







 超级会员免费看
超级会员免费看
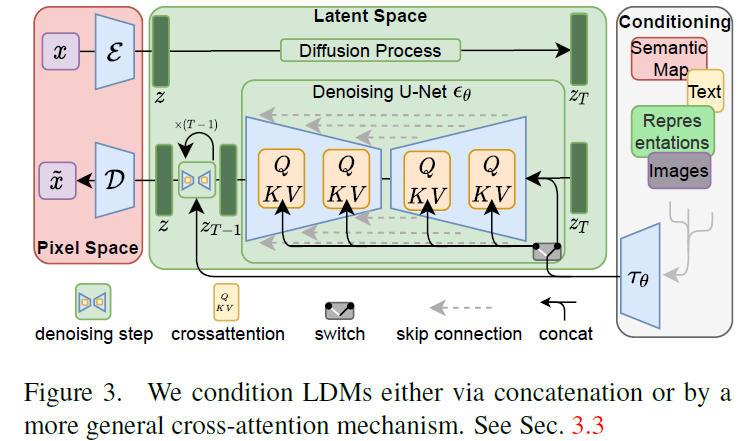
conditioning怎么往sd中添加,一般有三种,一种是直接和latent拼一下,另外很多是在unet结构Spatialtransformers上加,和文本特征一样,通过cross-attention往unet上加,这里还需要注意一点,在文本嵌入时,q是可学习的,k和v都是文本embedding。第三种就是类似controlnet这种,adapter设计。
1.sd img2img
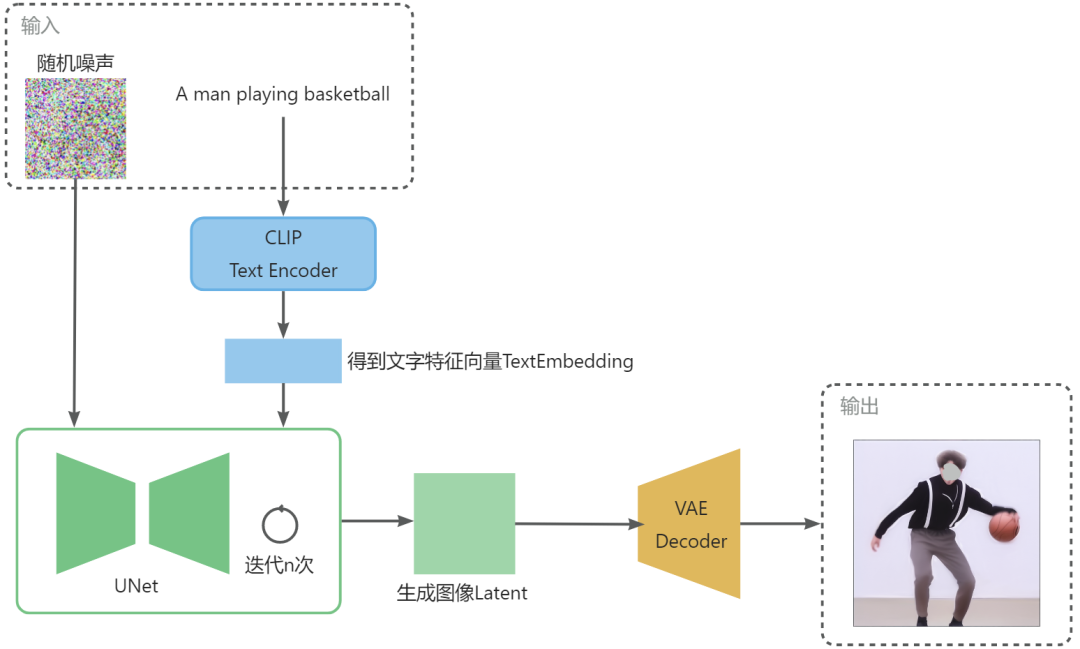
sd的img2img的图像输入是通过VAE将图像转成image latent和latent一起拼的,将512x512的图转成64x64.
init_latent = sd_model.get_first_stage_encoding(sd_model.encode_first_stage(image))
image_conditioning = img2img_image_conditioning(image, init_latent, image_mask)1.ip-adapter

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1253
1253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









