






摘要:提出了一种简单有效的深神经网络半监督学习方法。基本上,所提出的网络是以有监督的方式训练,同时有标记和无标记的数据。对于未标记的数据,伪标签,只是选取具有最大预测概率的类,就好像它们是真的labels一样使用。这实际上相当于熵正则化。它支持类之间的低密度分离,这是半监督学习的一个常见假设。该方法在Denoising Auto-Encoder(DAE)和Dropout的情况下,优于传统的半监督学习方法,在MNIST-handrit-10位数据集上对非常小的标记数据进行半监督学习。
年份: 2013
作者:
Dong-Hyun Lee
Université de Montréal — 蒙特利尔大学–加拿大
代码链接:
https://github.com/iBelieveCJM/pseudo_label-pytorch
2. Pseudo-Label Method for Deep
2.2. Denoising Auto-Encoder(DAE)
2.2.1自动编码器(AutoEncoder)(AE)
*参考 https://www.cnblogs.com/neopenx/p/4370350.html*
- 自动编码器基于这样一个事实:原始input(设为x)经过加权(W、b)、映射(Sigmoid)之后得到y,再对y反向加权映射回来成为z。
- 通过反复迭代训练两组(W、b),使得误差函数最小,即尽可能保证z近似于x,即完美重构了x。
- 那么可以说正向第一组权(W、b)是成功的,很好的学习了input中的关键特征,不然也不会重构得如此完美。结构图如下:

2.2.2自动编码器(AutoEncoder)
- 怎么才能使特征很鲁棒呢?就是以一定概率分布(通常使用二项分布)去擦除原始input矩阵,即每个值都随机置0,
这样看起来部分数据的部分特征是丢失了。 - 以这丢失的数据x’去计算y,计算z,并将z与原始x做误差迭代,这样,网络就学习了这个破损(原文叫Corruputed)的数据。这个破损的数据是很有用的,原因有二:
其之一,通过与非破损数据训练的对比,破损数据训练出来的Weight噪声比较小。降噪因此得名。原因不难理解,因为擦除的时候不小心把输入噪声给×掉了。
其之二,破损数据一定程度上减轻了训练数据与测试数据的代沟。由于数据的部分被×掉了,因而这破损数据一定程度上比较接近测试数据。(训练、测试肯定有同有异,当然我们要求同舍异)。
这样训练出来的Weight的鲁棒性就提高了。图示如下:

2.4. Pseudo-Label
参考https://blog.csdn.net/qq_20291997/article/details/110230570
Pseudo-Label :我们只选取对每个未标记样本具有最大预测概率的类,假定为真实的目标类,公式如下:
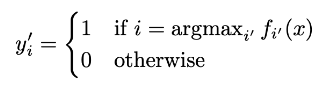
训练过程:训练分为两步,第一步用标注好的数据对网络进行正常训练,随后第二步利用带有伪标签的未标注数据进行微调,并且每次训练完成都更新伪标签重新进行训练,直到模型训练完成。
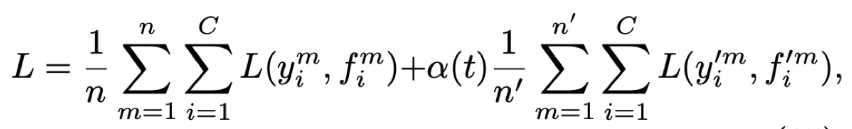
- 其中n分别是标注数据和未标注数据的数量
- f是网络的输出,y是样本的label,未标注数据也类似
- a(t)是平衡系数,用于平衡标注数据与未标注数据对损失的贡献;为了自适应的对a(t)进行调整,我们在此利用模拟退火算法计算a(t),公式如下:
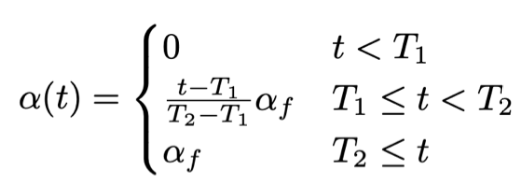
其中T1和T2分别表示两个阶段: - 当t<T1时,也就是初始阶段,伪标签的元素不参与loss的评估。此时完全通过标注数据对网络进行训练
- 当t>T2时,也就是微调阶段,伪标签元素通过一个最大的权重af参与模型的训练
- 当处于中间阶段,也就是T1<=t<=T2时,我们逐渐增大伪标签元素的权重:
- T2-T1表示微调阶段与初始阶段的“距离”,是个定值
- t-T1表示当前阶段与初始阶段的“距离”,随着训练过程的进行该值越来越大,当t进行到T2时,该比值为1,表示训练过程进入微调阶段。
每次训练完毕后,都会更新各未标注样本的伪标签,再重新参与新的训练,直到训练过程彻底结束。
3. Why could Pseudo-Label wor(为什么伪标签模型有效)?
- 低密度分离
聚类假设指出,决策边界应该位于低密度区域,以提高泛化性能。 - Entropy Regularization 熵正则化(待完善)
这个熵用于度量类间的重叠。随着类间重叠的减少,决策边界上的数据点密度降低。 - 使用伪标签作为熵正则化的训练
带与不带Pseudo-Label的效果对比。


4. 实验结果
数据集:MNIST
把标注数据减少为100,600,1000,3000。比较了其它论文的结果,相对于传统的方法,这种新的半监督方法获得了很好的效果。
结论
该算法通过一个简单的损失函数就能利用数据集中没有标签的数据,而且对原始模型几乎不需要任何修改,也没有增加额外的需要进行训练的参数。据论文所述甚至已经超越当时的SOTA方法,因此是个简单有效的半监督学习策略。















 7527
7527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









