






1 前言
接着上次的tf2+cnn+中文文本分类优化系列(1),本次进行优化:使用多个卷积核进行特征抽取。之前是使用filter_size=2进行2-gram特征的识别,本次使用filter_size=[3,4,5]三个不同的卷积核抽取三个不同的gram特征,这样就能通过卷积获取更多的词特征。其实,本次主要看cnn在做中文文本分类中single kernel与multi kernel的对比。
2 前期处理
数据集仍是复旦大学开源的文本数据集,label种类为20。所用的包如下:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.callbacks import ReduceLROnPlateau
import numpy as np
import collections
import matplotlib.pyplot as plt
import codecs
import re
import os
一些参数设定如下:
class TextConfig():
embedding_size=100 #词的维度
vocab_size=6000 #词表的大小
seq_length=300 #文本长度
num_classes=20 #类别数量
num_filters=128 #卷积核数量
filter_sizes=[3,4,5] #多个卷积核大小
keep_prob=0.5 #dropout
lr= 1e-3 #学习率
is_training=True
num_epochs=10 #epochs
batch_size=64 #batch_size
train_dir=r'E:\data\train.txt' #train data
test_dir=r'E:\data\test.txt' #test data
vocab_dir=r'E:\data\vocab.txt' #vocabulary
接着构建词表,并将文本token化:
def read_file(file_dir):
"""
读入数据文件,将每条数据的文本和label存入各自列表中
"""
re_han = re.compile(u"([\u4E00-\u9FD5a-zA-Z]+)") #去掉标点符号和数字类型的字符
with codecs.open(file_dir,'r',encoding='utf-8') as f:
for line in f:
label,text=line.split('\t')
content=[]
for w in text:
if re_han.match(w):
content.append(w)
yield content,label
def build_vocab(file_dirs,vocab_dir,vocab_size=6000):
"""
利用训练集和测试集的数据生成字级的词表
"""
all_data = []
for filename in file_dirs:
for content,_ in read_file(filename):
all_data.extend(content)
counter=collections.Counter(all_data)
count_pairs=counter.most_common(vocab_size-1)
words,_=list(zip(*count_pairs))
words=['<PAD>']+list(words)
with codecs.open(vocab_dir,'w',encoding='utf-8') as f:
f.write('\n'.join(words)+'\n')
def convert_examples_to_tokens(input_dir,vocab_dir,seq_length):
"""
将文本按字级别进行token化,按后截断的方式进行padding;
"""
words=codecs.open(vocab_dir,'r',encoding='utf-8').read().strip().split('\n')
word_to_id=dict(zip(words,range(len(words))))
categories = ['Art', 'Literature', 'Education', 'Philosophy', 'History', 'Space', 'Energy', 'Electronics',
'Communication', 'Computer','Mine','Transport','Enviornment','Agriculture','Economy',
'Law','Medical','Military','Politics','Sports']
cat_to_id=dict(zip(categories,range(len(categories))))
input_ids,label_ids=[],[]
for content,label in read_file(input_dir):
input_ids.append([word_to_id[x] if x in word_to_id else 0 for x in content ])
label_ids.append(cat_to_id[label])
input_ids =tf.keras.preprocessing.sequence.pad_sequences(input_ids, value=0,padding='post', maxlen=seq_length)
label_ids=np.array(label_ids)
return (input_ids,label_ids)
该部分跟之前的基本是一样的,只是参数中filter_sizes变成一个列表
3 模型构建
不同单个卷积核,在使用多个卷积核时,要进行遍历,然后将每次卷积+池化的结构进行拼接。
