第一个单词匹配的“New”等标记将与一个特性“DictionaryLookup = startofcity”相关联。通过前面的处理步骤附加注释。
确定单一实体的规则
承认一个完整实体的规则包括三种模式:
- 在实体开始之前捕获上下文的可选模式。
- 匹配实体中的token的模式。
- 在实体结束之后捕获上下文的可选模式。
对于某些实体类型,特别是像书名这样的长实体,定义单独的规则来标记实体边界的开始和结束会更有效。这些标记是独立的,两个开始和结束标记之间的所有标记都称为实体。
关系抽取
给定一组固定的关系类型R,每个关系类型涉及一对实体类型,我们的目标是识别输入自然语言文档中R中的所有关系事件,其中所有实体都已被标记。
基于模板的方法:
使用模式挖掘关系,基于触发词/字符串等等
基于依存句法
使用模式挖掘关系关系挖掘模式
●支持大多数关系抽取系统的基本概念是关系模式
●它是一个表达式,当与文本片段相匹配时,它能够标识出相应的关系实例。
例如:
●词典项
●通配符词性句法关系
●正则表达式中可用的灵活规则
Hearst(1992)的模式清单Hearst提出了一个开创性的模式清单,用于提取分类关系is-a的实例:

使用模式挖掘关系Hearst(1992)的模式清单该方法准确率高,但是召回率低
仅仅包含了is-a关系
之后,被扩展到了其它关系上
基于依存句法
通常可以以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定。流程为:

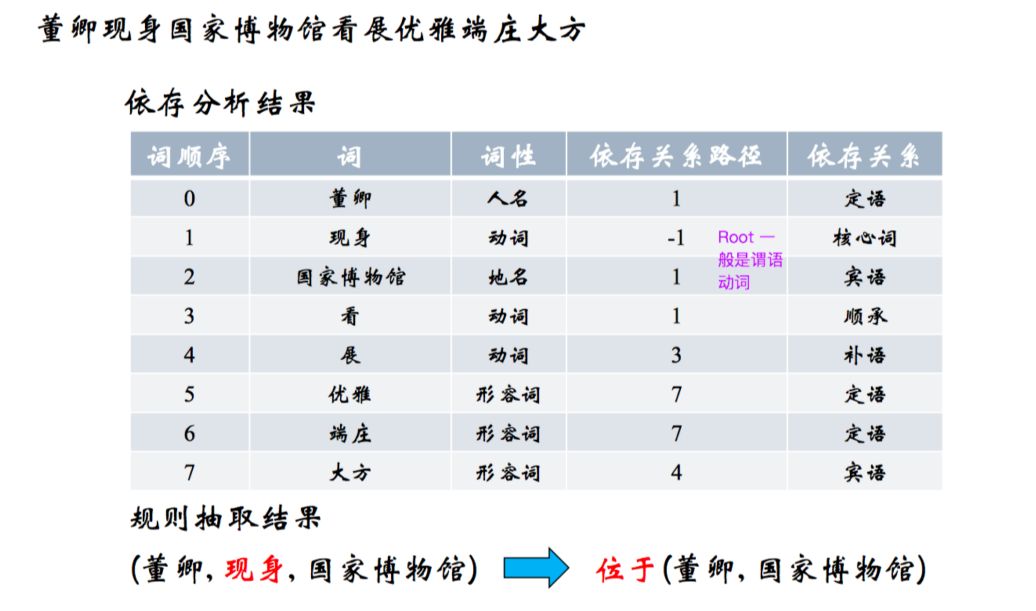
基于模板的实体关系抽取
优点:
●人工规则有高准确率(high- precision
●可以为特定领域定制( (tailor)
●在小规模数据集上容易实现,构建简单
缺点:
●低召回率(low- recall)
特定领域的模板需要专家构建,要考虑周全所有可能的 pattern很难,也很费时间精力需要为每条关系来定义 pattern
●难以维护可移植性差
关系学习的算法有很多的机器学习算法可以进行关系学习,但是有一些是更适合关系学习的
●基于特征向量的方法
●从上下文信息、词性、语法等中抽取一系列特征核分类
●关系特征可能拥有复杂的结构
●序列标注方法
●关系中参数的跨度是可变的
基于特征向量的方法定义:
从上下文信息、词性、语法等中抽取一系列特征,来训练一个分类器(如朴素贝叶斯、支持向量机、最大熵等),然后完成关系抽取对于一组训练数据.

