










时隔一个多月,今天接着之前的JEM中的DMVR技术,详细讲讲在目前VTM6.0中的DMVR技术细节,并且对比一下两个版本中DMVR的不同之处,之所以今天又做了一篇,是因为本人老师最近让我详细了解一下DMVR技术,然后在看代码的过程中,并结合网上大神的博客,我才发现之前将JEM中的做法和VTM中的做法给搞混了,因此之前那篇博客实际上写的是JEM中的DMVR,但是标题写成了VTM6.0中的DMVR,这里给看了那篇博客的各位道个歉,今天将那篇博客纠正了一下。博客链接为:H.266/VVC相关技术学习笔记17:VTM6.0中的DMVR(解码端运动矢量细化)技术前言:DMVR在JEM中的实现
本篇博客是上一篇DMVR的后续完结版,根据自己所看的VTM6.0代码以及参考大神的博客,自己总结了一篇目前VTM6.0中的DMVR的具体实现细节,如有不对的地方,欢迎各位大佬指正~
关于VTM6.0之前版本的DMVR技术,可以参考博客:H266/JEM:帧间预测——Decoder side motion vector refinement (DMVR)
本人也是学习这篇博客的。
一、在VVC的JEM版本中
DMVR具体的过程如下图所示:
第一步生成双边模板:在解码端得到初始的Merge双向MV后,在运动补偿阶段,对该块的两个初始MV形成的预测块进行加权,得到一个新的预测块,作为一个初始预测值(即模板),记为P_Ori;
第二步计算初始SAD:然后用该模板和初始的两个MV生成的预测块(图中的蓝色线所指示的块)计算SAD(sum of absolute differences)(前向列表和后向列表分别计算),作为初始的SAD最小值用于后续的SAD的比较,选出最优的候选块及其相应的候选MV。
第三步比较SAD选最优:在初始预测块的周围几个像素的范围内搜索对应的候选块(图中的红色线所指示的块),总共是9个像素点位置,一个初始点以及周边8个点。然后计算P_Ori与各个候选块之间的差值并计算对应的SAD,与初始的SAD最小值相比较,选出SAD最小的那个候选块,得到该候选块的新的MV最为当前编码块的最优MV,也就是对MV进行了细化。

二、在VVC的VTM版本中
VTM中的做法和JEM里具体的做法区别稍微有点大,不过基本的原理是一致的,都是通过在初始的MV周边1-2个像素范围内搜索一个更加精确的MV。在VTM中取代了JEM中用一个双边模板去和每个候选块之间进行SAD的计算,然后比较SAD最小的那个候选MV即是修正后的MV的做法。VTM中直接是直接计算前后两向中的两个预测块(下图中两个红色块)之间的SAD,选取SAD最小的那个MV的组合最为修正后的MV,并生成最终的双向加权预测值。

1、目前在VTM6.0的版本中DMVR的应用条件如下图所示,这是O次会议draft中的描述。:
以及在代码中的描述
//检查DMVR技术是否可用的所以情况
bool PU::checkDMVRCondition(const PredictionUnit& pu)
{
WPScalingParam *wp0;//前向Wp加权权重
WPScalingParam *wp1;//后向Wp加权权重
int refIdx0 = pu.refIdx[REF_PIC_LIST_0];//前向参考帧索引
int refIdx1 = pu.refIdx[REF_PIC_LIST_1];//后向参考帧索引
pu.cu->slice->getWpScaling(REF_PIC_LIST_0, refIdx0, wp0);//获取前向WP的权重
pu.cu->slice->getWpScaling(REF_PIC_LIST_1, refIdx1, wp1);//获取后向WP的权重
#if JVET_O1140_SLICE_DISABLE_BDOF_DMVR_FLAG
//使用DMVR并且BDOF模式下不使用DMVR
if (pu.cs->sps->getUseDMVR() && (!pu.cs->slice->getDisBdofDmvrFlag()))
#else
if (pu.cs->sps->getUseDMVR())
#endif
{
return pu.mergeFlag//是Merge模式
&& pu.mergeType == MRG_TYPE_DEFAULT_N//是常规Merge类型
#if JVET_O0108_DIS_DMVR_BDOF_CIIP
&& !pu.mhIntraFlag//非CIIP模式
#endif
&& !pu.cu->affine//非Affine模式
