







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
来SZ已经两个月了,这是我加入训练营的第四周,最近几天在写综述和折腾新课题的设计,这一期有点摸鱼了。菲姐发训练视频时说到,“努力只能及格,拼命才能优秀”,竞技体育如此,学业又何尝不是呢。读博的日子是孤独且枯燥的,但每天都告诉自己时间很宝贵,再黑暗再绝望的时候,只要咬咬牙挺过去就好了。山重水复疑无路,柳暗花明又一村。
实验目的:
- 要求:训练过程中保存效果最好的模型参数,加载最佳模型参数识别本地的一张图片,调整网络结构使测试集accuracy到达88%(重点)
- 拔高:调整模型参数并观察测试集的准确率变化,尝试设置动态学习率,测试集accuracy到达90%
实验环境:
- 语言环境:python 3.8
- 编译器:pycharm
- 深度学习环境:
- torch ==2.2.2
- torchvision ==0.17.2
- cpuonly
- 数据:dd获取
实验流程:
一、前期准备
1. 导入"APP",设置 GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
🪧代码输出
device(type='cpu')
2. 加载数据
import os,PIL,random,pathlib
data_dir = './monkeypox_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
classeNames
🪧代码输出
['Monkeypox', 'Others']
total_datadir = './monkeypox_photos/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
🪧代码输出
Dataset ImageFolder
Number of datapoints: 2142
Root location: ./monkeypox_photos/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx # 存储了数据集类别和对应索引的字典
🪧代码输出
{'Monkeypox': 0, 'Others': 1}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
train_size, test_size
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
🪧代码输出
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
torch.utils.data.DataLoader 是 PyTorch 中用于加载和管理数据的一个实用工具类。它允许你以小批次的方式迭代你的数据集,这对于训练神经网络和其他机器学习任务非常有用。DataLoader 构造函数接受多个参数,下面是一些常用的参数及其解释:
- dataset(必需参数):这是你的数据集对象,通常是 torch.utils.data.Dataset 的子类,它包含了你的数据样本
- batch_size(可选参数):指定每个小批次中包含的样本数。默认值为 1
- shuffle(可选参数):如果设置为 True,则在每个 epoch 开始时对数据进行洗牌,以随机打乱样本的顺序。这对于训练数据的随机性很重要,以避免模型学习到数据的顺序性。默认值为 False
- num_workers(可选参数):用于数据加载的子进程数量。通常,将其设置为大于 0 的值可以加快数据加载速度,特别是当数据集很大时。默认值为 0,表示在主进程中加载数据
- pin_memory(可选参数):如果设置为 True,则数据加载到 GPU 时会将数据存储在 CUDA 的锁页内存中,这可以加速数据传输到 GPU。默认值为 False
- drop_last(可选参数):如果设置为 True,则在最后一个小批次可能包含样本数小于 batch_size 时,丢弃该小批次。这在某些情况下很有用,以确保所有小批次具有相同的大小。默认值为 False
- timeout(可选参数):如果设置为正整数,它定义了每个子进程在等待数据加载器传递数据时的超时时间(以秒为单位)。这可以用于避免子进程卡住的情况。默认值为 0,表示没有超时限制
