









这是一篇发表在 ICML 2013 的文章,作为半监督神经网络的一篇代表文章。【文章】【代码】文章中采用了pesudo-label的方法来作为无标签样本的伪标签。文章的主要想法是self-training,伪标签的确定也是通过有标记样本训练的神经网络,来对无标记的样本进行预测,选择出只选择对每个未标记的样本具有最大预测概率的类。
这个方法为什么会成功,文章中解释到:(1)低密度分离(2)熵要小,这里主要应用在无标记样本上,使无标签样本的信息熵最小。这两点其实是半监督学习中经常考虑的基本原则。
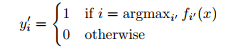
其中损失函数如下:
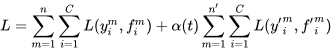
这里
y
i
m
y_i^m
yim是有标签样本的真实标签,
f
i
m
f_i^m
fim是神经网络的输出标签,前边这项很好理解,就是监督学习下的神经网络的损失函数。而后边这项,是无标记样本的损失项。其中
y
i
′
m
y_i^{'m}
yi′m是1或者0,
y
i
′
m
y_i^{'m}
yi′m是伪标签,而
f
i
′
m
f_i^{'m}
fi′m是神经网络的输出。
a
(
t
)
a(t)
a(t)是一个权重系数。
a
(
t
)
a(t)
a(t)太大,就会扰乱有标签的数据;如果
a
(
t
)
a(t)
a(t)太小,无对无标记样本对促进学习没有任何帮助。
a
(
t
)
a(t)
a(t)的确定,就对算法好坏有着直接影响,文章中采用模拟退火算法,来确定
a
(
t
)
a(t)
a(t)。文章中,的损失函数其实就是两部分的结合,在给无标签样本添加标签后,然后选择置信度高的样本扩充到有标签的样本中,在训练模型,不断的更新模型,其实质笔者认为还是self-training的模式,在给定伪标签的方式,不再像传统的聚类,或者分类算法给出,在一定程度上能解决因为标签标签噪声带来模型崩溃的问题。
实验结果
数据集:MNIST
pseudo-labeld达到了当时的state-of-the-art的水平。
















 4581
4581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