&& !pu.mmvdMergeFlag//非MMVD_Merge模式
&& !pu.cu->mmvdSkip//非mmvd_Skip模式
&& PU::isBiPredFromDifferentDirEqDistPoc(pu)//当前图片和前向参考图片的POC差等于当前图片和后向参考图片的POC差
&& (pu.lheight() >= 8)//PU的高大于等于8
&& (pu.lwidth() >= 8)//PU的宽大于等于8
&& ((pu.lheight() * pu.lwidth()) >= 128)//PU的尺寸大于等于128
&& (pu.cu->GBiIdx == GBI_DEFAULT)//PU的尺寸大于等于128
&& ((!wp0[COMPONENT_Y].bPresentFlag) && (!wp1[COMPONENT_Y].bPresentFlag))//亮度分量的前向MV权重和后向权重存在flag都等于0(即两个权重都不可用)
;
}
else
{
return false;
}
}
2、在VTM6.0版本中的具体实现细节如下:
首选注明几点需要注意的地方:
(1)DMVR技术在编码端以及解码端同时要执行,虽然该技术是针对于解码端的,但是在编码端执行同样的操作,这为了保证编解码一致,使得DMVR的算法以及在DMVR基础上做的一下技术修改不会出现错误;
(2)DMVR技术修正后的MV既可用于当前PU预测值的生成,也可用于后续空域或者时域上编码块的MV的预测,当然初始的MV的MergeIdx要保留下来,必须将其编码后传到解码端,然后在解码端执行同样的DMVR操作。
(3)由于最大的DMVR的搜索范围为16×16,因此如果当前PU的宽或者高大于16,就必须将其划分为子块进行搜索。对于每个子块的参考区域的大小为23×23。
①第一步需要对初始点周边的位置进行搜索,以寻求更优的MV的偏移
由于在VTM中需要计算前后向的两个候选MV的预测块之间的SAD,因此使得每一个搜索点处MV的偏移都需要遵守一个镜像原则,意思就是前后向两个初始MV都必须同时使用同一个搜索点处的MV的偏移,然后按照镜像的规则,前向初始点加一个偏移,后向的初始点减去对应的相同的偏移,如下公式所示。
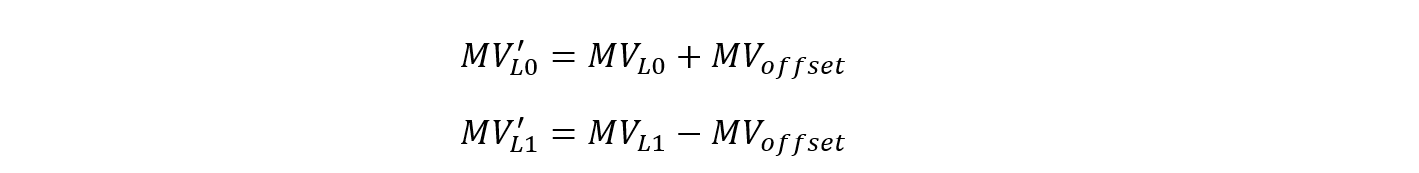
VTM中的代码显示如下(截取部分):
//初始的MV计算出的子CU的前向以及后向的预测值(这里前后向的搜索点遵守镜像方式,即对于同一个MV偏移,前向MV是+MV_Offset,后向MV是-MV_Offset)
Pel *addrL0 = biLinearPredL0 + totalDeltaMV[0] + (totalDeltaMV[1] * m_biLinearBufStride);
Pel *addrL1 = biLinearPredL1 - totalDeltaMV[0] - (totalDeltaMV[1] * m_biLinearBufStride);
//子pu的最终修正后的MV是原来Merge的初始MV加上子Pu的修正MVD(即MV的偏置,前向加偏置,后向减去偏置,呈镜像的方式)
subPu.mv[0] = mergeMv[REF_PIC_LIST_0] + pu.mvdL0SubPu[num];
subPu.mv[1] = mergeMv[REF_PIC_LIST_1] - pu.mvdL0SubPu[num];
其中MV_offset代表修正后MV和初始MV之间的偏移量,在JEM中,由于搜索的最大偏移量只能为一个整像素,因此最多只能有9个搜索点(一个中心初始点和8个周围的点)。但在VTM中,搜索的最大偏移量为2个整像素,因此总共有25个搜索点(一个中心初始点和24个周围的点)。在VTM6.0代码中的缓存如下(在CommonLib库中的InterPrediction.h头文件中定义):
//25个搜索偏置,其中一个是零偏置,就代表初始MV本身,其余24个搜索点都在初始MV基础上在水平和垂直两个方向上进行一定的偏置,最多偏移2个单位
Mv m_pSearchOffset[25] = { Mv(-2,-2), Mv(-1,-2), Mv(0,-2), Mv(1,-2), Mv(2,-2),
Mv(-2,-1), Mv(-1,-1), Mv(0,-1), Mv(1,-1), Mv(2,-1),
Mv(-2, 0), Mv(-1, 0), Mv(0, 0), Mv(1, 0), Mv(2, 0),