核分类
两个实体的相似度可以在高维的特征空间中计算得到而不需要枚举特征空间的各个维度。
序列标注
●在某些特殊的情况下,关系抽取可以退化为序列标注问题
●例如对于人物传记的百科全书文章,对于其中提到的主要实体,其他的实体都是和它相关的。因此只需要找出其他实体与这个主要实体之间的关系即可。此时没有必要枚举所有的实体对,因为关系是二分类的且其中的一个实体已经给出了


弱监督关系抽取
为关系抽取生成大量的标记数据是耗费时间、精力和财力的。
弱监督技术出现的两个原因是:
减少构建标记数据所需要耗费的人力。
充分利用比较容易获得的无标记数据。
Label Propagation
2006年, Jinxiu在ACL会议上提出标注传播算法( Label propagation),这是一种基于图的弱监督学习方法
●基于图的学习方法都是建立在这样的假设基础上:具有相同特征的两个节点倾向于属于同一个类别而关系抽取任务的假设前提则是:如果两个关系实例相似度很高,即特征集合相似且语法结构相似,则它们将倾向于属于同一种关系类型。
●可以看出,关系抽取任务的假设前提与基于图的学习方法的假设是吻合的因此,可以利用图来建立关系抽取模型,然后利用少部分有标签的数据辅助大量未标签的数据进行非监督的学习
方法:
将所有的实体对看作是图上的节点,将实体对间的距离看作边。
把一部分标注好的节点看作源头向其他节点传播,而权重值越高的边上传播的速度越快。
将相似度高的节点聚为一类,类别信息通过传播过来的标注信息来判别。
协同( Co-learning)方法
●2011年, A Vitas提出了一种新的弱监督方法——协同学习(Co-learning)方法
●基本流程:
●选择2个不同的分类器,
●使用相互独立的特征在2个训练集上训练,并分别在未标注集上测试
●选取置信度高的实例扩展到另一个分类器的训练集中
●如此迭代若干次,当精度达到阈值时停止。
远程监督
●假设对于所有的上下文中有一定比例的实例是正例,这个比例对于不同的关系可能会有不同
建模过程
●扩展 Hoffmann等人的图形模型以强制执行百分比约束
●使用感知器进行更新训练
●通过交叉验证使用网格搜索来找到关系的最佳百分比
训练阶段
●使用NET( named entity tagger)标注 persons organizations /FH locations
●对在 freebase中出现的实体对提取特征,构造训练数据;
●训练多类别逻辑斯特回归模型,
测试阶段
●使用NET( named entity tagger)标注 persons、 organizations FH locations
●在句子中出现的每对实体都被考虑做为一个潜在的关系实例,作为测试数据
●使用训练后的模型对实体对分类。
无监督关系抽取
●出现的原因由于有监督和半监督机器学习方法需要事先确定关系类型,而实际上在大规模语料中,人们往往无法预知所有的实体关系类型有些研究者基于聚类的思想,利用无监督机器学习的方法,尝试解决这个问题
一般过程:
实体对聚类
●首先采用某种聚类方法将语义相似度高的实体对聚为一类
●和关系标记
●再选择具有代表性的词语来标记这类关系
基于深度学习的关系抽取
词嵌入
模型一共包括5层结构
输入层:将句子输入到模型中
Embedding层:将每个词映射到低维空间
LSTM层:使用双向LSTM从 Embedding层获取高级特征
Attention层:生成一个权重向量,通过与这个权重向量相乘,使每一次迭代中的词汇级的特征合并为句子级的特征
输出层:将句子级的特征向量用于关系分类,使用 softmax分类器
数据融合
知识图谱ⅤS关系数据库
优势:包含语义信息,可进行一定的推理
优势:形式更灵活,可扩展性更好
不足:天生缺乏直接的有效处理工具,大规模图谱数据处理常常借助于数据库技术;
不足:知识图谱不能替代数据库,二者互有所长
为什么需要知识融合
数据清洗构建的知识图谱可能存在异构
知识融合是知识图谱应用的重要预处理步骤
数据集成
需要同时利用或融合多个不同来源的知识图谱不同源的知识图谱可能存在重叠的知识
知识融合的目标
合并多个知识图谱
- 解决本体层的匹配
等价类/子类等价属性/子属性
2.解决实例层的匹配
等价实例
本体匹配方法
●基础匹配器
●文本匹配方法
●结构匹配方法
●知识表示学习方法
基础匹配器—字符串匹配器
●编辑距离



