







源码下载:基于余弦相似度的代码查重工具
这一题由于有相关文档故跟着他做还是相较容易一点点(但是英文文档真的读的难受)
首先在做这题之前我们需要了解这题查重所用的方法,这里用的是余弦相似度cosine similarity这一方法进行的比较,两个文件的余弦相似度在一定程度上反映了两个文件的重复程度,余弦相似度的公式这里也给出来了
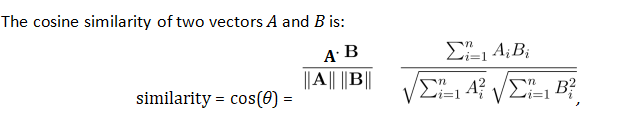
简单来说上面的A,B便是两文件相同单词各自的出现次数
下面的A , B便是两文件所有单词各自的出现次数
知道了算法我们来看题目:
-
Problem 1: A CodeFile class
Write a CodeFile class with:
• A public constructor that takes a URL string such as “20171001234/lab1/turtle/ TurtleSoup.java.java”.
• An instance method that takes a second code files and returns the cosine similarity, calculated using the formula above.
• A toString method that overrides Object.toString and returns a short string that identifies the URL represented by the CodeFile.
Some hints:
• Use the Scanner class to process a code file a word at a time, to build a frequency table for words in the CodeFile. You can construct a Scanner from a URL string:
Scanner sc = new Scanner(new URL(urlString));
Use the Scanner’s default tokenization, and don’t bother cleaning up the input. This will keep your program simple, and cosine similarity is tolerant of noisy data. For this assignment, do not catch the exceptions thrown by the URL; just declare your constructor or methods to propagate them outward.
• Use double-precision floating point arithmetic to compute the numerator and denominator for cosine similarity even though they are integers; integer arithmetic could overflow, yielding wildly incorrect results.
• As an optional optimization, a CodeFile can cache the sum of the squares of the frequencies, which will speed up the computation of cosine similarities.
说人话就是他要我们写一个CodeFile 类,使用Scanner 实现文件的读取并分单词,我写的代码如下:
public static Map<String,Integer> ReadFile(String path) throws FileNotFoundException
{
Map<String,Integer> map=new HashedMap();
Scanner sc = new Scanner(new File(path));
while(sc.hasNext())
{
String str=sc.nextLine();
String []chars=str.split("[ . ,]");//这里是考虑到单词的分割可能会出现前面有. 有, 有空格的情况,故进行了如 此分割
for(String ch:chars)
{
if(isCharacter(ch.toLowerCase()))
{
if(map.containsKey(ch.toLowerCase()))
{
map.put(ch.toLowerCase(),map.get(ch.toLowerCase())+1);
}
else
{
map.put(ch.toLowerCase(),1);
}
}
}
}
return map;
}
public static boolean isCharacter(String str)//这里我们引入一个isCharacter功能使用正则表达式来判断是否是单词
{
if (null == str || str.trim().equals("")) {
return false;
}
String regex = "^[a-z]+$";
return str.matches(regex);
