






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Ayoosh Kathuria
编译:ronghuaiyang
有小伙伴提到想要了解YOLOv3,其实网上有很多讲解这个算法的内容,很多都非常的好,这篇我也非常的喜欢,图文并茂,非常的详细,非常的通俗易懂,分享给大家。
YOLO是一种快速的目标检测算法。虽然它不是最精确的目标检测算法,但在需要实时检测时,它是一个非常好的选择,不会损失太多的准确性。
YOLO的第三个版本发布了,本文主要解释一下YOLOv3中引入的变化。这篇文章不会从头开始解释YOLO是什么。我假设你知道YOLOv2是如何工作的。如果不是这样的话,我建议你看看之前的论文,了解一下YOLO是如何工作的。
YOLOv3: Better, not Faster, Stronger
YOLOv2论文的官方标题: “YOLO9000: Better, Faster, Stronger”,看起来就像是一款儿童牛奶健康饮料,而不是一种目标检测算法。
在当时,YOLO 9000是最快的算法,也是最精确的算法之一。然而,几年过去了,它的准确率不如RetinaNet了,SSD在准确性上也超过了它。然而,它仍然是最快的。
但是在YOLOv3中,这种速度已经被用来提高准确性。早期的版本在Titan X上的运行速度为45FPS,而当前版本的速度约为30FPS。这与底层架构Darknet复杂性的增加有关。
Darknet-53
YOLOv2使用了定制的darknet-19,这是一个19层网络,添加了11个层用于对象检测。对于一个30层的架构,YOLOv2经常在小物体检测方面遇到困难。这是由于随着层的下采样,细粒度特征的丢失造成的。为了解决这个问题,YOLOv2使用了一个恒等映射,将来自前一层的特征映射和当前层特征连接起来,以捕获低层特征。
然而,YOLOv2的架构仍然缺少一些最重要的元素,而这些元素现在是大多数最先进算法的核心,没有残差块,没有跳跃连接,没有上采样,而YOLOv3包含了所有这些。
首先,YOLOv3使用了Darknet的一个变体,该变体最初在Imagenet上训练了53层网络。在检测任务上,它又增加了53层,变成了106层的全卷积的底层架构。这就是YOLOv3相对于YOLOv2慢的原因。现在YOLO的结构变成这样了。
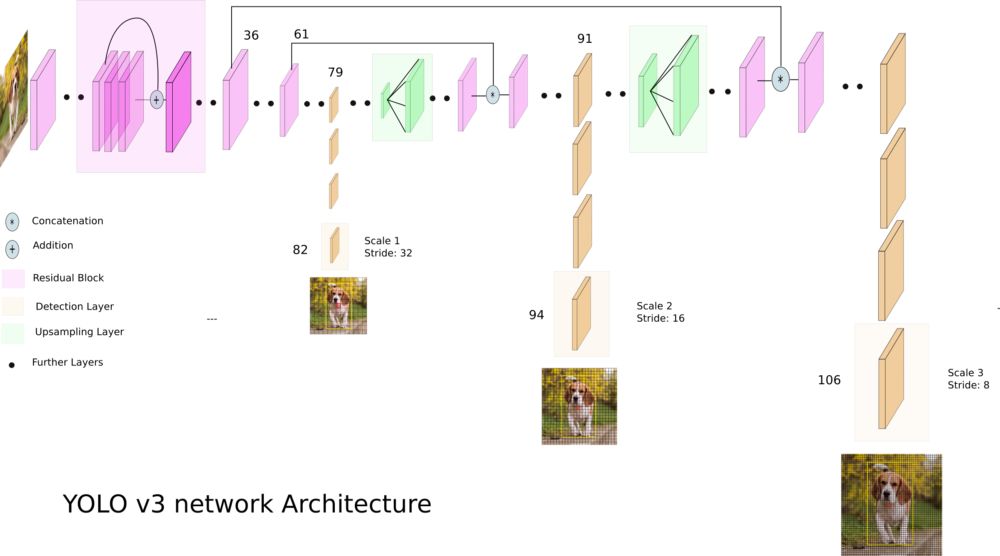
在3个尺度上做检测
新的结构拥有残差,跳跃连接和上采样。v3最显著的特征是它在三个不同的尺度上进行检测。YOLO是一个全卷积网络,它的最终输出是通过在feature map上使用一个1×1的卷积核生成的。在YOLOv3中,检测是通过在网络中三个不同位置的三个不同大小的feature map上应用1×1卷积核来完成的。
卷积核的形状为1×1 x (B x (5 + C))。这里B是feature map上一个单元格可以预测的包围框的数量,“5”是4个包围框的属性和一个对象的置信度,C是类的数量。在YOLOv3对COCO的训练中,B = 3, C = 80,所以卷积核的大小是1 x 1 x 255。该卷积核生成的feature map具有与前一个feature map相同的高度和宽度,并且具有上面说过的检测属性。