Mv(-2, 1), Mv(-1, 1), Mv(0, 1), Mv(1, 1), Mv(2, 1),
Mv(-2, 2), Mv(-1, 2), Mv(0, 2), Mv(1, 2), Mv(2, 2) };
在VTM6.0中的DMVR的搜索过程,分为整像素搜索阶段和分像素搜索阶段。其两个搜索过程大致可以用下面的框图来表示(PPT画的,略有点糙,本人电脑Visio有点问题暂时用不了,不搞了,先把博客写了再说。。),这是根据代码中的逻辑来画的:

(1)整像素搜索阶段
在VTM6.0的版本中,为了减少算法的复杂度,在整像素搜索阶段中使用了提前终止算法(early termination),用来替代25个位置的全搜索,具体算法为:在DMVR的整像素偏移搜索阶段,首先计算初始MV对得到的前后向预测块的SAD,并将该SAD减少其原来的1/4。 如果减少了1/4倍的初始MV对的SAD仍然小于一个阈值(256),则终止DMVR的整像素采样阶段,否则,将按照光栅扫描顺序计算并检查其余24个搜索点的SAD,直到选出SAD最优的整像素偏移值。在代码中具体如下:
//计算初始MV的SADCost,赋值到minCost中,作为一个初始的SADCost(该Cost就是计算两个预测块addrL0以及addrL1之间的差值)
minCost = xDMVRCost(clpRngs.comp[COMPONENT_Y].bd, addrL0, m_biLinearBufStride, addrL1, m_biLinearBufStride, dx, dy);
#if JVET_O0590_REDUCE_DMVR_ORIG_MV_COST
minCost -= (minCost >>2);//在初始的minCost上减去其值的1/4,为了优先选到初始的MV
#endif
//如果减了1/4的初始MV的Cost小于当前子PU的尺寸,即小于一定的阈值,则提前终止整像素搜索阶段直接进入分像素搜索。
if (minCost < (dx * dy))
{
notZeroCost = false;
break;
}
这里的notZeroCost如果为false,就说明后面不进行分像素阶段的搜索。
(2)分像素搜索阶段
这里需要注意的是:如果整像素搜索之前由于初始MV的(SAD-1/4SAD)小于一定阈值而被提前终止,则后面就既不对剩余24点进行搜索,也不进行分像素的搜索阶段。
A、如果再在整像素阶段结束后,得到的偏移值仍然是(0,0),说明初始MV就是最优的MV,因而可以直接进入分像素搜索阶段,通过初始MV点及其周围4个点的SAD通过二维抛物线误差面方程解出最优的分像素的MV偏移值,稍微用分像素去小修正一下即可,不需要整像素级别的大修正。
B、如果再在整像素阶段结束后,得到的偏移值不为(0,0),说明初始MV并不是最好的,最优的MV是其整像素范围内的某个搜索点,因此在遍历完25个搜索点后得到SAD最小的那个整像素搜索点偏移,对初始MV进行一个大修正;然后再进行分像素的搜索,同样用二维抛物线误差面方程解出最优的分像素的MV偏移值。最终的修正Mv是在初始Mv的基础上偏移一个整像素偏移值+分像素偏移值。但是这里需要注意的是如果在进行完整像素的搜索阶段,搜索出的点的水平偏移或者垂直偏移中有一个为±2个像素的单位,则不能进行分像素的搜索阶段,因为处于最外层的搜索点如果作为中心点的话,其周围四个方向的某些点可能不存在,导致无法进行分像素阶段的计算。
具体的分像素搜索阶段考虑到复杂度的问题,在该阶段采用解二维抛物线误差面方程的方法代替传统的比较SAD的方法。在整像素搜索阶段,我们可以得到中心点及其周边4个点的SADCost(中心、上、下、左、右)该过程需要用解一个二维的抛物线误差面方程,将五个整像素搜索点的SAD以及相应的整像素偏移坐标带入,然后解方程组,最终解出Cost最小分像素的位置(X_min,Y_min),也即(dMvX,dMvY)。
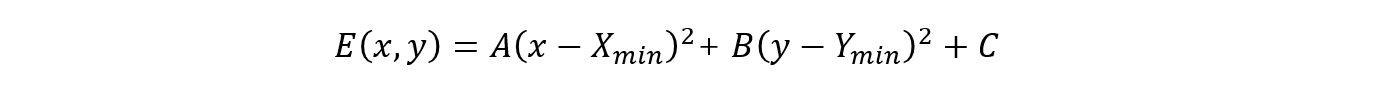
解出上述方程如下图所示:
 求dMvX只需要用横轴上的三个蓝色点从左至右代表sad[0][1]、sad[1][1]、sad[2][1]
求dMvX只需要用横轴上的三个蓝色点从左至右代表sad[0][1]、sad[1][1]、sad[2][1]
求dMvY只需要用纵轴上的三个蓝色点从上至下代表sad[1][0]、sad[1][1]、sad[1][2]
最终求得分像素点(上图中的红色点)。
