






1 前言
今天分享一篇2020年ACL会议一篇paper:Text Classification with Negative Supervision,是关于文本分类的任务。其解决的是当要分类的文本高度相似的时候,分类器识别的效果就会变差。提高分类器在解决这类问题的核心是如何让文本获取更强的具备差异性的文本表征向量。尽管现在基于类似BERT预训练模型已显著提高了文本的表征能力,但作者认为这类表征还不够好。如下图,在识别文本是否在描述病人患感冒病症,在BERT模型下将第一个句子错误识别为正样本。基于此,文中作者提出了一个使用负样例监督的多任务学习框架,提高文本分类的识别效果。 论文下载地址为:https://www.aclweb.org/anthology/2020.acl-main.33.pdf。

2 模型
文中分析认为,现有的encoder方法倾向将相似的文本编码成非常接近的向量,这是一种语义导向的表征方法,当与任务场景中标签的赋值倾向不一样时,分类器就容易识出错。而对高度相似且label不同的文本,好的encoder应该能学到他们之前的差异性表征信息,这样才能让分类器有着更好的表现。
基于上述分析,作者提出一个很简易的模型,模型框架如下图。
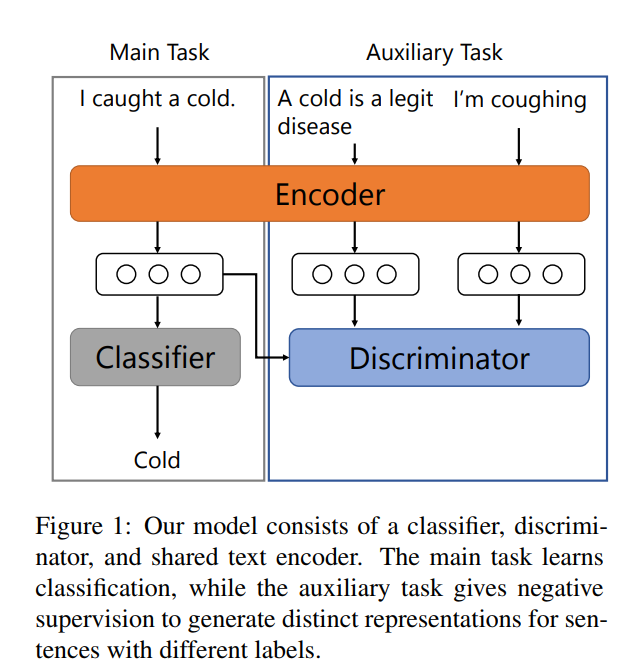
其主要思路:
- 将分类任务作为主任务(Main Task),另外加一个辨别性的学习任务作为辅助任务(Auxiliary Task),形成一个多任务学习框架;
- 主任务与辅助任务共享一个编码层(text encoder);
- 主任务负责分类模型的训练,辅助任务在负样本的监督下,促使text encoder学习出更多相对label的差异性信息。
对应的计算公式如下:
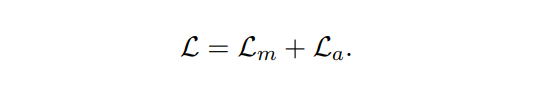
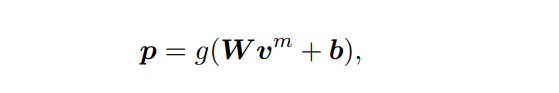
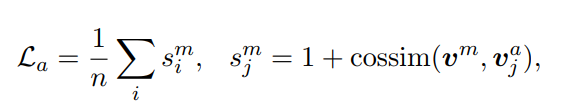
根据上述的公式和文中的介绍,下面梳理下输入和输出;
- 将正常训练样本输入Main Task模型中,通过BERT encoder模型,得到表征的向量为 v m v^m vm,然后接一个softmax层进行分类,用交叉熵作为主任务的损失函数 L m L_m Lm;
- 从同batch中选取 n n n个跟 v m v^m vmlabel不同的样本,作为负样例,进行差异性学习,学习的思路让负样例与样例 v m v^m vm之间的相似度尽可能的小,其表达意思就如Auxiliary Task Loss公式所示。