- worker_init_fn(可选参数):一个可选的函数,用于初始化每个子进程的状态。这对于设置每个子进程的随机种子或其他初始化操作很有用
二、构建简单的CNN网络
网络结构图: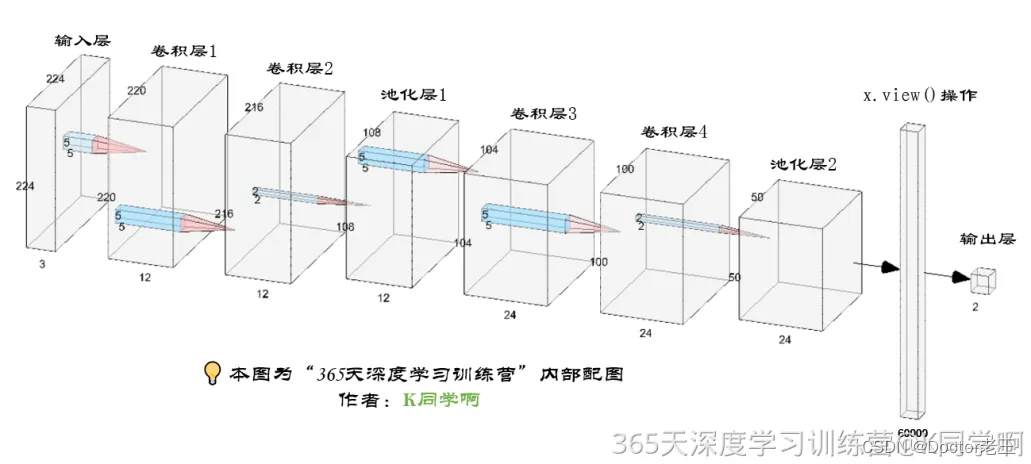
一般的CNN网络是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model
🪧代码输出
Using cpu device
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=2, bias=True)
)
三、训练模型
1. 设置超参数
损失函数(nn.CrossEntropyLoss()),学习率(1e-2),优化器(torch.optim.SGD)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2. 编写训练函数
使用反向传播计算梯度,再通过优化器更新
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
3. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4. 正式训练
epochs = 20
# 分别初始化用于存储训练过程中每一轮训练集的损失值、准确率,以及测试集的损失值、准确率的空列表
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
经过20轮训练,得到结果如下:
🪧代码输出
Epoch: 1, Train_acc:61.8%, Train_loss:0.668, Test_acc:70.2%,Test_loss:0.586
Epoch: 2, Train_acc:70.2%, Train_loss:0.562, Test_acc:73.4%,Test_loss:0.586
Epoch: 3, Train_acc:75.2%, Train_loss:0.513, Test_acc:74.4%,Test_loss:0.516
Epoch: 4, Train_acc:78.3%, Train_loss:0.474, Test_acc:77.2%,Test_loss:0.513
Epoch: 5, Train_acc:81.4%, Train_loss:0.451, Test_acc:74.8%,Test_loss:0.491
Epoch: 6, Train_acc:82.0%, Train_loss:0.431, Test_acc:78.1%,Test_loss:0.467
Epoch: 7, Train_acc:84.9%, Train_loss:0.396, Test_acc:72.5%,Test_loss:0.513
Epoch: 8, Train_acc:84.8%, Train_loss:0.388, Test_acc:78.3%,Test_loss:0.475
Epoch: 9, Train_acc:86.5%, Train_loss:0.369, Test_acc:77.6%,Test_loss:0.458
Epoch:10, Train_acc:87.9%, Train_loss:0.352, Test_acc:80.0%,Test_loss:0.432
Epoch:11, Train_acc:89.1%, Train_loss:0.337, Test_acc:81.1%,Test_loss:0.436
Epoch:12, Train_acc:88.8%, Train_loss:0.321, Test_acc:79.7%,Test_loss:0.425
Epoch:13, Train_acc:90.3%, Train_loss:0.312, Test_acc:80.4%,Test_loss:0.426
Epoch:14, Train_acc:90.7%, Train_loss:0.298, Test_acc:80.4%,Test_loss:0.408
Epoch:15, Train_acc:91.2%, Train_loss:0.293, Test_acc:80.2%,Test_loss:0.418
Epoch:16, Train_acc:91.2%, Train_loss:0.283, Test_acc:82.1%,Test_loss:0.418