}
然后我们撰写一个CompareFile类用来实现余弦的计算过程与比较
public class CompareFile
{
public static double CompareF(String path1,String path2) throws FileNotFoundException {
CodeFile cf1=new CodeFile();
CodeFile cf2=new CodeFile();
Map<String,Integer> map1=cf1.ReadFile(path1);
Map<String,Integer> map2=cf2.ReadFile(path2);
double molecule=0;
double Denominator=0;
double Denominator1=0;
double Denominator2=0;
int i=0;
for(Map.Entry<String, Integer> entry1 : map1.entrySet())
{
int j=0;
for(Map.Entry<String, Integer> entry2 : map2.entrySet())
{
if(entry1.getKey().equals(entry2.getKey())&&i==j)
{
molecule+= entry1.getValue()*entry2.getValue()*2;
}
else if(entry1.getKey().equals(entry2.getKey()))
{
molecule+= entry1.getValue()*entry2.getValue();
}
j++;
}
i++;
}
molecule=molecule/2;
for(Map.Entry<String, Integer> entry1 : map1.entrySet())
{
Denominator1+=entry1.getValue()*entry1.getValue();
}
for(Map.Entry<String, Integer> entry2 : map2.entrySet())
{
Denominator2+=entry2.getValue()*entry2.getValue();
}
Denominator=sqrt(Denominator1*Denominator2);
return molecule/Denominator;
}
public static double CompareTwo(String path1,String path2) throws FileNotFoundException {
double result=CompareF(path1,path2);
return result;
}
需要注意这里的一些细节操作,我最开始结果一直不对就是忽略了这一点,因为我用的双for循环会遍历两次,故结果应该是两倍,这一点我考虑到了所以在分子处除了2,但是我没考虑到的是出现两个循环访问的都是同一元素,例如文件1:let2 it1,文件2:let2,it3,or1;这种情况下虽然在i,j不相同时确实将元素正反遍历了两遍,但在i,j相同时却只遍历了一遍,故直接将结果除2还不够,还需要将i,j相同时的临时结果×2加到最终结果
这里我们使用题目中所说的let it be与if it is to be it is up to me to do it进行测试:
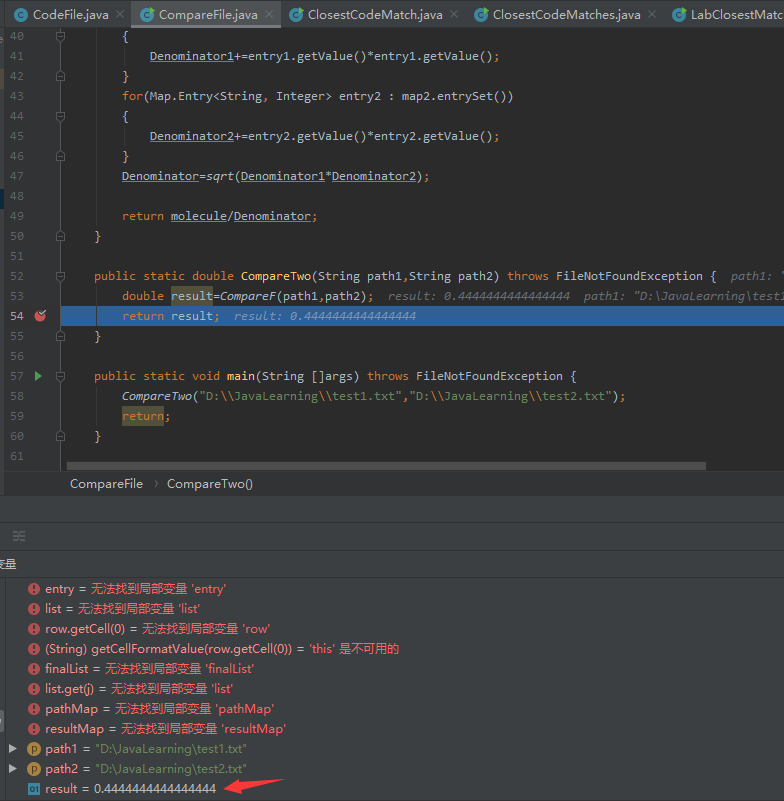
这里我们看到结果是0.444符合预期
-
Problem2 The closest match in a set of code files
Write a program called ClosestCodeMatch that takes an arbitrary number of URLs on the command line and prints the two URLs for the most similar pair of code files. Do not bother handling any exceptions thrown by the CodeFile class; just declare your main method to propagate them outward. For n CodeFiles your program should perform n(n − 1)**/**2 calls to the cosine similarity method. In other words, each code file should be compared to every other code file exactly once. Cosine similarity is (theoretically) symmetric, so there is no need to calculate docX’s similarity to docY if you’ve already computed docY’s similarity to docX. We say “theoretically” because, on a real computer, there is imprecision in floating point arithmetic.
