








在字典树中加入失配链(也可以叫做失败指针)就可以构成AC自动机,可以用来解决多模式匹配的问题。给定多个模式串P0、P1、……,给定目标串T,问T中包含了哪些P……等等问题。
在AC自动机中,每一个节点都有一个失败指针指向自动机中的另外一个节点;除了根节点,根节点的失败指针指向NULL。假设节点A的失败指针指向节点B,说明节点A的向上的字符串与从根到B的字符串匹配,而且匹配长度是最长的。
如下的AC自动机,红色箭头代表失败指针。sh节点的失败指针指向h,因为sh的后缀与h是匹配的;she的失败指针指向he,因为she的后缀与he匹配;sheb的失败指针指向eb……当然,she的失败指针不指向e,是因为he匹配的更长。与此同时,所有其他的非根节点都有失败指针,只不过都指向根节点,就没有画出来。很显然,失败指针都是指向更靠上的节点。

AC自动机的使用过程基本分为3步:首先建字典树,其次在字典树上建立失败指针,最后是查询。字典树的建立过程比较简单, 可以参考这里。失败指针的建立是一个BFS的过程,利用已求出失败指针的节点去解未知的节点。
考虑某个节点v,它的失败指针应该指向哪里?假设v的父节点为f,v在f的排行是sn,f节点的失败指针指向f2,则如果f2也有sn儿子v2,则v的失败指针就应该指向v2。如果f2没有sn儿子,就应该去找f2的失败指针指向的节点f3,如果f3有sn儿子v3,则v的失败指针就应该指向v3。否则就应该再沿着失败指针向上走。
- 首先,所有一级子节点的失败指针都指向根,且入队
- 当队列不为空
- 取出头节点u,
- 对u的每个儿子v
1.沿着u的失败指针一直走,直到找到相同排序的儿子或者到达了根
2.如果没有相同排序的儿子,则v的失败指针指向根
3.否则指向相同排序的那个节点
4.将v入队
AC自动机的查询与字典树类似,给定目标串T和AC自动机,对T中的每个字母t,如果当前节点有t儿子,则前往t儿子节点;否则沿着失配链一直走,直到某个节点有t儿子或者到达了根节点。所以失败指针就是在匹配失败的时候起作用。
AC自动机查询的另一要点是:对每个节点,需要查询整个失配链!如上图的AC自动机,其字典是{shea,sheb,h,he,eb},假设给定字符串为sheb,问该字符串包含了字典中的几个单词?如果只沿着路径往下,最后停留在叶子节点,答案就是1;但实际上答案是4,只要统计了失配链上的所有节点,就能得到正确答案。考虑到整个失配链,显然不会是所有节点都是单词的结尾,所以还可以建立专门的指针指向这些节点,用以加快失配链的搜索速度。
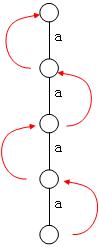
AC自动机实际上就是在字典树上做KMP,反过来可以把KMP看做是单单词字典树的AC自动机。考虑到字符串aaaa,其特征向量是(0123),其AC自动机如下,可以看到失败指针恰好可以对应特征向量。
hdu2222是基本的AC自动机题目。给定一系列的关键词,问T中包含多少个关键词。这道题题意稍微有点模糊。第一,关键词集合中可能包含一模一样的单词,如果K在关键词集合中出现了n次,则T中出现一次K的时候就必须认为T包含了n个关键词;第二,如果关键词K只在集合中出现了一次,而是在T中重复出现了多次,则只能说T中包含了一个关键词。由于给定一个字典,只需查询一个T,所以在查询的时候修改节点标记,可以一下解决这两个问题。
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
#define SIZE 1000001
/*trie树,node[0]是root*/
struct node_t{
node_t* child[26];
node_t* failer;
int cnt;//表示该单词在字典中出现的次数
}Node[10000*51];
int toUsed = 1;
/*建立trie树*/
void insert(char const word[]){
node_t* loc = Node;
for(int i=0;word[i];++i){
int sn = word[i] - 'a' ;
if ( !loc->child[sn] ){
memset(Node+toUsed,0,sizeof(node_t));
loc->child[sn] = Node + toUsed ++;
}
loc = loc->child[sn];
}
++loc->cnt;
}
/*建立失败指针*/
void buildAC(){
Node[0].failer = NULL;/*root的failer为空*/
queue<node_t*> q;
for(int i=0;i<26;++i){//一级子节点的失败指针指向根
node_t* p = Node[0].child[i];
if ( p ){
p->failer = Node;
q.push(p);
}
}
while( !q.empty() ){
node_t* father = q.front(); /*取出1个节点*/
q.pop();
for(int i=0;i<26;++i){
node_t* p = father->child[i];
if ( p ){
node_t* v = father->failer;
while ( v && !v->child[i] ) v = v->failer; /*如果不匹配反复寻找failer,v为空说明已经到根节点*/
/*判断v为空一定要放在前面*/
if ( !v ) p->failer = Node;/*如果v为空,则failer指向root*/
else p->failer = v->child[i];
q.push(p);
}
}
}
}
/*搜索,返回匹配的单词数量*/
int search(char const word[]){
int ans = 0;
node_t* loc = Node;
for(int i=0;word[i];++i){
int sn = word[i] - 'a';
while( loc && !loc->child[sn] ) /*沿着分支或者失败指针一直找,直到找到或者到root*/
loc = loc->failer;
loc = loc ? loc->child[sn] : Node; /*定位到新的节点*/
node_t* p = loc; /*将该节点所在的失配链的所有cnt加上*/
while( p != Node && p->cnt >= 0 ){
ans += p->cnt;
p->cnt = -1; /*表明该失配链已经匹配过了,以后不必再考虑*/
p = p->failer;
}
}
return ans;
}
char T[SIZE],Word[55];
int main(){
int nofkase;
scanf("%d",&nofkase);
while(nofkase--){
toUsed = 1;
memset(Node,0,sizeof(node_t));
int n;
scanf("%d",&n);
for(int i=0;i<n;++i){
scanf("%s",Word);
insert(Word);
}
buildAC();
scanf("%s",T);
printf("%d\n",search(T));
}
return 0;
}















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