Epoch:17, Train_acc:92.4%, Train_loss:0.274, Test_acc:82.8%,Test_loss:0.421
Epoch:18, Train_acc:92.3%, Train_loss:0.266, Test_acc:81.8%,Test_loss:0.418
Epoch:19, Train_acc:92.7%, Train_loss:0.262, Test_acc:82.5%,Test_loss:0.427
Epoch:20, Train_acc:93.3%, Train_loss:0.250, Test_acc:80.9%,Test_loss:0.400
Done
四、结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
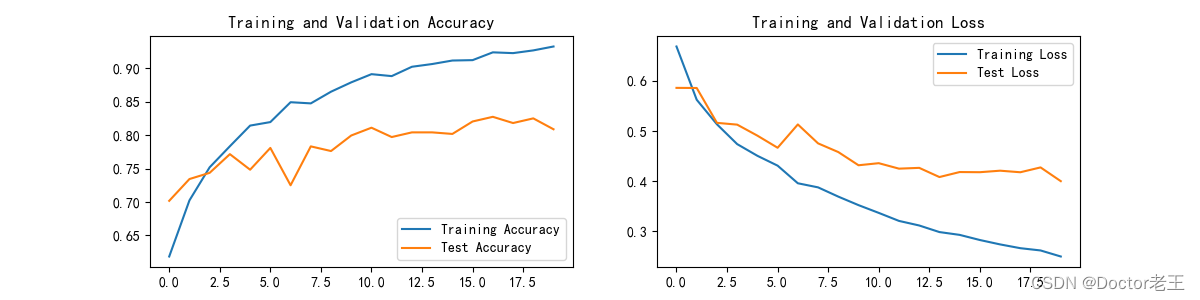 分析结果:
分析结果:
- 随着 epoch 的增加,训练准确率(Train_acc)总体上呈现上升趋势,从最初的 61.8%逐步提升到 93.3%,表明模型在训练数据上的学习效果越来越好。
- 训练损失(Train_loss)持续下降,从 0.668 降至 0.250,这意味着模型在训练过程中对数据的拟合能力逐渐增强。
- 测试准确率(Test_acc)在波动中上升,从 70.2%提升到 80.9%,虽然中间有些波动,但整体上也有所提高。
- 测试损失(Test_loss)较为稳定,围绕在 0.5 左右波动。
综合来看:
- 整体上模型的性能在不断提升,训练和测试结果都显示出积极的趋势。
- 不过,测试准确率的波动以及相对训练准确率提升较为缓慢,可能暗示存在一些过拟合的风险或者模型还有进一步优化的空间。例如,可以尝试调整模型的超参数、增加数据量、使用正则化等方法来改善模型性能。
例如,在图像分类任务中,如果一开始模型的训练准确率和测试准确率都比较低,随着训练的进行,两者都逐渐上升,就像这里的数据表现,说明模型逐渐学习到了图像的特征和分类规则。而如果测试准确率在某个阶段开始下降,可能就是过拟合开始出现的信号。同样,在自然语言处理任务中,也可以通过类似的训练和测试指标的变化来评估模型的性能和调整模型的训练策略。
2. 指定图片进行预测
-
torch.squeeze:对数据的维度进行压缩,去掉维数为1的的维度
-
torch.unsqueeze:对数据维度进行扩充。给指定位置加上维数为一的维度
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
# plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_,pred = torch.max(output,1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./monkeypox_photos/Monkeypox/M01_01_09.jpg',
model=model,
transform=train_transforms,
classes=classes)
🪧代码输出
预测结果是:Monkeypox
五、提高测试集accuracy
更改优化器:
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
通过更改优化器,增加dropout层,测试集accuracy最高可达88.8%:
🪧代码输出
Epoch: 1, Train_acc:87.1%, Train_loss:0.319, Test_acc:83.0%,Test_loss:0.369
Epoch: 2, Train_acc:94.6%, Train_loss:0.189, Test_acc:82.3%,Test_loss:0.381
Epoch: 3, Train_acc:96.4%, Train_loss:0.138, Test_acc:85.8%,Test_loss:0.337
Epoch: 4, Train_acc:98.2%, Train_loss:0.095, Test_acc:86.0%,Test_loss:0.323
Epoch: 5, Train_acc:97.1%, Train_loss:0.099, Test_acc:86.0%,Test_loss:0.341