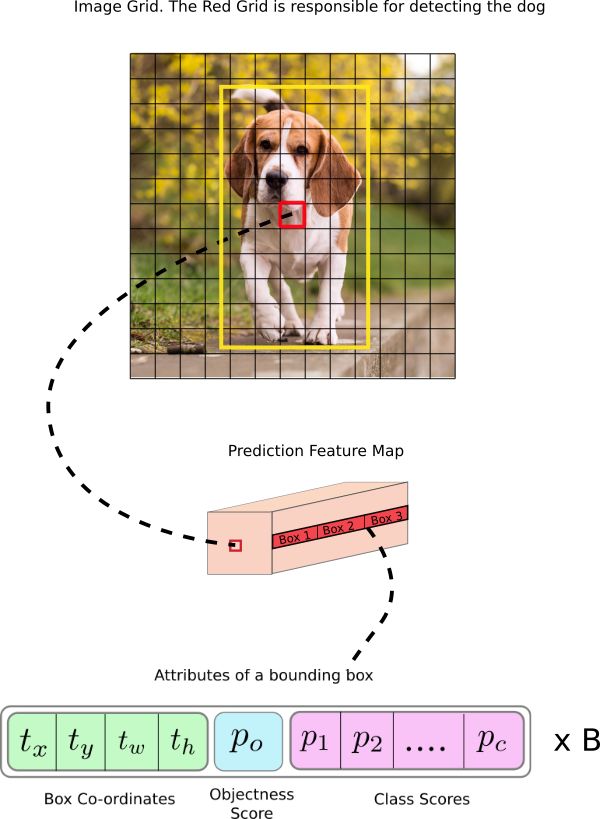
在我们继续之前,我想指出网络的步长,或者一个层对输入进行下采样的比例。在下面的例子中,假设我们有一个大小为416 x 416的输入图像。
YOLOv3在三个尺度下进行准确的预测,分别将输入图像的维数降采样32、16、8。
第一个检测是由第82层进行的。对于前81层,网络对图像进行下采样,使得第81层的步长为32。如果我们有一张416 x 416的图像,那么得到的feature map的大小就是13 x 13。这里使用1×1卷积核进行了一次检测,得到了一个13×13×255的检测特征图。
然后,对第79层的feature map进行几层卷积,然后用上采样2倍到26x26。然后,这个feature map与第61层的feature map拼接起来。然后,再对组合之后的feature maps进行几个1x1卷积层的处理,以融合来自前一层(61)的特征。然后,第94层进行第二次检测,得到26×26×255的检测特征图。
同样的过程也会被重复,在第91层的feature map与第36层的feature map进行深度连接之前,只对少数卷积层进行处理。像以前一样,后面的几个1×1卷积层融合来自前一层(36)的信息。我们在第106层对第3个检测进行最后处理,生成大小为52 x 52 x 255的feature map。
更好的检测小物体
不同层的检测有助于解决检测小物体的问题,这是YOLOv2经常遇到的问题。上采样层与前一层连接在一起,有助于保留对检测小物体有帮助的细粒度特征。
13 x 13层负责检测大的物体,52 x 52层检测小的物体,26 x 26层检测中等物体。下面是不同层在选择不同物体的比较分析。
anchor boxes的选择
YOLO v3,共使用9个anchor boxes。每个尺度三个。如果你正在自己的数据集上训练YOLO,那么应该使用K-Means聚类来生成9个anchor boxes。
然后,将按维度降序排列。为第一个尺度分配三个最大的anchor boxes,为第二个尺度分配下三个anchor boxes,为第三个尺度分配最后三个anchor boxes。
每张图像更多的边界框
对于相同大小的输入图像,YOLOv3比YOLOv2预测更多的边界框。例如,在416 x 416的分辨率下,YOLOv2预测了13 x 13 x 5 = 845个盒子。在每个网格单元中,使用5个anchor boxes检测到5个边界框。
另一方面,YOLOv3在3种不同的尺度上预测边界框。对于416 x 416的相同图像,预测框的数量为10,647。这意味着YOLOv3预测的边界框数量是YOLOv2的10倍。你可以很容易地想象为什么它比YOLOv2慢。在每个尺度上,每个网格可以使用3个anchor boxes预测3个边界框。由于有3个尺度,所以每个尺度使用的anchor boxes总数为9,每个尺度3个。
