







在云栖大会上,听到了小蜜的老师分享的。关于意图识别,提到了match的方法,用的label embedding,不太了解,整理一下

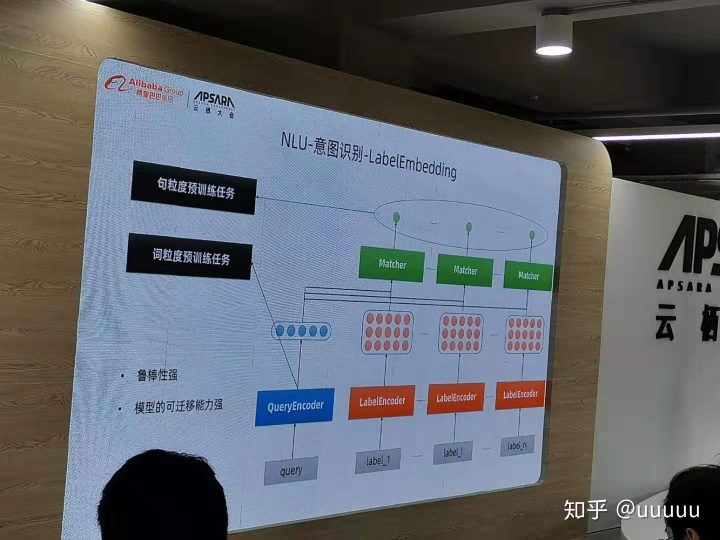
这里的label embedding, 指的是,将一个label下的样本归纳成一个向量,新的预测样本,encode之后,与这个向量去计算一个score,最后得到该样本的predict label。
label embedding相关论文
- Joint Embedding of Words and Labels for Text Classification
1.1 contributions:
- 对于后面的分类任务提供了更多的信息量。
- 保留了模型的可解释性,尤其是当label description是有意义的
- 设计的attention 机制具有较少的参数。相对于其他复杂的deep attention model.
- sota
- 副产物。在医疗文本上可以突出预测信息的关键词。减少阅读的负担
1.2 Architecture
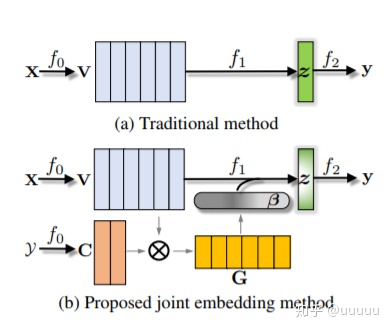
在这篇文章里面,把文本分类分为3个阶段。 f = f0 * f1 * f2
f0对应的是encoder ,text -> embedding
f1 对应的是aggregation , 将matrix feature -> vector feature
f2 对应的是classifier, 映射成label
传统的分类结构上,只有最后一个阶段f2, 才会利用到label information, 见上图a,
最后输出的y, logit的每一个位置的值, 相当于,z * 对应位置的class_embedding得到。
这篇文章的重心在于,传统的aggregation的时候,直接进行pooling或者attention等方式,此处利用label信息学习到label embedding 作为anchor points去影响word embedding,并进行aggregation
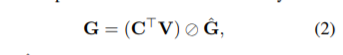
c表示text embedding , v表示 label embedding, 利用cosine similarity来衡量label-word的相关。
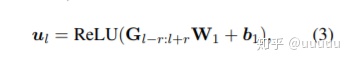
为了更好的获取连续字之间的相对空间信息,引入了非线性, 使用的 卷积+relu。 ul 为每个word和k个label的相似度向量