汉明距离

子串相似度


N-Gram:将文本转换为集合,除了可以用符号分格单词外,还可以考虑用 n gram分割单词,用n gram分割句子等来构建集合,计算相似度


文本匹配器的原理
思想:将文档变为向量形式,通过向量相似度实现文档匹配。
本体中的概念和属性往往有大量相关的文本信息标签、注释、描述、等等。
将待匹配的对象的相关文本组织为文档形式,再转化为文档向量。
实例匹配:
异名同义,同名异义
指代
对真实世界中实例的某种描述方式,包括ID、名字、绰号、文本、图、URI等等
匹配
给定任意两个指代信息(可以相近也可以不同),判断其描述的是否是同一实例
实例匹配
这里指对知识图谱中的实例进行匹配的过程
基于推理的匹配方法
利用本体语义构造推理规则
寻找更多的匹配实例或者过滤错误的匹配
优点:易于实现
缺点:真实知识图谱中可用于实例匹配的语义信息非常有限;大规模推理的性能
直观的方法——基于实例对相似度的匹配
√设计相似度匹配器
时间复杂度:O(N2)
√优点:易于实现
缺点:复杂度高,无法处理大规模实例匹配
基于分块的大规模实例匹配
核心思想:避免做pair- wise comparison将复杂度高的大规模匹配计算转化为众多复杂度低的小规模匹配计算
设计分块规则
匹配计算只在块内部进行
复杂度:O(k*n2),k个块,n远小于N
优点:大规模实例匹配的高效解决方案
不足:存在匹配遗漏问题
分块法
用聚类或规则将可能匹配的实例作为一个块
把所有实例间的比较转化为块中实例的匹配
典型的“分治法”思想的应用
无论使用什么属性分块技术,都面临着两个矛盾的问题
(1)匹配效果:分块越细,造成的分块冗余越多,但未命中的匹配也越少,即匹配效果会更好;
(2)匹配性能:分块越细,造成的不必要匹配计算越多,降级了匹配的性能。所以,很多基于属性分块的方法都力图在匹配效果和匹配性能上达到平衡。
实体链接
实体链接是指将文档中出现的文本片段,即实体指称( entity mention)链向其在特定知识库( Knowledge Base)中相应条目entry)的过程。
例如:
86年的电视剧西游记是对小说西游记最经典的改编。
链接结果:
86年的电视剧西游记(1986年杨洁执导央视版电视剧)是对小说西游记(中国古典长篇小说)最经典的改编
实体链接的方法简单的分类:
基于概率生成模型的方法
基于主题模型的方法
基于图的方法
基于深度学习的方法
无监督方法
基于概率生成模型的方法
利用M&W相似度可以计算出候选实体与上下文中其他实体的相关性。
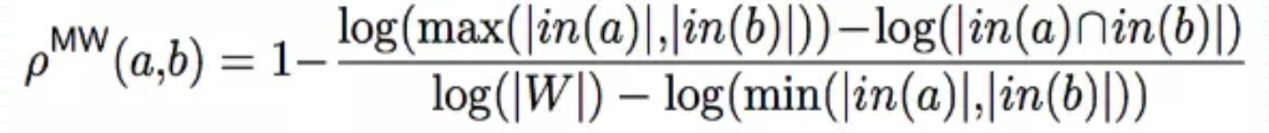
基于主题模型的方法
强假设:
同一篇文本中的实体应当与文本的主题相关
和科技、手机等有关文章也更有可能出现苹果公司,而不是水果。
基于图的方法
