







 布隆过滤器是一种用于判断集合中是否存在特定元素的算法,常用于搜索引擎和爬虫项目。通过一系列随机映射函数将元素映射到二进制向量中,存在误判可能但概率极低。在爬虫中,它可以用来避免重复访问URL,32M的布隆列表在2%误判率下可处理16K URL。Java实现中使用BitSet和哈希函数完成插入和检查操作。
布隆过滤器是一种用于判断集合中是否存在特定元素的算法,常用于搜索引擎和爬虫项目。通过一系列随机映射函数将元素映射到二进制向量中,存在误判可能但概率极低。在爬虫中,它可以用来避免重复访问URL,32M的布隆列表在2%误判率下可处理16K URL。Java实现中使用BitSet和哈希函数完成插入和检查操作。
布隆过滤器是一个判断集合中是否包含特定元素的算法。比如,判断一个英文单词是否在字典中(单词拼写检查);黑名单检查等。也常用在搜索引擎中。布隆过滤器由一个很长的二进制向量和一系列随机映射函数组成。提供插入但不提供删除,但有用计数器代替bit位的变体提供删除操作。
以存储邮件地址为例:
假定存储一亿个电子邮件地址.
1. 先建立一个16 亿二进制常量,即两亿字节的向量,然后将这16 亿个二进制位全部设置为零。
2. 对于每一个电子邮件地址X,用8 个不同的随机数产生器(F1,F2, …, F8)产生8 个信息指纹(f1, f2, …, f8)。
3. 再用一个随机数产生器G 把这8 个信息指纹映射到1 到16 亿中的8 个自然数g1, g2, …, g8。
现在我们把这8 个位置的二进制位全部设置为1。当我们对这1 亿个E-mail 地址都进行这样的处理后。一个针对这些E-mail地址的布隆过滤器就建成了,如图所示
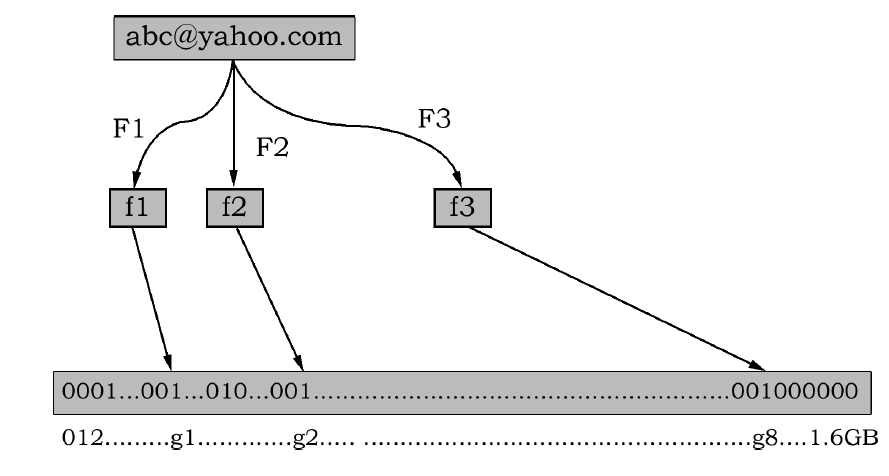
在检测一个电子邮件是否在黑名单采用如下步骤:
1. 用8 个随机数产生器(F1, F2, …, F8)对这个地址产生8 个信息指纹S1, S2, …, S8。
2. 将这8 个指纹对应到布隆过滤器的8 个二进制位,分别是T1, T2, …, T8。
如果Y 在黑名单中,显然,T1, T2, …, T8 对应的8 个二进制位一定是1。这种方法有一个缺点就是可能会出现误判。但这种情况概率非常小,并且可以用白名单的方法来补救。误判率与保存时占用的bit数负相关,见下表:
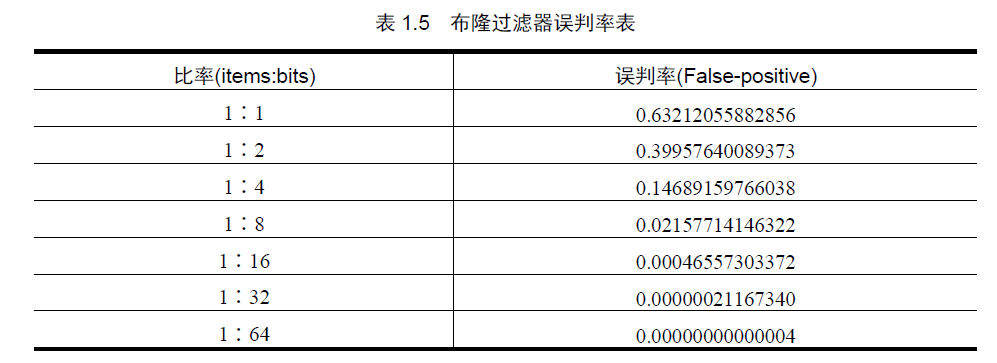
我在爬虫项目中用布隆过滤器保存已经访问过的URL。一个URL用8个指纹信息映射,布隆列表长32M,可以在2%的错误率下映射16K个URL。用java代码实现的时候分为两步:
1. 用BitSet类构建一个定长二进制表;类构建一个哈希数组(8个哈希函数)。
2. 定义插入和检查两个函数。
说明:
BitSet是java.util中的一个类,大小可变,值为boolean类型。提供set、get、clean等操作。可以参考博文java中的BitSet学习进一步了解。
其实核心代码很短,下面是工程代码的一部分,所以略有冗长。
布隆过滤器java代码如下:
import java.util.BitSet;
public class Bloom 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