Test your program by running it with approximately six code files consisting of two files on closely related project and four code files on unrelated projects (e.g., lab1 and lab2 projects). See if the program can find the two related source code files.
人话讲就是写一个ClosestCodeMatch 类用于找一组代码文件中最接近的匹配项,我的代码如下:
public class ClosestCodeMatch { public static String CompareAll(String[]paths) throws FileNotFoundException { Map<String,Double> m=new HashedMap(); int i=0; double max=0; String resultPath=""; for(String path1:paths) { int j=0; for(String path2:paths) { if(i==j) { j++; continue; } CompareFile file=new CompareFile(); double tmp=file.CompareTwo(path1,path2); if(tmp>max) { max=tmp; } String path=path1+" "+path2; m.put(path,tmp); j++; } i++; } for(Map.Entry<String, Double> entry1 : m.entrySet()) { if(entry1.getValue().equals(max)) { resultPath=entry1.getKey(); } } return resultPath; }这个没什么好讲的,就是利用之前的功能罢了,只不过需要注意文件的读写
-
Problem3:The closest match to each CodeFile in a set
Write a program called ClosestCodeMatches that takes an arbitrary number of URLs on the command line and finds the closest matching code file for each of the command line arguments. With n command line arguments the program should print n pairs of URLs: one for each URL and it’s closest match, with each pair on its own line. This program should perform the same n(n − 1)**/**2 calls to the cosine similarity method as in problem 2, but save the results in an appropriate data structure so that the closest match for each URL can be determined. As in problem 2, don’t bother handling exceptions.
Test your program by running it with approximately ten source codes drawn from five different projects (two source code files per project). See how many of the pairs your program correctly matches.
人话讲就是编写一个名为ClosestCodeMatches的类找出每个代码文件最相似接近的文件,我的代码如下:
public class ClosestCodeMatches { public static Vector<String> CompareEach(String[]paths) throws FileNotFoundException { int i=0; Vector<String>vet = new Vector<String>(); for(String path1:paths) { int j=0; double max=0; Map<String,Double> m=new HashedMap(); for(String path2:paths) { if(i==j) { j++; continue; } CompareFile file=new CompareFile(); double tmp=file.CompareTwo(path1,path2); if(tmp>max) { max=tmp; String path=path1+" "+path2; m.put(path,tmp); } j++; } for(Map.Entry<String, Double> entry1 : m.entrySet()) { if(entry1.getValue().equals(max)) { String resultPath=entry1.getKey(); vet.add(resultPath); } } i++; } return vet; }其实这个和上一个很相似,只是将后面的遍历map操作放到for循环中了,因为每个元素都需要找到其最接近的文件
-
Problem 4:LabClosestMatches
*假设在* *codes/lab1/********目录下存在以下结构的文件组织:*
├─Java课内实习-201710001234-xxx-实习1
│ ├─Java课内实习-20171000123-xxx-实习1
│ │ └─lab1_code
│ │ ├─rules
│ │ └─turtle
│ └─lab1_code
│ ├─rules
│ └─turtle
├─Java课内实习-20171001235-xxx-实习一
│ └─lab1
│ └─lab1_code
│ └─lab1_code
│ ├─bin
│ │ ├─rules
│ │ └─turtle
│ ├─rules
│ └─turtle
├─Java课内实习-20171001236-xxxx-实习一
│ ├─rules
│ └─turtle
└─Java课内实习20171001237-xxxx-实习一
└─Java课内实习20171001237-xxx-实习一
└─Java课内实习20171001237-xxxx-实习一
└─lab1_code
├─123
├─rules
│ └─bin
└─turtle
└─bin
Write a program called *LabClosestMatches,* 实现如下方法:
/**
* 用于评价各相关目录下,指定文件的相似性。
* Similarity 子目录1 子目录2
* 100% Java课内实习-201710001234-xxx-实习1 Java课内实习-201710001235-xxx-实习1
* 89% Java课内实习-201710001234-xxx-实习1 Java课内实习-201710001236-xxx-实习1
* …
* *@param* path 作业文件所在的目录,比如这里是:codes/lab1
* *@param* fileNameMatches:用来过滤进行比较的文件名的文件名或者正则表达式.
