






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Rahul Agarwal
编译:ronghuaiyang
采样是非常常用的技术,特别是在准备数据集的时候,这几个采样方法是数据科学家必须要会的。
数据科学是对算法的研究。
我每天都要处理许多算法,所以我想列出一些最常见和最常用的算法,它们将在这个新的DS算法系列中使用。
这篇文章是关于在处理数据时可以使用的一些最常见的采用技术
简单随机采样
假设你想从一个总体中选择一个子集,其中每个子集的成员被选中的概率相等。
下面我们从数据集中选择100个样本点。
sample_df = df.sample(100)分层采样

假设我们需要估计每个候选人在选举中的平均票数。假设这个国家有3个城镇:
A镇有100万工人,
B镇有200万工人
C镇有300万退休人员。
我们可以选择在整个人口中得到一个60的随机样本,但也有可能这个随机样本在这些城镇中并不平衡因此会产生偏差从而导致估计上的显著误差。
相反,如果我们选择从A镇、B镇和C镇分别随机抽取10个、20个和30个样本,那么对于同样大小的样本,我们可以产生更小的估计误差。
你可以很容易地用Python做类似的事情:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25)蓄水池采样

我喜欢这个问题陈述:
假设你有一个很大且长度未知的物品流,我们只能迭代一次。
创建一个算法,从这个流中随机选择一个物品,这样每个物品被选中的可能性都是相等的。
我们怎么做呢?
假设我们要从一个无限的流中抽取5个物体,这样每个元素被选中的概率都相等。
import random
def generator(max):
number = 1
while number < max:
number += 1
yield number
# Create as stream generator
stream = generator(10000)
# Doing Reservoir Sampling from the stream
k=5
reservoir = []
for i, element in enumerate(stream):
if i+1<= k:
reservoir.append(element)
else:
probability = k/(i+1)
if random.random() < probability:
# Select item in stream and remove one of the k items already selected
reservoir[random.choice(range(0,k))] = element
print(reservoir)
------------------------------------
[1369, 4108, 9986, 828, 5589]从数学上可以证明,在样本中,每个元素从流中被选中的概率是相同的。
怎么做到的?
当涉及到数学时,考虑一个较小的问题总是有帮助的。
那么,让我们考虑一个只有3个物品的流,我们必须保留其中的2个。
我们看到第一项,我们把它放在列表中因为我们的蓄水池有空间。我们看到第二项,我们把它放在列表中,因为我们的蓄水池有空间。
我们看到第三项。这就是事情变得有趣的地方。我们选择第三项放到列表中的概率是2/3。
现在让我们看看第一个项目被选中的概率:
移除第一项的概率是3号元素被选上的概率乘以1号元素被随机选上作为替换候选的概率。这个概率是:
2/3*1/2 = 1/3因此,选1的概率为:
1–1/3 = 2/3我们可以对第二个元素有完全相同的参数我们可以对很多元素进行扩展。
因此,每个项目都有相同的概率被选中: 2/3或一般来说 k/n
随机欠采样和过采样
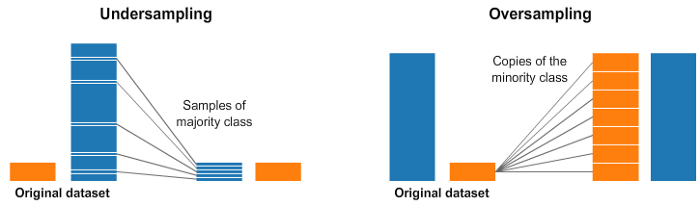
我们经常遇到不平衡的数据集。
一种广泛采用的处理高度不平衡数据集的技术称为重采样。它包括从多数类中删除样本(欠采样)和/或从少数类中添加更多示例(过采样)。
让我们首先创建一些不平衡数据的例子。
from sklearn.datasets import make_classification
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10
)
X = pd.DataFrame(X)
X['target'] = y我们现在可以做随机过采样和欠采样:
num_0 = len(X[X['target']==0])
num_1 = len(X[X['target']==1])
print(num_0,num_1)
# random undersample
undersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ])
print(len(undersampled_data))
# random oversample
oversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ])
print(len(oversampled_data))
------------------------------------------------------------
OUTPUT:
90 10
20
180使用imbalanced-learn来实现欠采样和过采样
imblearn是一个Python包,用于解决数据集不平衡的问题。
它提供了多种方法来进行欠采样和过采样。
a. 使用Tomek Links理解欠采样:
它提供的其中一种方法称为Tomek Links。Tomek Links是靠的很近的一对相反类别的样本对。
在该算法中,我们最终删除了Tomek Links中的多数元素,这为分类器提供了更好的决策边界。
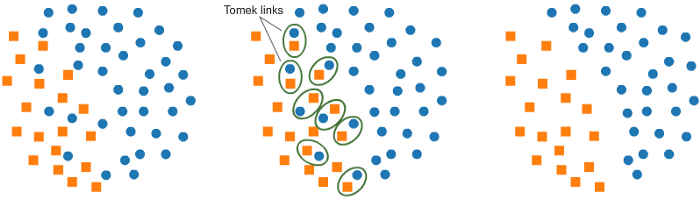
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)b. 使用SMOTE来实现过采样:
在SMOTE中,我们在已经存在的元素附近为少数类合成新的样本。
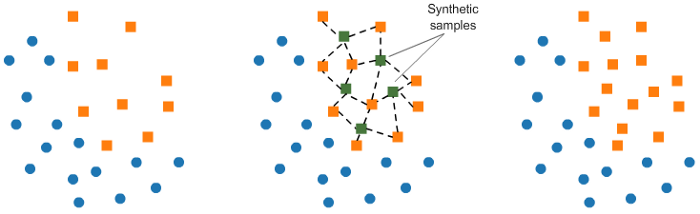
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_sample(X, y)在imblearn包中还有许多其他方法,可以用于欠采样(Cluster Centroids, NearMiss等)和过采样(ADASYN和bSMOTE)。
总结
算法是数据科学的命脉。
采样是数据科学中的一个重要话题,我们并没有过多地讨论它
一个好的采样策略有时可以将整个项目向前推进。一个糟糕的采样策略可能会给我们不正确的结果。因此,在选择抽样策略时应该谨慎。
 —
END—
—
END—
英文原文:https://towardsdatascience.com/the-5-sampling-algorithms-every-data-scientist-need-to-know-43c7bc11d17c

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









