







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
刚刚过去的周末举行了 X9 高校赛艇联赛,我倍感幸运,在大叔的年纪竟被教练选入了混八队伍。虽说结果不太理想,甚至为此略感失落,不过也收获了宝贵的比赛经验。接触赛艇一个多月以来,我深感这是一项既能减肥又颇为优雅的运动,它同时还是团队、技巧与力量的完美结合,散发着浓厚的艺术魅力。两站比赛已经成为过去时,下个月还有第三站在等着我们。依旧用朋友圈的那条动态来激励自己,“Go big or go home!!!”。未来一个月会很苦,需要兼顾训练与学习,但我坚信这段经历会给我打下深刻的烙印!
言归正传,这是我参加《365天深度学习训练营》的第二周,与此同时,最近我还在学习MMDetection做实例分割,跑通Demo之后,加上这回P2的顺利实施,我已经开始逐步建立起信心。本期blog我主要通过注释每段代码来强化理解与记忆,那么接下来,就请随我一同回顾此次旅程吧!
此次实验为机器学习经典案例:基于CIFAR10数据集的彩色图片识别实验
实验目的:
- 学习如何编写一个完整的深度学习程序
- 学会推导卷积层与池化层的计算过程
- 重点是学会基于torch.nn构建CNN网络
实验环境:
- 语言环境:python 3.8
- 编译器:pycharm
- 深度学习环境:
- torch ==2.2.2
- torchvision ==0.17.2
- cpuonly
实验流程:
一、前期准备
1. 导入"APP",设置 GPU
# 导入PyTorch库,这是一个广泛用于深度学习的框架
# 将PyTorch的神经网络模块导入,并简称为nn(neural network),方便后续使用其中的各种神经网络层等
# 导入matplotlib的绘图模块,用于数据可视化,比如绘制图形等
# torchvision通常用于导入与计算机视觉相关的功能和数据集
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
# 设置硬件设备,如果有GPU则使用,没有则使用cpu
# 如果有则将device设置为"cuda",表示将在GPU上进行计算,这样可以加速深度学习模型的训练和推理等操作
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
🪧代码输出
device(type='cpu')
2. 加载数据
- 通过torchvision中的dataset下载CIFAR10数据集,并划分好训练集与测试集
# torchvision.datasets.CIFAR10:调用PyTorch中用于加载 CIFAR10 数据集的类
# 'data':指定数据集存储的路径
# train=True:训练集
# transform=torchvision.transforms.ToTensor():将数据类型转换为张量(Tensor)格式
# download=True:如果数据集在指定路径下不存在,则自动下载该数据集
train_ds = torchvision.datasets.CIFAR10('data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_ds = torchvision.datasets.CIFAR10('data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
🪧代码输出
Files already downloaded and verified
Files already downloaded and verified
- 通过DataLoader加载数据,并设置好基本的batch_size
# batch_size:定义每一批数据的大小
# torch.utils.data.DataLoader:创建一个数据加载器
# train_ds:训练数据集
# batch_size=batch_size:使用前面定义的批量大小
# shuffle=True:在每个训练周期开始前对训练数据进行随机打乱,有助于提高训练效果,避免模型学习到数据的特定顺序
# 测试集通常不需要打乱数据顺序
# 这样就创建好了训练集和测试集的数据加载器,以便在训练和评估模型时能够以指定的批量大小方便地获取数据
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size)
# 取一个批次查看数据格式
# 数据的shape为:[batch_size, channel, height, weight]
# 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度
imgs, labels = next(iter(train_dl))
imgs.shape
🪧代码输出
torch.Size([32, 3, 32, 32])
3. 数据可视化
# 导入numpy库,用于数组操作等
# 创建一个新的图形,指定图形的大小为宽20、高5(英寸)
# 遍历一个名为imgs的数据集中的前20个图像
import numpy as np
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):
# 维度缩减:将图像数据转换为numpy数组,并进行维度变换,通常是将通道维度调整到最后
# 将整个图形区域划分成2行10列的子图布局,并选择当前要绘制的是第i+1个子图
# 在当前子图中显示转换后的图像,使用指定的颜色映射(这里是二值颜色映射)
# 关闭坐标轴的显示
npimg = imgs.numpy().transpose((1, 2, 0))
