







目录
C++基本数据类型中表示字符的有两种:char、wchar_t。
区别于C#中的char和string 见文章C#中的字符编码方式以及一些字符集相关的函数_c# 字符串编码_ivy_0709的博客-CSDN博客
1.char
本质上,内存中存的就是一个char是一个8个bit,0101的值,至于怎么解析这个0101,其值代表什么字符,怎么显示给你看的,就是有一个对应的字符编码表了。
一个char占一个字节(8bit)。如果你要定义中文字符,其空间要预留够大,因为:
中文字符,占用的是2个字节,即2个char。
英文字符,占用的是1个字节,即1个char。
下面定义的“str” 为4个字节的char数组。
等号右边“中”是字符常量,const char [3],本身“中”字占用2个字节,加上字符常量末尾自动添加的0。
所以如果等号左边 str 定义的是 < 3 的数组长度就会提示编译不通过了。
为什么中文字符占用两个字节,因为C++中中文字符用的是GBK编码的编码方式。
ps:
那么这个CPP文件是一个文本文件,选择不同的编码方式,其文本的二进制码就是不同的。一般的CPP都是选用utf编码格式的。
文本本身的编码格式,和C++对这个字符的编码格式,不是同一个概念。
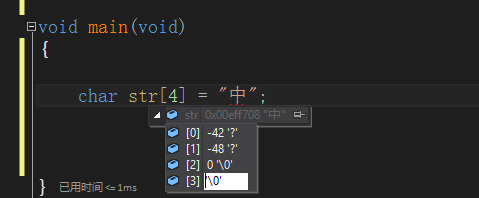
比如上述的存的是 -42 和 -48 的原因就是 “中”的GBK编码的码值为 D6D0。
D6,也就是用有符号的一个字节表示的 -42。char 有符号的
D0,也就是用有符号的一个字节表示的 -48。
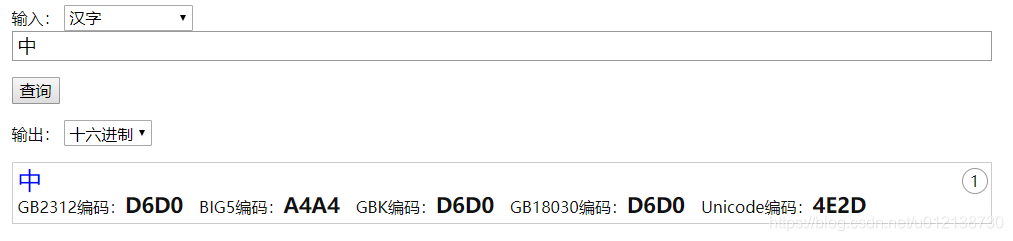
查看文字的编码网址:汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode
2.wchar_t
一个wchar_t占2个字节。16个bit位。
一个字符 占用一个 wchar_t,不管是中文字符还是英文字符。
下面定义的“str” 为2个字节的wchar_t数组。
等号右边L“中”是宽字符常量,const wchar_t[2],本身“中”字占用一个wchar_t(2个字节),加上字符常量末尾自动添加的0。
所以如果等号左边 str 定义的是 < 2 的数组长度就会提示编译不通过了。
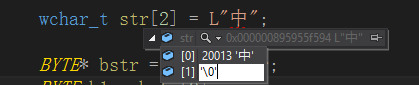
为什么是20013。
因为宽字符用的是unicode,而且是utf16,中,“中”的unicode码点是4E2D,而对于一般的字符utf16正好就是直接是码点的值,因为都是16位的。
wchar_t 是 unsigned short(16bit的),那么就是4E2D就是20013。
3.TCHAR这个宏的类型
我们说过在 详解windows记事本的4种编码方式 中说过字符集 和 字符编码方式的概念。
那么在C++中我们也可以选择使用什么字符集,是unicode字符集,还是其他字符集:
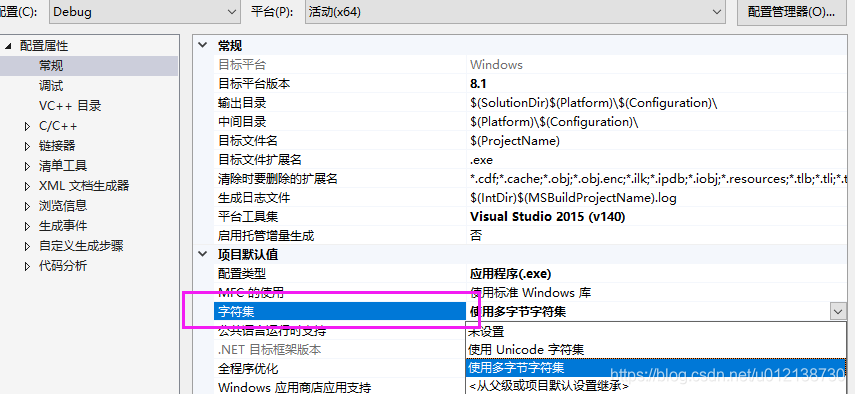
这里要特别注意:!!