* 如 “DrawableTurtle.java”,".java","turtle/.java"
* 如果一个子目录下有多个符合条件的文件,将多个文件合并成一个文件。
*
* *@param* topRate:取值范围从[0,100],输出控制的阈值
* 从高往低输出高于topRate%相似列表,如
* *@param* removeComments:是否移除注释内容
* */
*public* *static* *void* closestCodes(String path, String fileNameMatches,****double**** topRate,****boolean**** removeComments)
这个题主要重在文件的读写操作与对计算机文件目录的读取操作,经过一定的学习我查看了File包的功能介绍,然后利用File的一些判断函数与.list()函数实现了这一问:
public class LabClosestMatches { public static Map<String, List<String>>pathMap; public static Map<Double,String>resultMap; public static void closestCodes(String path, String fileNameMatches) throws FileNotFoundException { resultMap=new HashedMap(); pathMap=new HashedMap(); File file=new File(path); String[] names=file.list(); for(String name:names) { String pname=path+"\\"+name; findTargetFile(name,pname,fileNameMatches); } int count=0; for(Map.Entry<String, List<String>> entry : pathMap.entrySet())//合并某位同学的所有java文件 { String p="D:\\test\\"+entry.getKey()+".txt"; List<String>list=entry.getValue(); int s=list.size(); String[]f=new String[s]; for(String item:list) { f[count]=item; count++; } mergeFiles(f,p); count=0; } int i=0; String head="D:\\test\\"; File f=new File(head); String[]paths=f.list(); for(String path1:paths) { int j=0; for(String path2:paths) { if(i==j) { j++; continue; } CompareFile tempfile=new CompareFile(); double tmp=tempfile.CompareTwo(head+path1,head+path2); String finalpath=path1+" "+path2; resultMap.put(tmp,finalpath); j++; } i++; } return; } public static void findTargetFile(String projectName,String pname,String fileNameMatches) { File file=new File(pname); while(!file.isFile()) { String[] names=file.list(); for(String name:names) { if(pname.indexOf("~")==-1) { String tname=pname+"\\"+name; findTargetFile(projectName,tname,fileNameMatches); } } return; } if(pname.indexOf(fileNameMatches)!