损失函数的变化
之前,YOLOv2的损失函数是这样的。
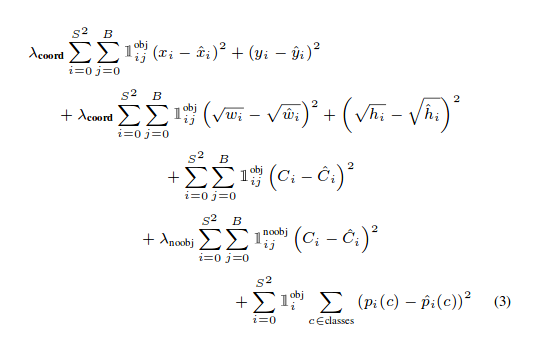
我知道这有点吓人,但请注意最后三项。其中,第一项,惩罚的是负责预测物体的边界框中是否有物体的得分的预测(理想情况下是1)。第二项,对于边界框中没有物体时(理想情况下,得分应该是零)。最后一项,惩罚了对检测框中预测物体的类别的预测。
YOLOv2中的最后三项是平方误差,而YOLOv3中的,它们被交叉熵误差所取代。换句话说,YOLOv3中的物体的置信度和类预测现在通过逻辑回归进行预测。
在训练检测器时,我们为每个ground truth框指定一个边界框,其锚点与ground truth框重叠最大。
别再softmax分类了
YOLOv3现在对图像中检测到的物体进行多标签分类。
在YOLO的早期,作者习惯于对类别得分进行softmax分类,并将得分最高的类作为包围框中包含的物体的类。这已经在YOLO v3中进行了修改。
Softmaxing是基于这样的假设的:类是互斥的,或者简单地说,如果一个对象属于一个类,那么它就不能属于另一个类。这在COCO数据集中工作得很好。
然而,当我们在数据集中有像Person和Women这样的类时,上述假设就失败了。这就是为什么YOLO的作者没有softmax的原因。相反,使用逻辑回归预测每个类的得分,并使用阈值预测对象的多个标签。得分高于此阈值的类被分配到该框中。
Benchmarking
YOLOv3在COCO mAP 50基准测试中的表现与RetinaNet等其他先进的检测器相当,但速度要快得多。它也比SSD和它的变体更好。这是这篇论文的性能比较。
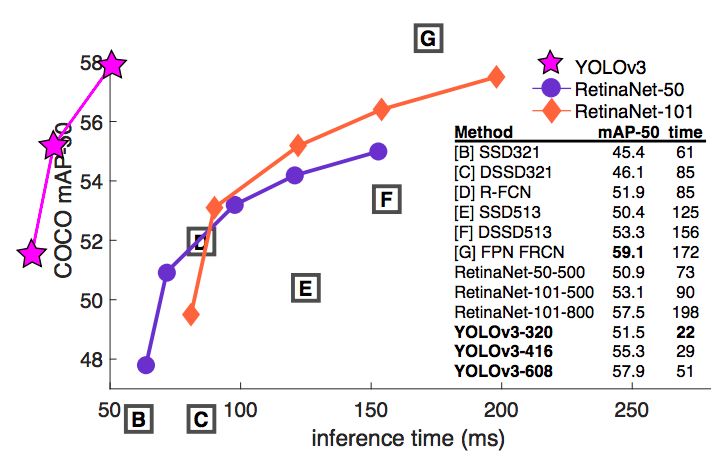
但是,但是,但是,YOLO在COCO的基准测试中输掉了,因为COCO基准测试中拒绝一个检测的IoU的值更高。我不打算解释COCO基准测试是如何工作的,因为它超出了我们今天的范围,但是COCO 50基准测试中的50是对预测的边界框与物体的ground truth框对齐程度的度量。这里的50对应于0 .5的IoU。如果预测与ground truth框之间的IoU小于0.5,则该预测将被归类为错误定位并标记为假阳性。
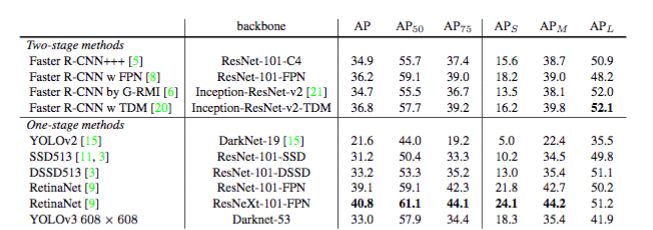
在基准测试中,如果这个数字更高(比如COCO 75),则需要更完美地对齐这些框,以避免被评估指标拒绝。这里是YOLO被RetinaNet超越的地方,因为它的边框没有像RetinaNet那样对齐。下面是针对各种基准测试的详细表。
做几个实验玩玩
您可以使用本Github repo (https://github.com/ayooshkathuria/pytorch-yolo-v3)提供的代码在图像或视频上运行检测器。该代码需要PyTorch 0.3+、OpenCV 3和Python 3.5。设置repo,你可以在其上运行各种实验。
不同的尺度
下面我们来看看不同的检测层会检测到什么。

