







 超级会员免费看
超级会员免费看
 Baichuan2是基于2.6万亿token训练的大型语言模型,涉及数据处理、tokenizer优化、位置嵌入、激活与规范化、优化策略、基础设施建设、对齐方法和安全性等方面。训练过程中,使用了RoPE和ALiBi位置嵌入,SwiGLU与xformers注意力,以及NormHead等技术。在对齐策略中,采用了sft和rlhf方法,并设计了多层次的奖励模型以提升多样性。
Baichuan2是基于2.6万亿token训练的大型语言模型,涉及数据处理、tokenizer优化、位置嵌入、激活与规范化、优化策略、基础设施建设、对齐方法和安全性等方面。训练过程中,使用了RoPE和ALiBi位置嵌入,SwiGLU与xformers注意力,以及NormHead等技术。在对齐策略中,采用了sft和rlhf方法,并设计了多层次的奖励模型以提升多样性。
1.introduction
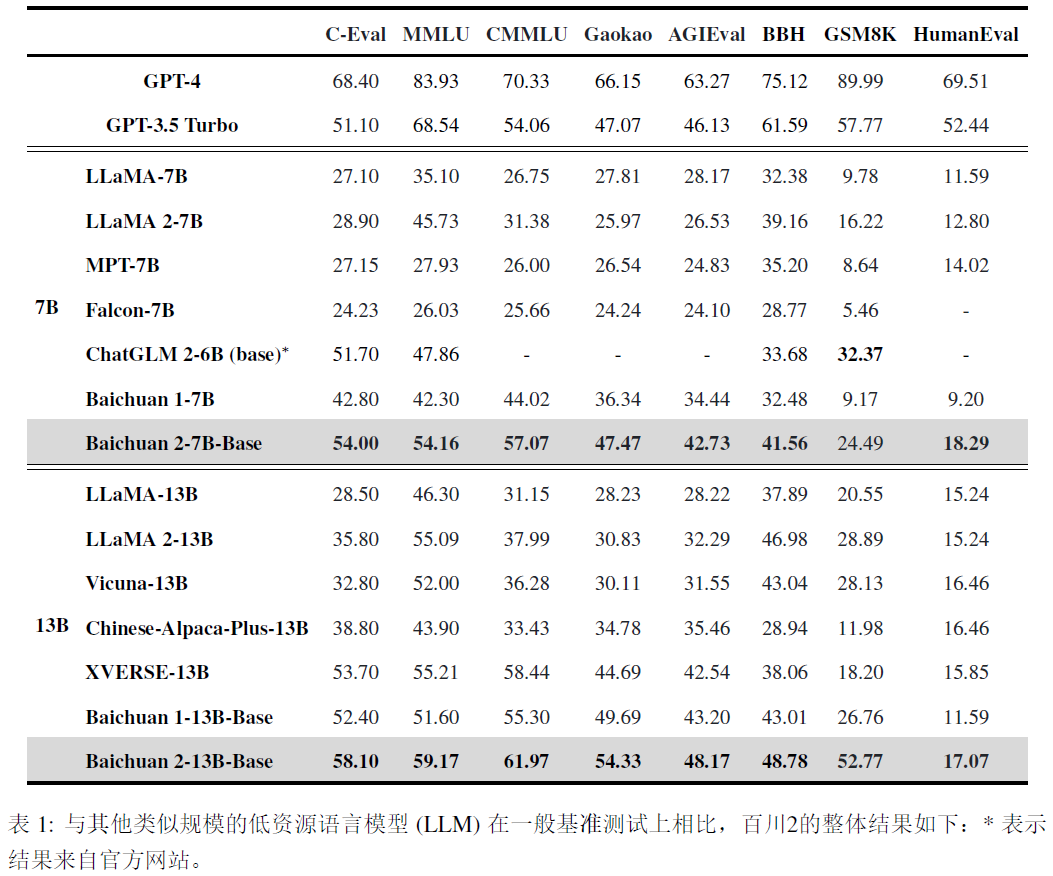
baichuan2基于2.6万亿个token进行训练。
2.pre-training
2.1 pre-training data
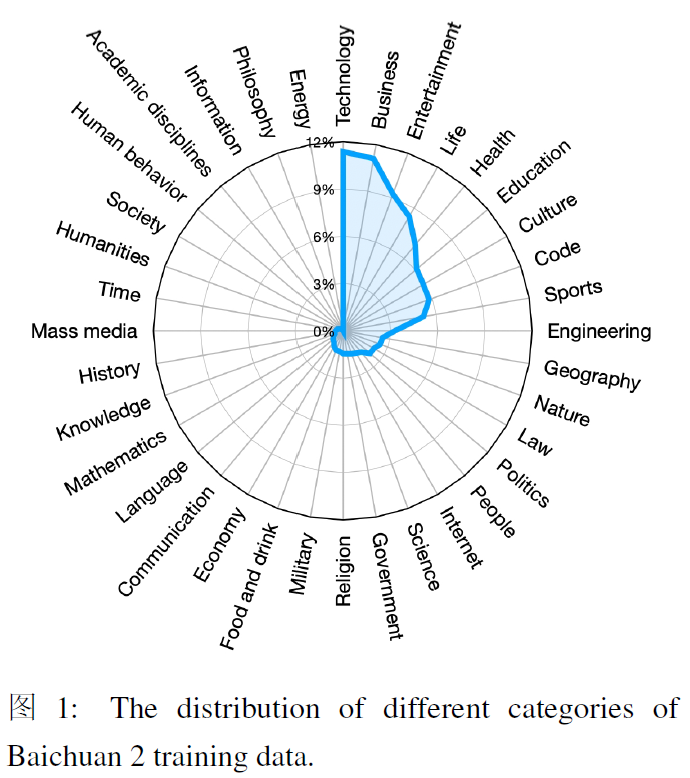
