









提出了一种简单有效的深神经网络半监督学习方法。基本上,所提出的网络是以有监督的方式训练,同时有标记和无标记的数据。对于未标记的数据,伪标签,只是选取具有最大预测概率的类,就好像它们是真的la-bels一样使用。这实际上相当于熵正则化。它支持类之间的低密度分离,这是半监督学习的一个常见假设。该方法在去除噪声的自动编码和丢失的情况下,优于传统的半监督学习方法,在MNIST-handrit-10位数据集上对非常小的标记数据进行半监督学习
核心思想
Pseudo-Label :伪标签是未标记数据的“假定”目标类,就好像是这些数据的真标签一样。我们只选取对每个未标记样本具有最大预测概率的类,公式如下:
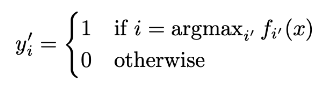
训练过程
We use Pseudo-Label in a fine-tuning phase with Dropout. The pre-trained network is trained in a su- pervised fashion with labeled and unlabeled data si- multaneously. For unlabeled data, Pseudo-Labels re- calculated every weights update are used for the same loss function of supervised learning task.
训练分为两步,第一步用标注好的数据对网络进行正常训练,随后第二步利用带有伪标签的未标注数据进行微调,并且每次训练完成都更新伪标签重新进行训练,直到模型训练完成。
核心公式
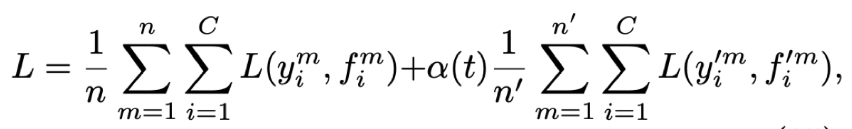
-
其中n分别是标注数据和未标注数据的数量
-
f是网络的输出,y是样本的label,未标注数据也类似
-
a(t)是平衡系数,用于平衡标注数据与未标注数据对损失的贡献;为了自适应的对a(t)进行调整,我们在此利用模拟退火算法计算a(t),公式如下:
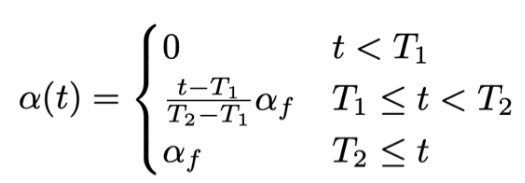
其中T1和T2分别表示两个阶段:-
当t<T1时,也就是初始阶段,伪标签的元素不参与loss的评估。此时完全通过标注数据对网络进行训练
-
当t>T2时,也就是微调阶段,伪标签元素通过一个最大的权重af参与模型的训练
-
当处于中间阶段,也就是T1<=t<=T2时,我们逐渐增大伪标签元素的权重:
- T2-T1表示微调阶段与初始阶段的“距离”,是个定值
- t-T1表示当前阶段与初始阶段的“距离”,随着训练过程的进行该值越来越大,当t进行到T2时,该比值为1,表示训练过程进入微调阶段。
-
每次训练完毕后,都会更新各未标注样本的伪标签,再重新参与新的训练,直到训练过程彻底结束。
结论
该算法通过一个简单的损失函数就能利用数据集中没有标签的数据,而且对原始模型几乎不需要任何修改,也没有增加额外的需要进行训练的参数。据论文所述甚至已经超越当时的SOTA方法,因此是个简单有效的半监督学习策略。















 7527
7527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









