






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Will Badr
编译:ronghuaiyang
鹳会接生孩子吗?虽然它已经在相关性和因果关系的背景下得到了理论上的证明,但本文探讨了相关性以及它与因果关系的不同之处。

器学习模型的好坏取决于你所拥有的数据。这就是为什么数据科学家可以花费数小时对数据进行预处理和清理。他们只选择对结果模型的质量贡献最大的特征。这个过程称为“特征选择”。特征选择是选择能够使预测变量更加准确的属性,或者剔除那些不相关的、会降低模型精度和质量的属性的过程。
数据与特征相关被认为是数据预处理中特征选择阶段的一个重要步骤,尤其是当特征的数据类型是连续的。那么,什么是数据相关性呢?
数据相关性:是一种理解数据集中多个变量和属性之间关系的方法。使用相关性,你可以得到一些见解,如:
一个或多个属性依赖于另一个属性或是另一个属性的原因。
一个或多个属性与其他属性相关联。
那么,相关性为什么有用?
相关性可以帮助从一个属性预测另一个(伟大的方式,填补缺失值)。
相关性(有时)可以表示因果关系的存在。
相关性被用作许多建模技术的基本量
让我们更仔细地看看这意味着什么,以及相关性是如何有用的。相关性有三种类型:
正相关:表示如果feature A增加,feature B也增加;如果feature A减少,feature B也减少。这两个特征是同步的,它们之间存在线性关系。
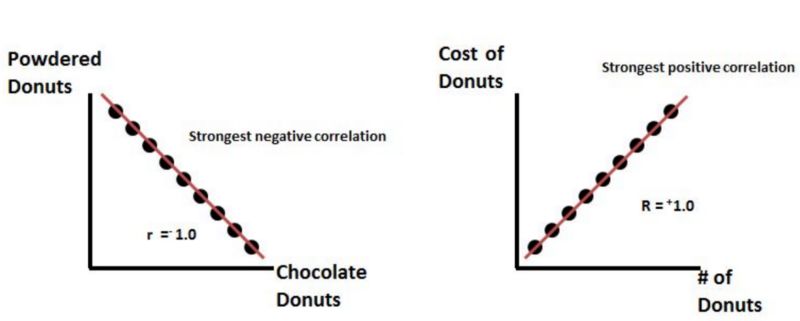
负相关:表示如果feature A增加,feature B减少,反之亦然。
无相关性:这两个属性之间没有关系。
这些相关类型中的每一种都存在于由0到1的值表示的频谱中,其中微弱或高度正相关的特征可以是0.5或0.7。如果存在强而完全的正相关,则用0.9或1的相关分值表示结果。
如果存在很强的负相关关系,则表示为-1。
如果你的数据集具有完全正或负的属性,那么模型的性能很可能会受到一个称为“多重共线性”的问题的影响。多重共线性发生在多元回归模型中的一个预测变量可以由其他预测变量线性预测,且预测精度较高。这可能导致歪曲或误导的结果。幸运的是,决策树和提升树算法天生不受多重共线性的影响。当它们决定分裂时,树只会选择一个完全相关的特征。然而,其他算法,如逻辑回归或线性回归,也不能避免这个问题,你应该在训练模型之前修复它。
我该如何处理这个问题?
有多种方法来处理这个问题。最简单的方法是删除完全相关的特性。另一种方法是使用降维算法,比如PCA。
Spearman VS Pearson相关矩阵:
Spearman和Pearson是计算两个变量或属性之间相关性强弱的两种统计方法。Pearson相关系数可用于线性关系的连续变量。举个例子:
from scipy.stats import pearsonr
import matplotlib.pyplot as plt
#Create two random variable
X = [1,2,3,4,5,6,7,8,9,10,11,12,13]
Y = [7,8,8,11,10,11,12,15,20,14,16,15,19]
#plot the variables to show linearity
plt.scatter(X,Y)
plt.show()
要打印Pearson系数评分,只需运行 pearsonr(X,Y),结果为: (0.88763627518577326,5.1347242986713319e-05),其中第一个值为Pearson相关系数,第二个值为p值。0.8表示变量呈高度正相关。