关于一些疑问:(1) 按模型图中画的,Main Task应该输入所有的样本进行训练,包括“Cold”类型和非“Cold”的类型,而后者作为negative examples输入Auxiliary Task中,而文中说negative examples是与 v m v^m vm样本来自同一个batch,那其实模型图画的逻辑有些问题,至少非“Cold”的类型样本也是Main Task的输入,Main Task是包括Auxiliary Task任务,而图中显示的是并列关系。(2)关于样例 v m v^m vm具体代表什么,文中并没有说清楚,我的理解应该一个batch里一个“Cold”类型样本的表征向量或者是一个batch里所有“Cold”类型的表征向量,这里我更偏向前者。
整体paper提出的思路就是:按正常进行文本分类的时候,在每个batch计算中加一个负样例监督的损失函数,增强正样例与负样例之间的差异性学习。这里的正样例与负样例其实是相对的,拿MNIST数据集来说,如果数字3是正样例,那其他数字就是负样例;如果数字2是正样例,那其他数字,包括数字3都是负样例。所以,在每个batch计算监督损失的时候,有全遍历模式或者负采样的模型。当分类任务是二分类时候,就不用考虑采样问题。
#3 实验
在实验部分,作者选择了3中类型任务:a)单标签与多标签的文本分类;b)句子级别与文档级别的文本分类;c)不同语言的文本分类。下图是总体测试结果。
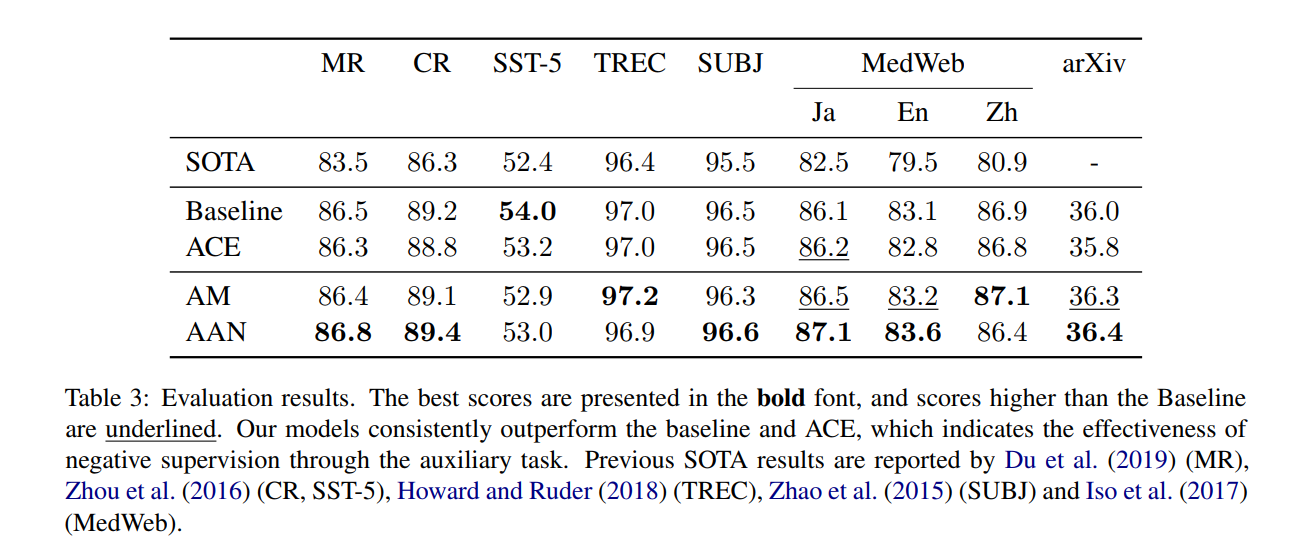
其中前5个数据集都是单标签分类任务,MedWeb和arXiv是多标签分类任务,前者是句子级别,后者是文档级别。MedWeb数据集上有三种不同的语言。AM与AAN是文中提出的模型,可以看出,作者提出的方法除了在SST-5数据集外,识别效果都有明显的提升。
4 结语
这次分享的paper想法很简单,但有时一些简单的想法会有意想不到的效果。其主要思路,就是在正常的文本分类任务过程中,加了一个正样例与负样例之间相似度的损失函数,期望让模型能学到更具有差异性的信息,以提高识别效果,尤其是当文本特别相似的时候。只是文本中的描写将这样的想法表达的比较高级,说是一种在负样例监督下的文本分类。其实正常的分类,也是有负样例监督的~~ 此外,文章存在一些细节问题,当然我们也需抱着大胆假设,小心求证的态度对待这篇paper。因为paper没有开源代码,后面我会在一些数据集上复现验证下该方法,到时候再分享出来~
更多文章可关注:自然语言处理算法与实践















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