m的维度与text的长度一致。
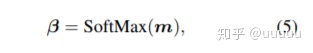
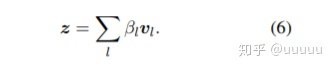
最后aggregation到vector, 映射到num class大小
2.3 results
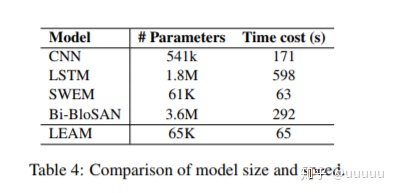
模型比较简单,参数量少
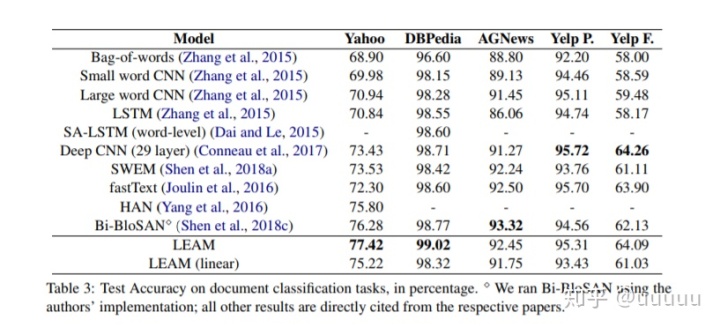
class 较多且 label有明确含义的字表现会比较好
2. Multi-Task Label Embedding for Text Classification
https://www.aclweb.org/anthology/D18-1484www.aclweb.org2.1 contributions:
- 提供了一个将label映射成一个vector, 有效的利用了标签信息
- 方便的应用到新的任务上
- 当训练了几个相关的任务,针对新的task, 不需要训练,直接就可以用就能获得一个比较好的效果
- sota in several datasets
2.2 hot update & cold update & zero update
hot update: 在历史训练的k个task的基础上,finetune
cold update: 在所有的task上重新训练
zero update: 不更新模型。利用历史训练的模型在新task上predict
2.3 Architecture
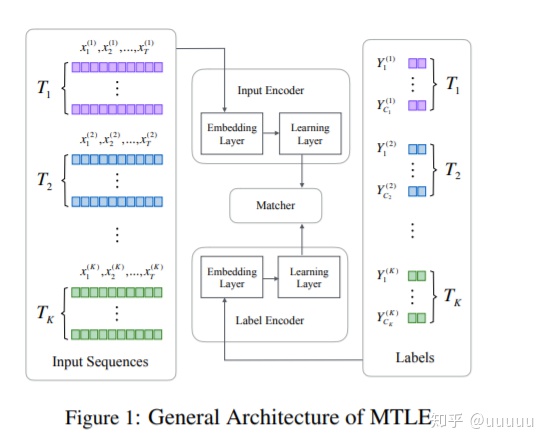
包含3个部分。 input encoder , label encoder, matcher
encoder将文本编码成一个定长的vector
具体结构如下
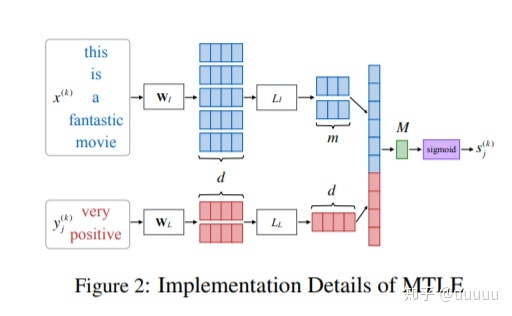
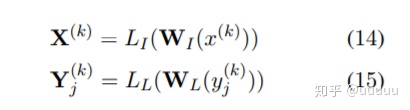
text -> embedding -> bi_lstm -> vector
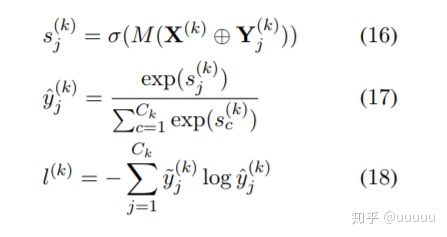
text和label的特征concat之后直接映射到1。
多个task的训练方式,是一个epoch里面随机选择一个task的batch更新参数。
2.4 results
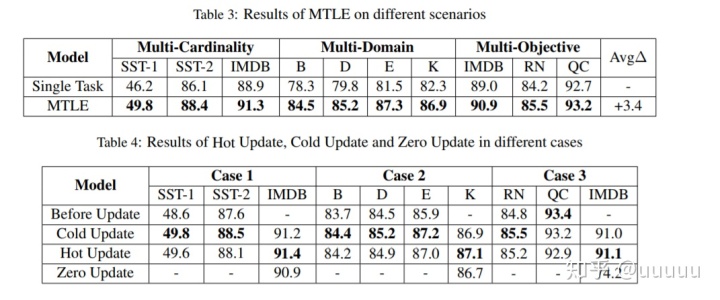
3. Explicit Interaction Model towards Text Classification
https://arxiv.org/pdf/1811.09386.pdfarxiv.org3.1 传统的分类结构,文中成为encoding based methods:
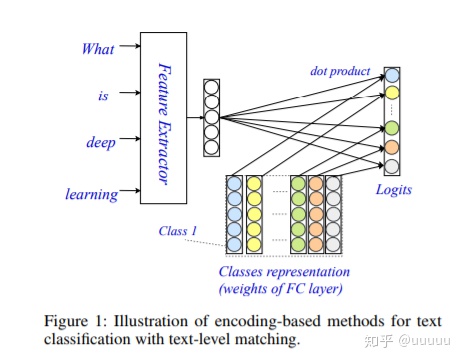
在最后的分类层上。利用文本的表示的vector * class representation 得到对应位置的logit, 这样文本的概率很大概率取决与整体的匹配,而忽略了字级的匹配。
3.2 Architecture
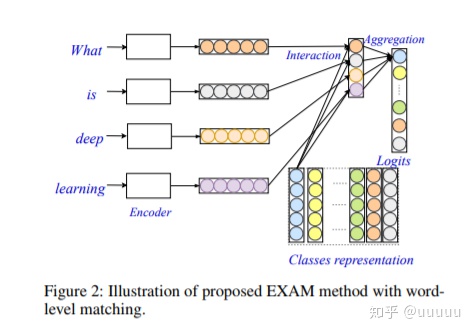
包含3个模块, encoder, 使用 gru/region embedding, interaction模块,计算每个字与每个class的交互,aggregation, 得到最终的分类class