在代码中五个点的SAD表示为:sadBuffer[0](中心位置)、sadBuffer[1](左)、sadBuffer[2](上)、sadBuffer[3](右)、sadBuffer[4](下)。
sadbuffer[0] = pSADsArray[0];
sadbuffer[1] = pSADsArray[-1];
sadbuffer[2] = pSADsArray[-sadStride];
sadbuffer[3] = pSADsArray[1];
sadbuffer[4] = pSADsArray[sadStride];
DMVR的分像素参数MV的搜索过程中除法的输出值需要被限制到-8到8范围之内,也即意味着分像素精度的偏移量最多不能超过1/2像素的距离,而且因为所有整像素搜索点处的SADcost值都是正整数,且E(0,0)为最小的值,因此分像素搜索过程使用了整像素精度的除法以实现分像素级别的细化。由于中心位置的SADCost是最小的。因此分像素搜索阶段就是用解二维的抛物线误差面方程方法,用5个点处的SADcost再去计算出一个需要偏移的分像素距离,最终在中心位置的周围再偏移一个以分像素精度为单位的距离得到最终的修正MV。
②第二步就是对每个子块进行MV细化后,利用子块的参考区域生成子块的最终运动补偿预测样本。
不同于VTM5.0的是,VTM6.0为了减少子块之间的填充不均匀性,以及减少DMVR的内存带宽,建议在子块参考区域边界执行padding(关于padding,我还有有点没太弄清楚padding在DMVR中的具体细节,后续搞明白了再更新)。即在MV细化过程中,每个子块MV细化后的运动补偿过程仅使用子块参考区域内的23x23个样本,即对于每个子块,仅需要23x23个参考样本,这样的设计可以使DMVR的硬件设计更加规范、简单。此外,DMVR所消耗的内存带宽也会减少。如下图所示:
 代码中的位置如下:
代码中的位置如下:
int filtersize = (compID == (COMPONENT_Y)) ? NTAPS_LUMA : NTAPS_CHROMA;//滤波器尺寸,亮度8抽头,色度4抽头
width = pcPad.bufs[compID].width;//16
height = pcPad.bufs[compID].height;//16
offset = (DMVR_NUM_ITERATION) * (pcPad.bufs[compID].stride + 1);//偏置
int mvshiftTemp = mvShift + getComponentScaleX((ComponentID)compID, pu.chromaFormat);
width += (filtersize - 1);//参考块宽度加7,参考块尺寸变为23
height += (filtersize - 1);//参考块高度加7,参考块尺寸变为23
最后需要解释几个问题:
①为什么要选用SAD作为代价比较的基准,而不是用RDcost?
因为该技术只是用于解码端的MV的修正,因此这时候解码端已经接收到了传过来的码流信息,此时的码率是确知的不变的,因此码率已经无法作为率失真的衡量基准,只有失真可以衡量,所以只需要SAD计算Cost就足够了。
②该技术的背后的原理在哪?
答:我的个人理解就是,在编码端已经得到了可能最优的MV,但在解码端认为这或许不是最优,因此要将其修正,而修正的方式就是利用原始MV预测得到的预测值(输出)反过来作为一个输入,再对MV左适当的细化,这就是一个正反馈的过程,也类似于深度神经网络中的反向传播过程,利用神经末端的输出反过来影响权重和神经元偏置。
③目前VTM6.0中由于觉得细化的MV并不一定比原始的MV更好,因此在DMVR的过程中优先考虑使用原始的MV,来减少DMVR细化过程中的不确定性带来的性能上的损失。在VTM5.0中没有flag去标志DMVR技术是否启用,因此之前都是在解码端总是默认启用DMVR技术的,现在加上了一个启用DMVR的flag,可以控制DMVR是否启用。在此基础上将初始的MV对的前向以及后向的预测块之间的SAD的值减少了原来的1/4,这样该SAD值在与其他搜索点的SAD比较的时候更具优势,这样就能在后续的SAD比较中大程度上优先原始MV。这里选用1/4,应该考虑到计算复杂性的问题,减少1/4只需要添加一次移位和一次加法,而且1/4应该是1/2,1/4,1/8,1/16中效果最好的,减的太少也不行,减的太多也不行。















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