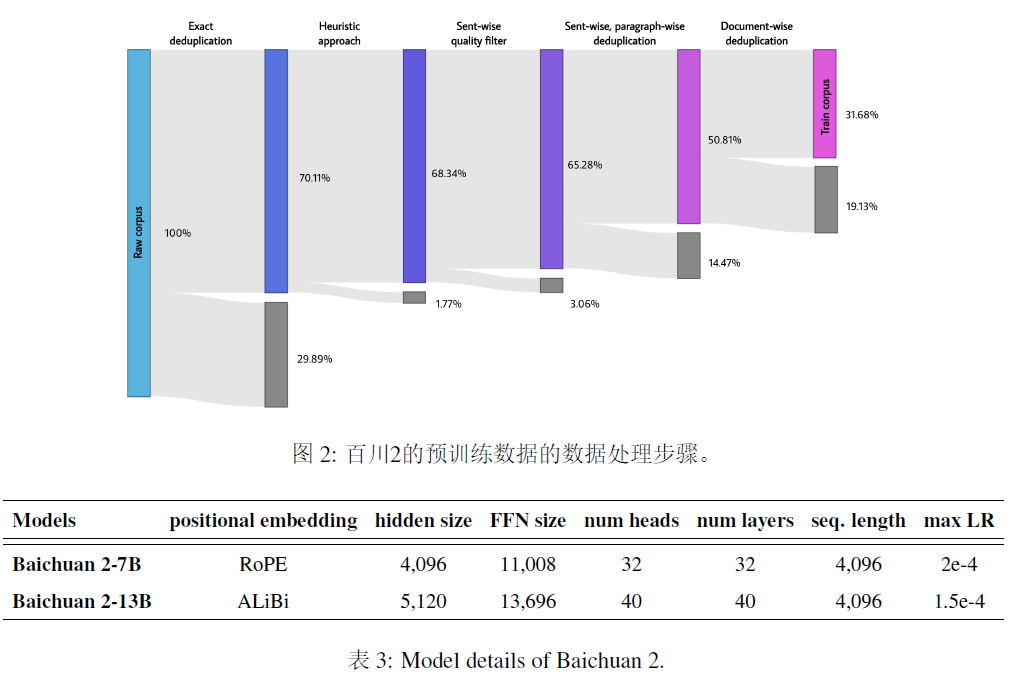
数据处理:关注数据频率和质量。数据频率依赖于聚类和去重,构建了一个支持LSH型特征和稠密embedding特征的大规模去重和聚类系统,单个文档、段落和句子被去重评分,这些评分然后用于预训练中的数据采样。
2.3 Tokenizer
分词器需要平衡两个关键因素:高压缩率以实现高效的推理,并适当大小的词汇表以确保每个词embedding的充
1.introduction
baichuan2基于2.6万亿个token进行训练。
2.pre-training
2.1 pre-training data
数据处理:关注数据频率和质量。数据频率依赖于聚类和去重,构建了一个支持LSH型特征和稠密embedding特征的大规模去重和聚类系统,单个文档、段落和句子被去重评分,这些评分然后用于预训练中的数据采样。
2.3 Tokenizer
分词器需要平衡两个关键因素:高压缩率以实现高效的推理,并适当大小的词汇表以确保每个词embedding的充

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























