







1. 概率检索模型
文档属于“相关”类的概率与属于“不相关”类的概率的比值(也叫“优势比”)。
显然,这个比值越大,代表该文档与查询的相关度越大,因此我们就把看做是相关度得分,最后通过将文档排序。


推导:
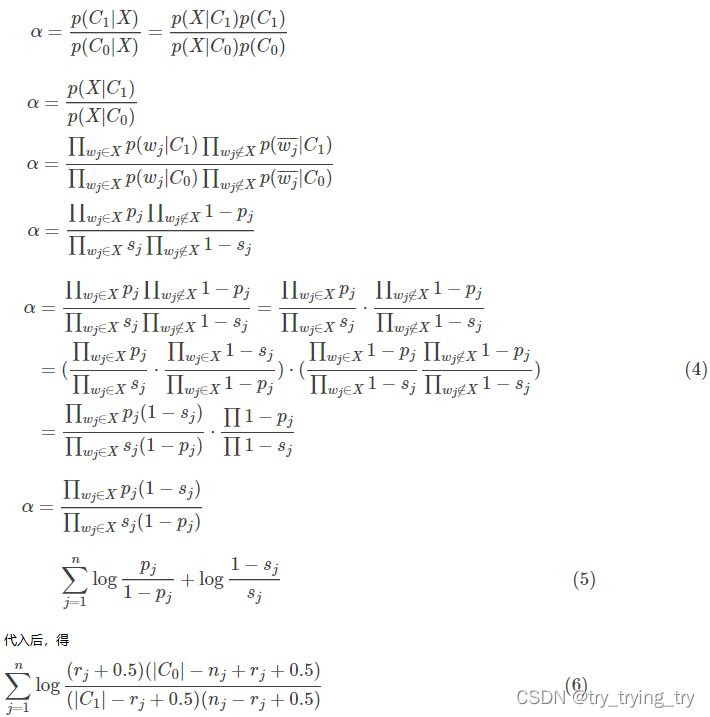
公式(6)也叫做Robertson-Sparck Jones等式
2. K近邻
KNN最近邻 (k-Nearest Neighbors, KNN) 算法是一种分类算法,1968年由 Cover和 Hart 提出。
思想: 一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。
3. 模糊k近邻alg
[paper] James M Keller, Michael R Gray, James Givens. A fuzzy K-nearest neighbor algorithm. systems man and cybernetics, 1985.
[硕士论文]基于子空间方法的人脸识别算法研究 2014计算机技术
思路

PS:
硕士论文]复杂交通环境下的人体运动目标识别算法研究 徐霞平
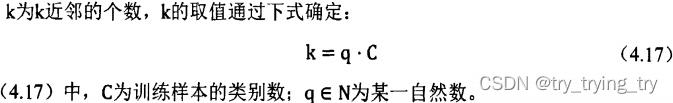
粒子群优化算法(PSO)
概括:
群体中个体之间的协作和信息共享来find最优解。
优势:简单容易实现,且无多参数的调节
粒子:速度位置<方向>
思路如下

3.灰色预测模型
4.自动微分
5. 核密度估计
Matlab ksdensity介绍















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