Epoch: 6, Train_acc:99.0%, Train_loss:0.062, Test_acc:86.5%,Test_loss:0.381
Epoch: 7, Train_acc:99.6%, Train_loss:0.041, Test_acc:88.8%,Test_loss:0.336
Epoch: 8, Train_acc:99.3%, Train_loss:0.039, Test_acc:86.0%,Test_loss:0.366
Epoch: 9, Train_acc:99.7%, Train_loss:0.031, Test_acc:86.5%,Test_loss:0.403
Epoch:10, Train_acc:99.8%, Train_loss:0.025, Test_acc:87.9%,Test_loss:0.338
Epoch:11, Train_acc:99.8%, Train_loss:0.022, Test_acc:87.9%,Test_loss:0.342
Epoch:12, Train_acc:99.9%, Train_loss:0.017, Test_acc:85.3%,Test_loss:0.414
Epoch:13, Train_acc:99.8%, Train_loss:0.019, Test_acc:86.2%,Test_loss:0.379
Epoch:14, Train_acc:98.5%, Train_loss:0.052, Test_acc:87.2%,Test_loss:0.369
Epoch:15, Train_acc:98.2%, Train_loss:0.053, Test_acc:83.9%,Test_loss:0.662
Epoch:16, Train_acc:99.6%, Train_loss:0.022, Test_acc:87.6%,Test_loss:0.403
Epoch:17, Train_acc:99.7%, Train_loss:0.016, Test_acc:87.4%,Test_loss:0.414
Epoch:18, Train_acc:100.0%, Train_loss:0.008, Test_acc:86.9%,Test_loss:0.406
Epoch:19, Train_acc:100.0%, Train_loss:0.006, Test_acc:87.4%,Test_loss:0.432
Epoch:20, Train_acc:99.9%, Train_loss:0.007, Test_acc:88.1%,Test_loss:0.393
Done
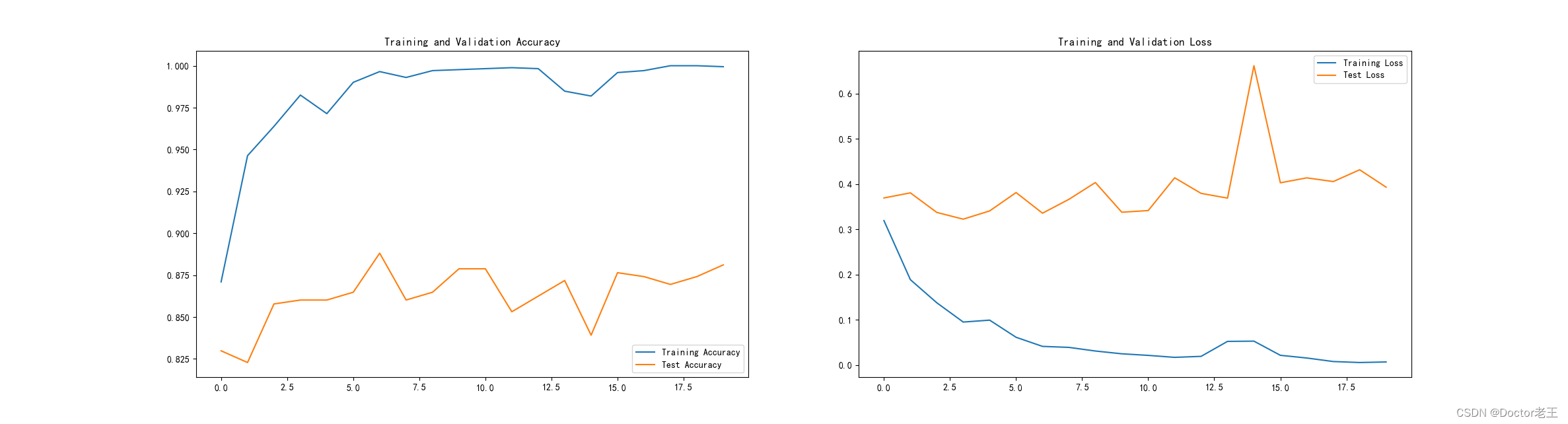
六、保存并加载模型
# 模型保存
PATH = './monkeypox_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
🪧代码输出
<All keys matched successfully>
保存最佳模型:
best_acc = 0
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
七、总结
- 训练过程中保存效果最好的模型参数(完成✅,通过判断测试集最高acc)
- 加载最佳模型参数识别本地的一张图片(完成✅)
- 调整网络结构使测试集accuracy到达88%(重点)(完成✅,通过更改优化器实现)
🧗♂️拔高:
- 调整模型参数并观察测试集的准确率变化(完成✅)
- 尝试设置动态学习率(未完成)
- 测试集accuracy到达90%(未完成,最高只有88.8%)
本周的代码相对于上周增加了指定图片预测与保存并加载模型这个两个模块,本次实验通过跑通代码熟悉了这个两知识点,并通过学习其他同学的帖子进行了拔高部分的练习,但是未能完成测试集accuracy达到90%以及设置动态学习率,还有待进一步探究。同时通过更改优化器提高测试集accuracy体会到了模型的搭建是深度学习的重点。
调整网络结构:
- 确保数据预处理和加载的正确性
- 调整网络结构,增加网络深度:增加卷积层和全连接层的数量。增加网络宽度:增加卷积核的数量或者全连接层的神经元数量。使用更大的卷积核或者池化核。调整激活函数:尝试不同的激活函数,如ReLU、LeakyReLU等。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