=-1) { if(pathMap.containsKey(projectName)) { List<String> list=pathMap.get(projectName); list.add(pname); pathMap.put(projectName,list); } else { List<String> list=new LinkedList<>(); list.add(pname); pathMap.put(projectName,list); } } else { return; } } public static boolean mergeFiles(String[] fpaths, String resultPath) { if (fpaths == null || fpaths.length < 1 || TextUtils.isEmpty(resultPath)) { return false; } if (fpaths.length == 1) { return new File(fpaths[0]).renameTo(new File(resultPath)); } File[] files = new File[fpaths.length]; for (int i = 0; i < fpaths.length; i ++) { files[i] = new File(fpaths[i]); if (TextUtils.isEmpty(fpaths[i]) || !files[i].exists() || !files[i].isFile()) { return false; } } File resultFile = new File(resultPath); try { FileChannel resultFileChannel = new FileOutputStream(resultFile, true).getChannel(); for (int i = 0; i < fpaths.length; i ++) { FileChannel blk = new FileInputStream(files[i]).getChannel(); resultFileChannel.transferFrom(blk, resultFileChannel.size(), blk.size()); blk.close(); } resultFileChannel.close(); } catch (FileNotFoundException e) { e.printStackTrace(); return false; } catch (IOException e) { e.printStackTrace(); return false; } return true; } public static void main(String []args) throws FileNotFoundException { String path="D:\\JavaLearning\\lab3-2020\\lab1-codes-fortest"; String fileNameMatches=".java"; closestCodes(path,fileNameMatches); String fileName="D:\\result.txt";//最终输出路径 try { RandomAccessFile randomFile = new RandomAccessFile(fileName, "rw"); String head="相似度 子目录1 子目录2\r\n"; randomFile.write(head.getBytes()); // 文件长度,字节数 for(Map.Entry<Double, String> entry : resultMap.entrySet()) { String content=entry.getKey()+" "+entry.getValue(); long fileLength = randomFile.length(); randomFile.seek(fileLength); randomFile.write(content.getBytes()); randomFile.write(" ".getBytes()); randomFile.write("\r\n".getBytes()); } randomFile.close(); } catch (IOException e) { e.printStackTrace(); } return; } }需要注意的是我这里的函数参数并未引用后两个,这里我的思路是先遍历给定目录下一级目录获得各个同学的名字文件,这个作为每个同学的标识符,然后对每一个名字文件进行深度搜索,搜索处所有带给定参数的值的文件并将其路径存入一个map的value中,value为list类型,map的key就是名字文件的名字。然后利用一个合并函数将所有对应路径的文件内容合并到一个文件之中,每个同学都有一个其合并后的文件,最终对合并后的文件执行余弦相似判断,然后进行一系列文件操作即可
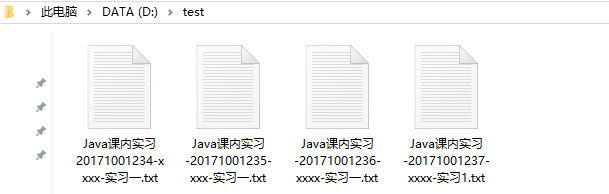
输出的合并文件:
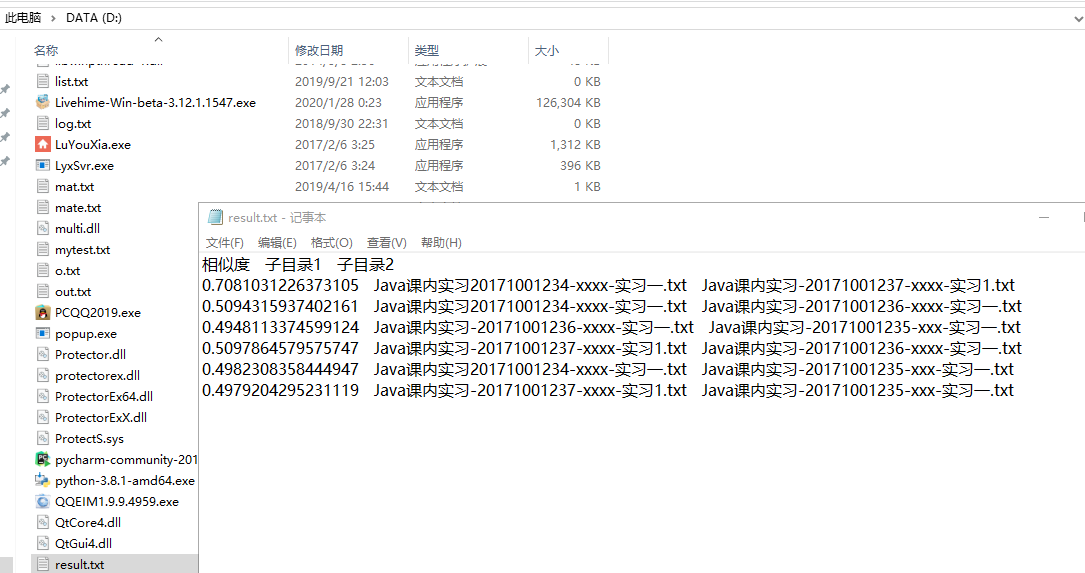
最终结果:

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