如果变量之间存在非线性关系,则可以使用Spearman 相关系数来度量相关性。也可以与ordinal categorical variables一起使用。可以通过运行 scipy.stats.spearmanr(X,Y)来获得Spearman系数得分。
这听起来可能很复杂特别是对于高维数据集。在这种情况下,最好在矩阵中可视化相关关系。下面是如何使用panda实现这一点,我使用的是Porto Seguro的Kaggle安全驾驶预测数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
train = read_csv("./train.csv")
def correlation_heatmap(train):
correlations = train.corr()
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(correlations, vmax=1.0, center=0, fmt='.2f',
square=True, linewidths=.5, annot=True, cbar_kws={"shrink": .70})
plt.show();
correlation_heatmap(train)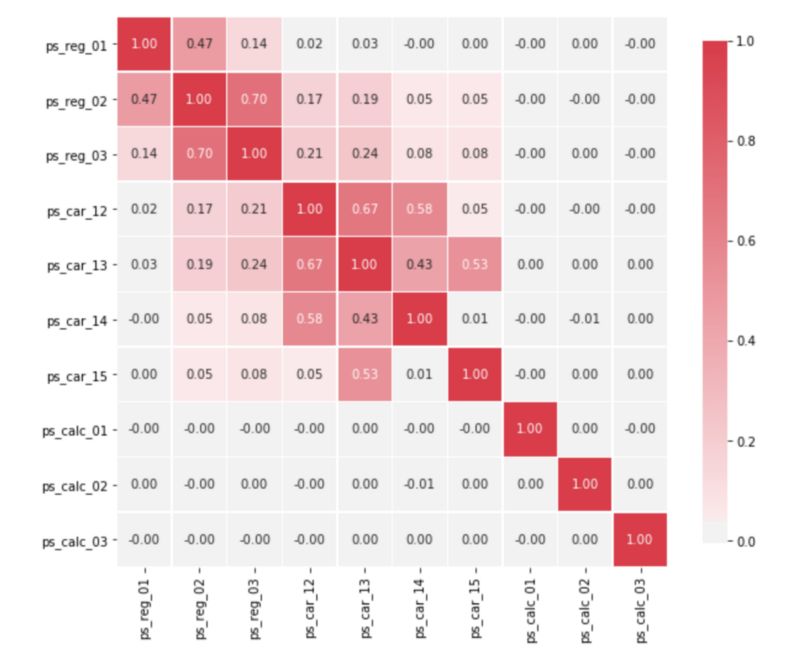
从上面的矩阵中可以看出,psreg03和psreg02变量之间以及pscar12和pscar13之间具有很高的相关性。
还有一种很流行的方法叫做Kendall’s Tau系数,它也是基于可变等级的,但与Spearman系数不同,它没有考虑等级之间的差异。由于本文的重点是Pearson和Spearman的相关性,所以Kendall方法不在本文的研究范围之内。
误解(鹳会接生孩子吗?):
相关性经常被解释为因果关系,这是一个很大的误解。变量之间的相关性并不表示因果关系。任何高度相关的变量都应该仔细检查和考虑。这是一篇(幽默的)德语文章,它使用相关性来证明婴儿是由鹳来接生的理论。研究表明,城市周边鹳类数量的增加与城市医院外接生数量的增加之间存在显著的相关性。
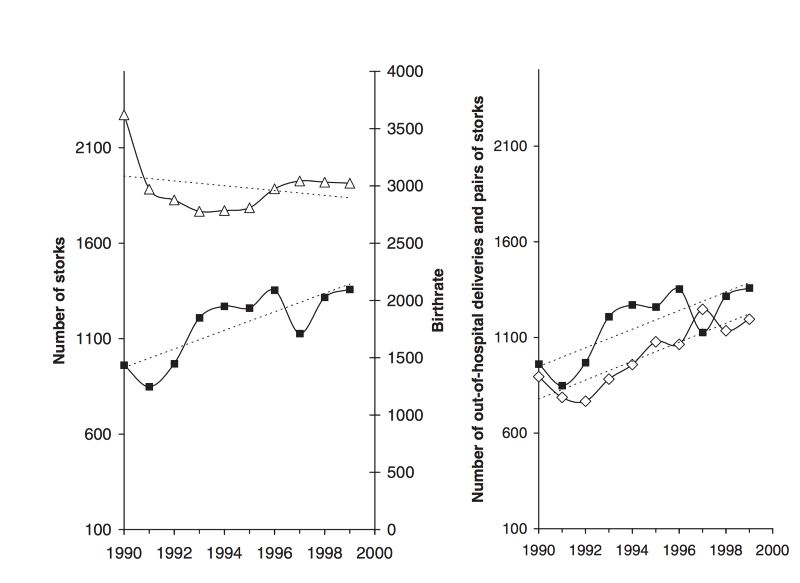
左边的图表显示鹳的数量增加(粗体黑线),医院分娩的数量减少。另一方面,右边的图表显示,医院外分娩的数量(白色方块标记)遵循鹳数量增加的模式。虽然这项研究并不是为了科学地证明(婴儿鹳理论),但它表明,通过高相关性,一种关系可能看起来是因果关系。这可能是由于一些未观察到的变量。例如,人口增长可以是另一个因果变量。
总之:相关性在许多应用中都非常有用,尤其是在进行回归分析时。然而,它不应与因果关系混在一起,并以任何方式被误解。你还是应该始终检查数据集中不同变量之间的相关性,并在探索和分析过程中收集一些见解
 —
END—
—
END—
英文原文:https://towardsdatascience.com/why-feature-correlation-matters-a-lot-847e8ba439c4

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 3550
3550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









