







文章目录
VTM中的数据结构
HM的代码复杂难懂,结构混乱,缺少数据和逻辑封装,Z-order和raster-order换来换去让人头痛不已,代码可读性比较差。同时HM中很多数据结构的设计都是针对其CU尺寸都是正方形而设计的,扩展性也不好。
为了解决HM数据结构复杂、代码可读性差、内存管理负责的问题,VTM使用的数据结构,使用了OO设计理念,对琐碎的计算进行封装,并跟内存管理逻辑,增强代码的可读性。 (移除了Z-index的概念,数据访问的两级参数也移除了(CTU->Z-index)).
OO设计原则:SOLID
- SRP:The Single Responsibility Principle 单一责任原则:接口或类与责任一一对应
- OCP: The Open-closed principle 开放-封闭原则:模块的行为是可扩展的,但是模块自身的代码是不应该被修改的
- LSP:The liskov substitution principle liskov 替换原则:所有引用基类的地方必须能够透明的使用其子类的对象。
- ISP: The Interface segregation principle 接口聚合原则:
- DIP:The dependency inversion principle 依赖转置原则:高层模块不应该依赖底层模块,两者都应该依赖抽象;抽象不应该依赖细节,细节应该依赖抽象
(水平有限,并没有完全理解)
参考:OO Design Principles(OO设计原则): SOLID
ISP:接口聚合原则
定义:所有引用基类的地方必须能透明地使用其自类的对象,只要父类能出现的地方子类就可出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类(封装造成的多态性)。
规范:
- 子类必须完全实现父类的方法,在类中调用其他类时必然要使用父类或者接口,如果子类中不支持父类中的方法,自然就违背了LSP。
- 子类要有自己的特性,这也导致了LSP的单向性,在子类能出现的地方,父类未必能够胜任
- 覆写或实现父类的方法时参数可以被放大
- 子类中方法的参数的前置条件必须与超类中被覆写的方法的前置条件相同或者更宽松
- 因为参数类型不同会导致参数列表不同,那么实际上我们在参数类型不同时实现的时重载而非覆写
- 优点:采用LSP能够增强程序的健壮性,版本升级时,能够保证非常好的兼容性,即使增加子类,原有的子类还可以继续运行。
1. 数据结构概述
| 类 | 描述 |
|---|---|
| Size, Position, Area | 基本二维信息,size+position=area |
| CompArea | 特定分量/通道的二维信息 |