def cnn_model(cfg):
"""
定义一个实现多个卷积核的layer,然后进行Flatten,dropout,softmax层;
"""
def convolution():
inn = layers.Input(shape=(cfg.seq_length, cfg.embedding_size, 1))
cnns = []
for size in cfg.filter_sizes:
conv = layers.Conv2D(filters=cfg.num_filters, kernel_size=(size, cfg.embedding_size),
strides=1, padding='valid', activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001))(inn)
pool = layers.MaxPool2D(pool_size=(cfg.seq_length - size + 1, 1), padding='valid')(conv)
pool = layers.BatchNormalization()(pool)
cnns.append(pool)
outt = layers.concatenate(cnns)
model = tf.keras.Model(inputs=inn, outputs=outt)
return model
model = tf.keras.Sequential([
layers.Embedding(input_dim=cfg.vocab_size, output_dim=cfg.embedding_size,
input_length=cfg.seq_length),
layers.Reshape((cfg.seq_length, cfg.embedding_size, 1)),
convolution(),
layers.Flatten(),
layers.Dropout(cfg.keep_prob),
layers.Dense(cfg.num_classes, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(cfg.lr),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print(model.summary())
return model
其中 function convolution就是定义的一个多个卷积核形成的layer,在卷积中使用了2维卷积,所以在embedding后增加了一个维度:layers.Reshape((cfg.seq_length, cfg.embedding_size, 1))
4 训练
在训练中,本次我们调用了ReduceLROnPlateau定义一个学习率衰减策略:在val_loss超过2个epoch没减少,则学习率按lr=lr*0.6进行下调。
if __name__ == "__main__":
cfg=TextConfig()
model=cnn_model(cfg)
if not os.path.exists(cfg.vocab_dir):
build_vocab(cfg.train_dir, cfg.vocab_dir, cfg.vocab_size)
#载入训练数据,并进行样本打乱;
train_x,train_y=convert_examples_to_tokens(cfg.train_dir,cfg.vocab_dir,cfg.seq_length)
indices=np.random.permutation(np.arange(len(train_x)))
train_x=train_x[indices]
train_y=train_y[indices]
#定义学习率衰减策略
reduce_lr = ReduceLROnPlateau(monitor='val_loss',factor=0.6, patience=2, min_lr=0.0001)
history=model.fit(train_x,train_y,epochs=cfg.num_epochs,batch_size=cfg.batch_size,
verbose=1,validation_split=0.1, callbacks=[reduce_lr])
5 结果对比
- 在测试集上损失和准确率
| 模型 | test_loss | test_accuracy |
|---|---|---|
| single kernel(之前) | 0.573 | 0.833 |
| multi kernel(本次) | 0.505 | 0.888 |
可以看出,本次多个卷积核有5.5%效果的提升,还是很明显的,也证实了多个卷积核能抽取更多相关的N-gram特征,进而影响识别效果。
-
各个label的f1-score 指标对比
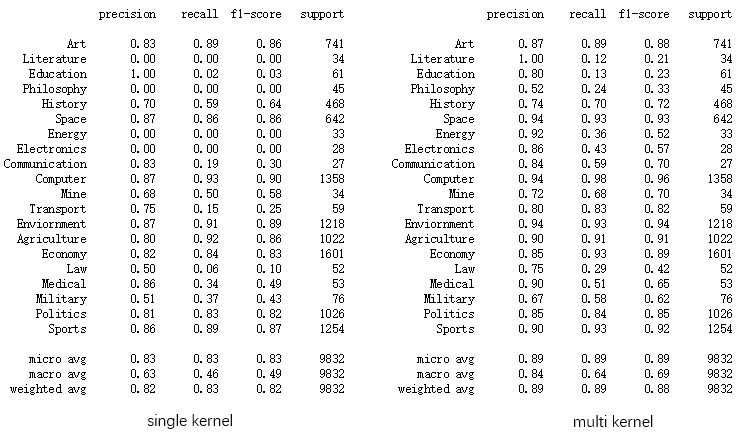
从上图可以看出,在多个卷积核识别下,“Literature”label从原先的0提升到0.21,其他指标也得到一定的提升。 -
训练过程对比
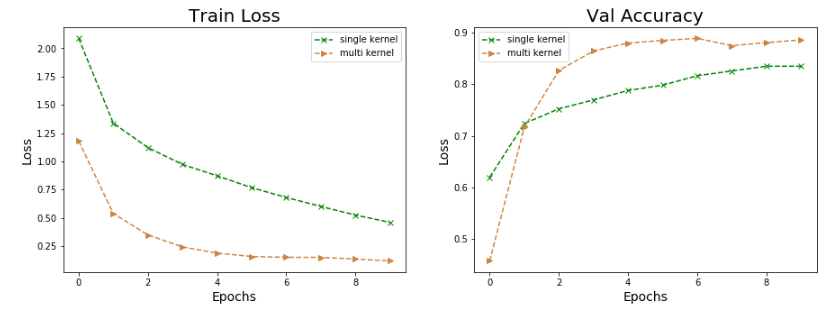
从训练的损失和验证集的准确率来看,multi kernel都是优于single kernel的。
6 结语
通过本次的实验可以得出,在使用cnn做text classification任务,多个卷积核已是标配。至于用多少个卷积核,一般是取3个,具体也看数据场景,但更多的话会增大模型复杂度而对效果提升不大。在本次实验下,仍有优化空间,下次从词的角度进行优化。
更多文章可关注笔者公众号:自然语言处理算法与实践
















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