重启随机游走:
基本思想是给定一个图,游走者从某个顶点或一系列顶点开始遍历该图。在任意一个顶点,游走者对于下一步行动有2种选择:
1.以概率1-c随机选择一条关联到当前顶点的边以游走到某个邻居顶点
2.以c的概率随机跳转到图中任意一个顶点每次游走后,均将得到一个概率分布,将该概率分布作为下一次游走的输入,反复迭代。当满足一定前提条件时,该概率分布将会收敛到一个稳定值。
基于深度学习的方法
借助 BiLSTM、CNN等计算相似度后再基于图
基于无监督的方法AAAI18阿里 Colink
协同训练算法:
在该框架中定义两个不同的模型:一个基于属性的模型fatt和一个基于关系的模型frel。
这两个模型会进行二元分类预测,将一组给定实体对分类为正例(链接的)或负例(非链接的)。
该协同训练算法以迭代的方式不断增强这两个模型。
知识推理
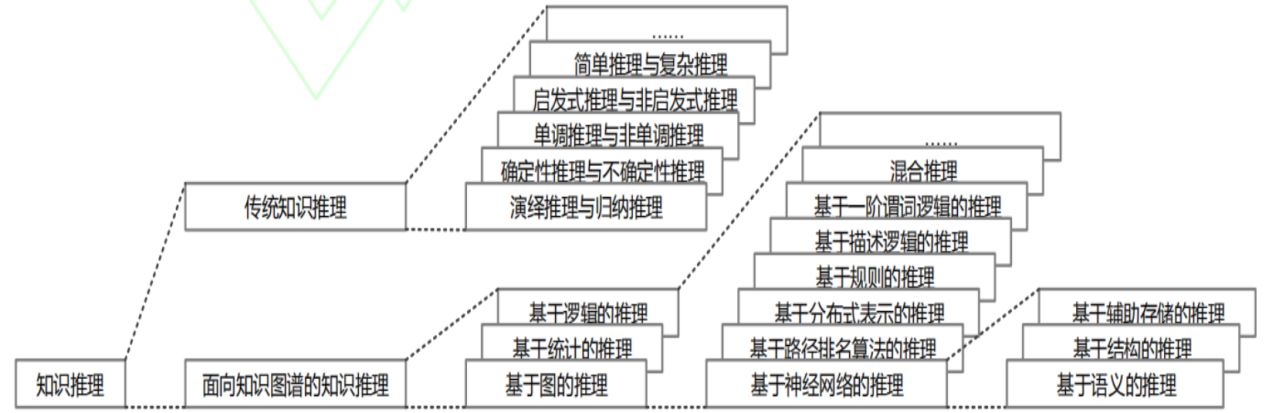
知识推理的方法
基于逻辑阶谓词逻辑、描述逻辑等利用规则推理
基于统计——机器学习、统计学习
基于图——Path ranking、神经网络
基于逻辑规则:
①自然性
②适宜于精确性知识的表示,而不适宜于不确定性知识的表示
③易实现
④与谓词逻辑表示法相对应。
基于统计学习的知识推理
马尔可夫逻辑网
概率软逻辑
贝叶斯推断
基于图的知识推理
路径排序算法( Path anking algorithm-PRA)
不完备知识库的关联规则挖掘( Association rule Mining under Incomplete Evidence, AMIE)
基于神经网络的知识推理
基于语义的推理
基于语义的推理建立在挖掘和利用语义信息的基础上,例如实体和关系的名称、描述以及上下文信息等
基于结构的推理
基于结构的推理是指利用知识库中三元组内部或相互之间的结构联系进行推理,常用于多步推理问题当中。
神经网络中基于多跳的推理
多跳关系:三元组之间并非相互孤立。譬如,一个三元组的尾实体可能是另一个三元组的头实体,这样的两个三元组可以构成一个五元组路径,而此时该五元组的头尾实体之间可能隐含了某种可以表示的关系。
神经网络中基于组合路径的推理
组合路径:针对多个三元组连接而成的多元组,其首尾实体之间可能存在多条路径。即,首尾实体之间可能由若干多元组构成多种不同的路径形式
组合路径&RNN
缓解了路径排序算法( Path Ranking algorithm PRA)无法共享参数及参数量大的共性问题,允许跨多个关系类型共享参数进行推理除了建模每步关系,还建模对应的实体,共同推理所有的关系、实体和实体类型。















 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