| UnitArea | 多通道信号的二维信息 |
| AreaBuf | 管理线性内存中的一个二维信号的存储结构,包含内存操作方法(copy,fill 等) |
| UnitAreaBuf | 管理线性内存中的多通道二维信号的存储结构,包含内存操作方法(copy,fill 等) |
| PelStorage | 需要分配额外内存的UnitAreaBuf |
| Picture | 包含元数据(slice信息等)以及输入输入数据 |
| CodingUnit, PredictionUnit, TransformUnit | 与功能一一对应,包含相应信息(模式信息,深度信息等) |
| CodingStructure | 管理CU、PU和TU等,链接基本单元与图片帧;包含自定向下进行RD搜索的方法 |
2. 基本数据模型示意图
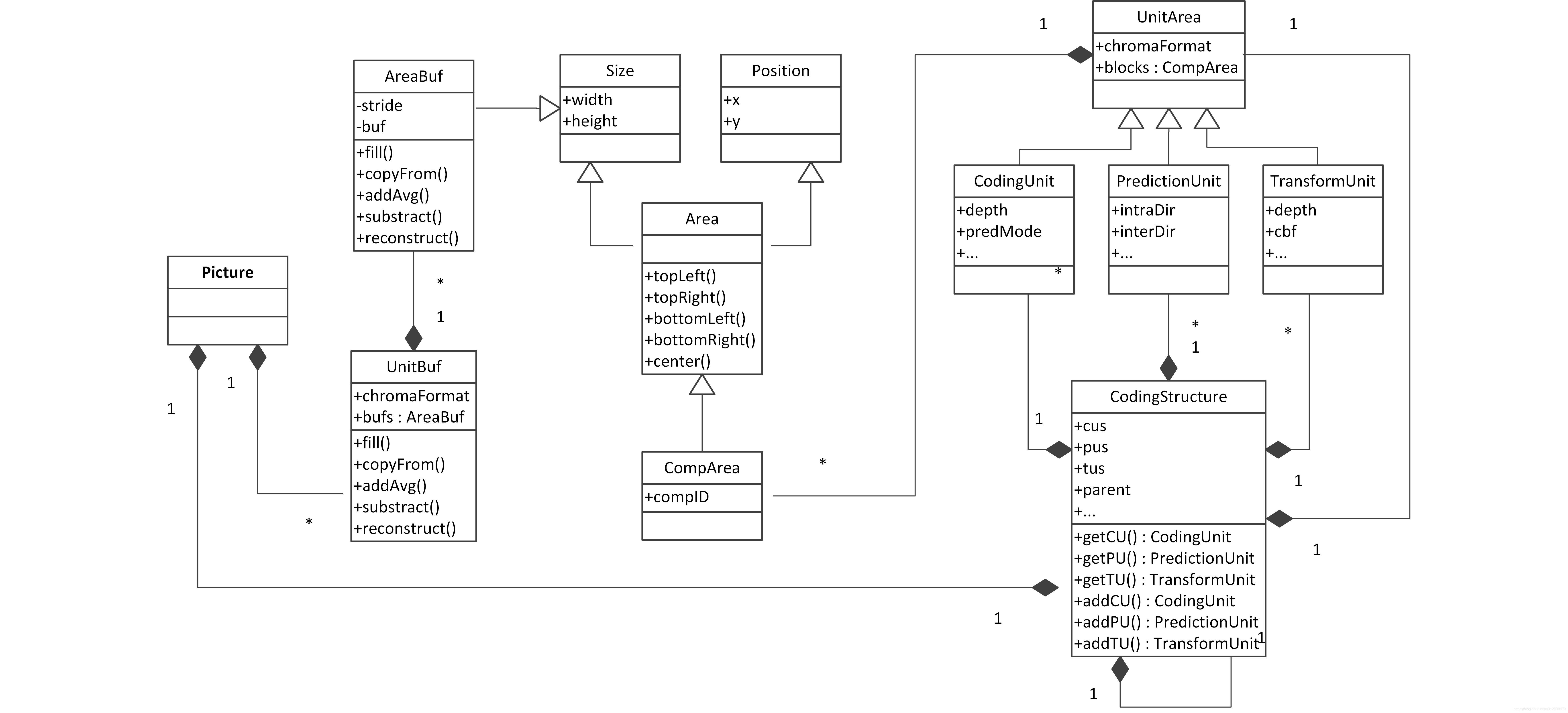
3. CodingStructure 详解
- 包含
CodingUnit,PredictionUnit等对象,链接其与picture的映射关系。 - 替代HM中
TComDataCU类,但是CS并不局限于CTU,全局分配。CS区域大到可以覆盖整个帧,小到一个CU。
– 上层CodingStructure包含了一帧中所有的CodingUnit,PredictionUnit和TransformUnit。
– 下层CodingStructure是一个特定UnitArea的描述。 CodingStructure实例化后,内容为空
– 使用addCU/PU/TU方法创建并映射到特定对象
– 使用getCU/PU/TU获取处于全局绝对位置上的特定对象- 通过
dynamic_cache动态申请资源以提升性能
使用CodingStructure进行自顶向下的RD搜索
- 允许使用全局上下文transparent的局部编码
- 遵循经典的best-temp向上传播方案
CodingStructure以表示一个局部UnitArea而建立,访问UnitArea之外的信息需要返回上层CodingStructure- 父节点不知道子节点,但是最好的子节点将传递给父节点
实例:
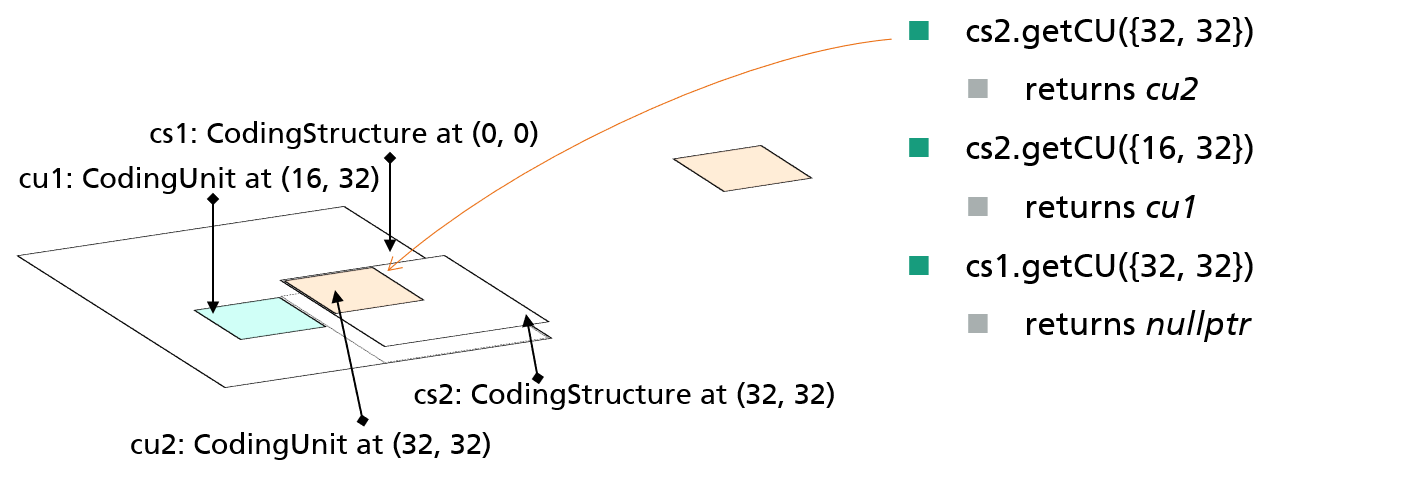
通过cs2访问位于(32,32)的CU,直接返回cu2
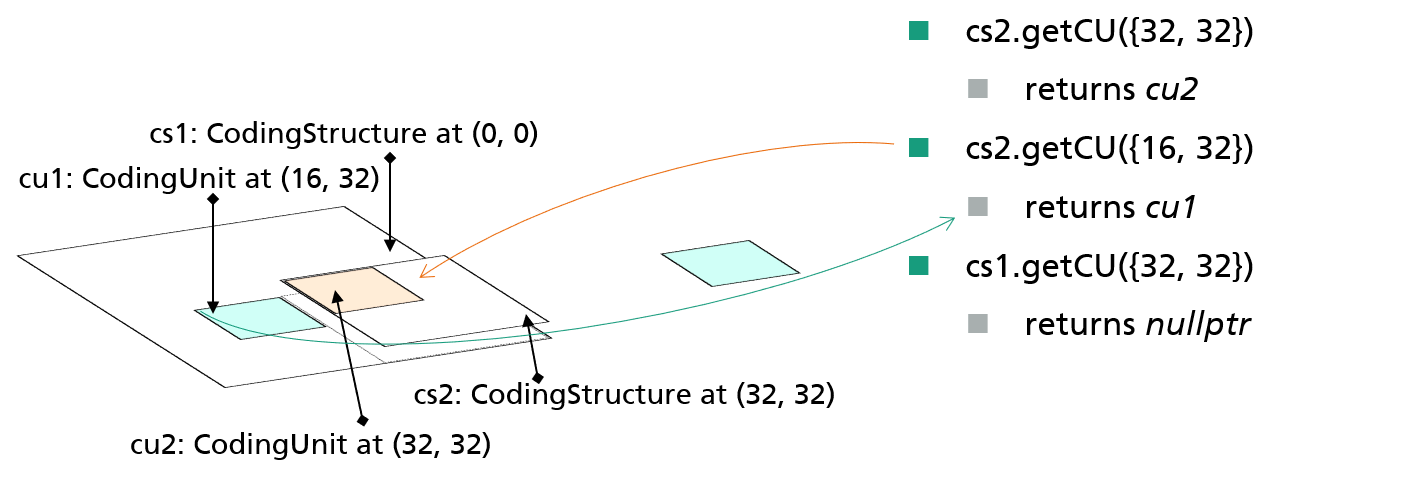
通过cs2访问位于(16,32)位置的CU,通过其父节点cs1,访问返回cu1;

通过cs1访问位于(32,32)位置的CU,cu2属于cs1的子cs,父不能知道子,返回null。