当配置选择 使用多字节字符集的时候 TCHAR 为 char(注意,char对中文字符的编码是GBK。2个字节。其他ascii字符是1个字节)(为什么这叫多字节,应该就是一个字符需要用多个TCHAR来编码的意思吧。)。
当配置选择 使用Unicode字符集的时候 TCHAR 为 wchar_t(wchar_t对中文字符的编码是Unicode。始终是2个字节,不管是中文字符还是其他ascii字符。)
具体的实现方式:是通过是否定义了_UNICODE宏,对TCHAR进行设置为上述说的不同的类型,是char还是wchar_t。
所以,上面的配置只是针对于TCHAR这个宏用的char还是wchar_t。
即使当你配置中选择了使用Unicode字符集的时候,你还是可以在代码中使用char类型来表示中文,其值还是使用GBK的编码方式。
当你配置中选择了使用多字节字符集的时候,你也还是可以在代码中用wchar_t类型来表示中文时,其值是使用utf16的编码方式。
char 和 wchar_t 对字符的编码的方式,不会随着配置中选择了什么字符集而改变,该是什么还是什么。
4.std::wstring和 std::string
std::wstring
是一个泛型的类,其中的类型是wchar_t typedef basic_string<wchar_t> wstring;
This is an instantiation of the basic_string class template that uses wchar_t as the character type, with its default char_traits and allocator types
wstring.length
其实就是 std::basic_string::length
Returns the length of the string, in terms of number of characters. 所以这里的字符是wchar的个数(如果是string 就是char的个数。)
This is the number of actual characters that conform the contents of the basic_string, which is not necessarily equal to its storage capacity.
Both basic_string::size and basic_string::length are synonyms and return the same value.
4.一些函数
1.char 转化为 16进制字符串
比如 char* 是utf8编码的字符,那输出char*显示肯定是乱码,因为char是用GBK编码的。
通过下面的函数输出原始的utf8编码的16进制值。
注意:当16进制的值是一位数的时候,需要保留前面的0:
#include <iostream>
#include <stdlib.h>
#include <string.h>
using namespace std;
void main(void)
{
// 这里没有模拟utf8编码的字符,只是举例转为16进制的过程
char str[15] = "假如是一堆乱码";
char hex_final[100] = "";
char ch2[3]="";
// 最后一个str[14] = 0 就不翻译为hex了
for (int i = 0; i < 14; ++i)
{
sprintf(ch2,"%02x",str[i]);
strcat_s(hex_final, ch2);
}
cout << hex_final << endl;
}3.是否是utf8函数
bool IsTextUTF8(const std::string& str)
{
char nBytes=0;//UFT8可用1-6个字节编码,ASCII用一个字节
unsigned char chr;
bool bAllAscii = true; //如果全部都是ASCII, 说明不是UTF-8
for(int i=0; i < str.length();i++)
{
chr = str[i];
// 判断是否ASCII编码,如果不是,说明有可能是UTF-8,ASCII用7位编码,
// 但用一个字节存,最高位标记为0,o0xxxxxxx
if( (chr&0x80) != 0 )
bAllAscii= false;
if(nBytes==0) //如果不是ASCII码,应该是多字节符,计算字节数
{
if(chr>=0x80)
{
if(chr>=0xFC&&chr<=0xFD) nBytes=6;
else if(chr>=0xF8) nBytes=5;
else if(chr>=0xF0) nBytes=4;
else if(chr>=0xE0) nBytes=3;
else if(chr>=0xC0) nBytes=2;
else{
return false;
}
nBytes--;
}
}
else //多字节符的非首字节,应为 10xxxxxx
{
if( (chr&0xC0) != 0x80 ){
return false;
}
nBytes--;
}
}
if( nBytes > 0 ) //违返规则
return false;
if( bAllAscii ) //如果全部都是ASCII, 说明不是UTF-8
return false;
return true;
}
2.字符串的UTF-8与GBK(或GB2312)编码转换
要么用别人写好的库 iconv
要么自己照轮子造轮子 不是很复杂的话可以用这个方法方便,如下:
C/C++,字符串的UTF-8与GBK(或GB2312)编码转换_devc++可以调gbk编码吗_xiaohu_2012的博客-CSDN博客
#include <iostream>
#include <string>
#include <fstream>
#include <windows.h>
using namespace std;
string Utf8ToGbk(const char *src_str)
{
int len = MultiByteToWideChar(CP_UTF8, 0, src_str, -1, NULL, 0);
wchar_t* wszGBK = new wchar_t[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, src_str, -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char* szGBK = new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, szGBK, len, NULL, NULL);
string strTemp(szGBK);
if (wszGBK) delete[] wszGBK;
if (szGBK) delete[] szGBK;
return strTemp;
}
string GbkToUtf8(const char *src_str)
{
int len = MultiByteToWideChar(CP_ACP, 0, src_str, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, src_str, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
string strTemp = str;
if (wstr)
delete[] wstr;
if (str)
delete[] str;
return strTemp;
}
UE里面自带的字符转换函数
// Conversion typedefs
typedef TStringConversion<TCHAR,ANSICHAR,FANSIToTCHAR_Convert> FANSIToTCHAR;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToANSI_Convert> FTCHARToANSI;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToOEM_Convert> FTCHARToOEM;
typedef TStringConversion<ANSICHAR,TCHAR,FTCHARToUTF8_Convert> FTCHARToUTF8;
typedef TStringConversion<TCHAR,ANSICHAR,FUTF8ToTCHAR_Convert> FUTF8ToTCHAR;


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