在尺度1的检测中,我们看到一些较大的物体被选中,但是有几辆车没有检测到。

尺度2上什么也没有检测到。

在最大尺度(3)下进行检测。看到只有小的物体被检测到了,而这些在尺度1下没有检测到。
不同的输入分辨率

图像输入分辨率: 320 x 320

图像输入分辨率: 416 x 416

现在,我们比之前少检测出一张椅子。
现在,出现了误检,右边的“Person”。
在我们的例子中,较大的输入分辨率帮助不大,但它们可能有助于检测带有小物体的图像。另一方面,较大的输入分辨率会增加推理时间。这是一个需要根据应用程序进行调优的超参数。
你可以通过repo试验其他指标,如批大小、物体可信度和NMS阈值。ReadMe文件中已经提到了所有内容。
从头实现YOLOv3
如果您想在PyTorch中自己实现YOLOv3检测器,这里有一系列教程,我在Paperspace上也编写了这些教程。现在,如果你想学习本教程,我希望你对PyTorch有基本的了解。如果你正在从一个初级PyTorch用户过渡到中级PyTorch用户,那么本教程非常适合你。
 —
END—
—
END—
英文原文:

●新手必看的Top10个机器学习算法(这些都学会了你就是老手了)
更多历史文章请关注公众号,点击“历史文章”获取

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