4. Partitioner详解
Partitioner是一个管理划分的类(CU、TU,QT和所有可能的划分)。VTM将区域划分模型化为栈,即新的划分将在当前已处理区域上作为下一级别被创建。
- 包含对当前划分信息的访问方法,当钱划分信息包括实际划分区域的
UnitArea和CU/TU深度信息。 - 包含对划分进行约束的方法,即在特定CU深度级(区域尺寸)上的划分限制。
- 包含对特定划分可能性的可行性分析方法(
canSplit)。
5. CU、PU 和 TU 的遍历访问
在CU中遍历所有的PU和TU方法是一样的,通过调用traversePUs()和traverseTUs()函数。当CU中只含有一个TU/PU时,可采用firstTU、firstPU进行快速访问。迭代器遍历实例如下,
// call xDecoderInterTU for all TUs in the CU described by cu
for(auto& currTU : CU :: traverseTUs( cu ))
{
xDecodeInterTU( currTU, compID );
}
在CodingStructure中遍历所有的CU的实例如下:(迭代器,以decompression CTU为例)
// iterate over all CUs which are contained in the area described by ctuArea
for(auto& currCU : cs.traverseCUs( ctuArea ))
{
// decompress cu
xDecompress( currCU );
}
6. 获取运动信息
VTM中运动矢量存储在哪个结构中?
- 最初和HEVC一样, MV是通过PU获取
- VTM新的数据结构打破了这个惯例,VTM可以和HEVC一样,通过PU获取MV,同时可以在
CodingStructure中,通过绝对位置信息获取MV ---- 更方便,更灵活。
– 需求:subPU精度的MV
– 困难: 存储subPU精度的MV将会破坏PU的逻辑源
– 解决方法:为subPU精度的MV信息设置额外的缓存区 - 实例
Mv mvL0 = cs.getPU( pos ) -> mv[0]; // obsolete low-res call
Mv mvL0 = cs.getMotionInfo( pos ) .mv[0]; // New next-style high-res call
- 通过
PU::spanMitonInfo建立缓存区














 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