T为label embedding , H 为text的hidden feature.
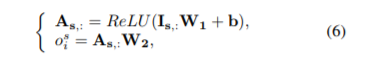
这篇文章的重心在于,text中word 与class之间的交互。
3.3 result
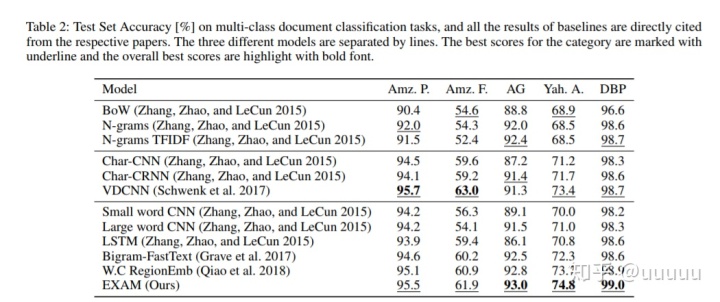
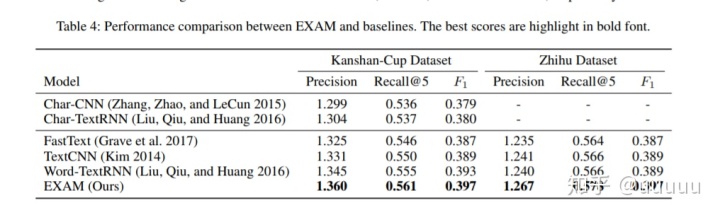
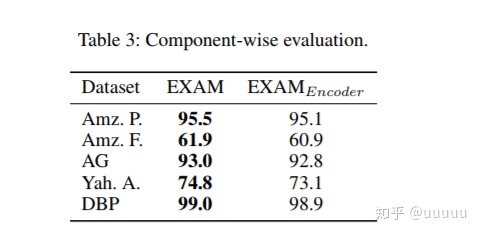
table3中的EXAM encoder是没有word class交互的encoding based model.















 5695
5695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