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')
#plt.show() 如果使用的是Pycharm编译器,加上这行代码

二、构建简单的CNN网络
CNN(Convolutional Neural Network,卷积神经网络)是一种深度神经网络模型,可以把CNN网络想象成一个特别厉害的“图像侦探”。它具有以下特点和优势:
- 局部感知:通过卷积操作能够提取局部特征。看一张大图片的时候,不是一下子看整张图,而是一小块一小块地去看,这样它就能更细致地发现每个小部分的特点。
- 权值共享:减少了参数数量,降低了模型复杂度。就像是它有一套通用的规则,不管看图片的哪个部分,都可以用这套规则来分析,不用为每个小地方都单独设定规则,大大减少了麻烦。
- 多层结构:可以包含多个卷积层和池化层,逐步提取更高级的特征。这些层就像是一个个关卡,前面的卷积层和池化层负责把图片的各种特征一点一点地提取出来,从简单的特征到越来越复杂的特征。经过这么多层的处理后,它就能越来越清楚地知道这个图片到底是什么。
CNN 在图像识别、图像分类、目标检测等计算机视觉任务中取得了巨大的成功。例如,在识别图像中的物体、场景分类等方面表现出色。它能够自动从大量的数据中学习到有效的特征表示,从而提高对各种图像相关任务的处理能力。一些知名的 CNN 模型包括 AlexNet、VGGNet、ResNet 等。
比如说,我们让它去识别猫的图片。它通过这些操作就能从图片里找出那些能代表猫的特征,比如猫的耳朵形状、眼睛样子、身体轮廓等等。这样,它就能准确地说这张图片是不是猫啦。
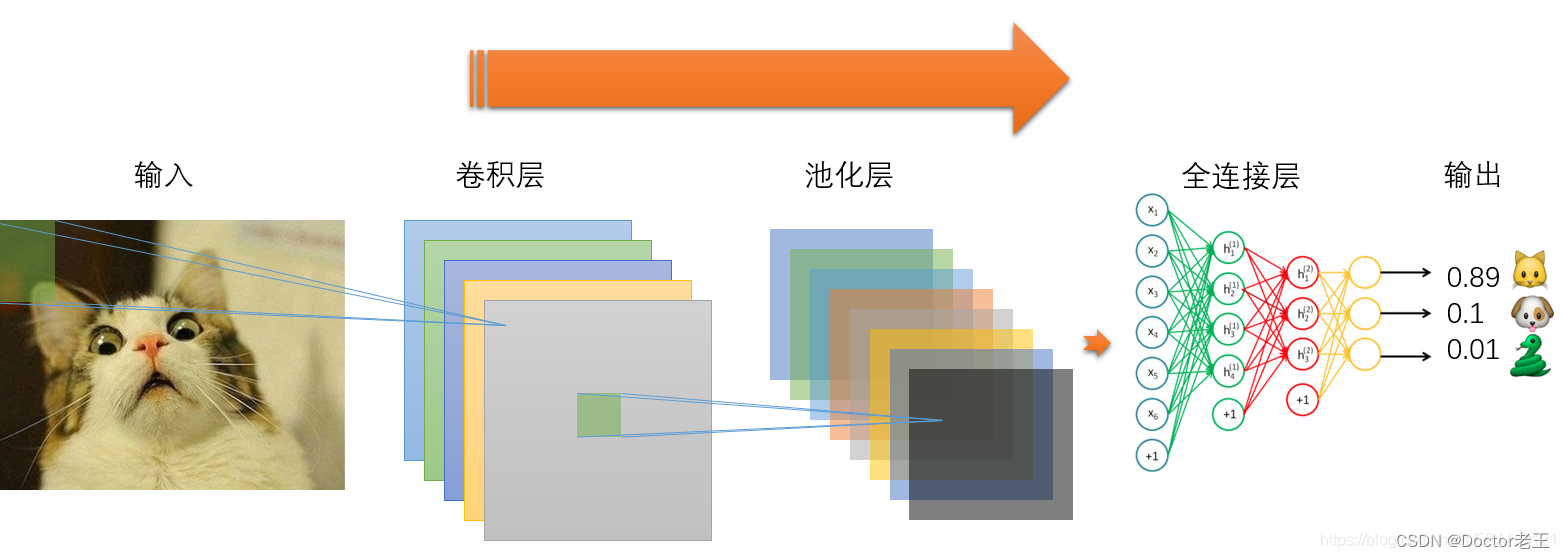
一般的CNN网络是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
# 导入PyTorch的函数模块并简称为F
# 定义了要分类的类别数
# 定义了一个名为Model的类,继承自nn.Module
import torch.nn.functional as F
num_classes = 10
class Model(nn.Module):
def __init__(self):
super().__init__()
# 特征提取网络:定义了一系列卷积层和池化层用于特征提取
self.conv1 = nn.Conv2d(3, 64, kernel_size=3) # 第一层卷积,卷积核大小为3*3
self.pool1 = nn.MaxPool2d(kernel_size=2) # 设置池化层,池化核大小为2*2
self.conv2 = nn.Conv2d(64, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3) # 第二层卷积,卷积核大小为3*3
self.pool3 = nn.MaxPool2d(kernel_size=2)
# 分类网络:全连接层用于最终的分类
self.fc1 = nn.Linear(512, 256)
self.fc2 = nn.Linear(256, num_classes)
# 定义了前向传播的过程:次经过卷积、激活函数(ReLU)和池化操作进行特征提取
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
# 将特征图展平为一维向量
x = torch.flatten(x, start_dim=1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
加载模型并打印
from torchinfo import summary
# 将模型转移到GPU中(我们模型运行均在GPU中进行)
model = Model().to(device)
summary(model)
🪧代码输出
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Model --
├─Conv2d: 1-1 1,792
├─MaxPool2d: 1-2 --
├─Conv2d: 1-3 36,928
├─MaxPool2d: 1-4 --
├─Conv2d: 1-5 73,856
├─MaxPool2d: 1-6 --
├─Linear: 1-7 131,328
├─Linear: 1-8 2,570
=================================================================
Total params: 246,474
Trainable params: 246,474
Non-trainable params: 0
=================================================================
三、训练模型
1. 设置超参数
损失函数(nn.CrossEntropyLoss()):
可以把它想象成一个“裁判”,它的任务就是来评判模型预测得对不对。比如我们是要给图片分类,模型给出了它的预测结果,这个损失函数就去比较模型的预测和实际的正确答案之间差了多少。如果差得很多,那损失就大;如果比较接近,损失就小。模型在训练过程中就是要努力让这个损失变得越来越小,这样就说明它预测得越来越准。
学习率(1e-2):
学习率就像是模型走步的“大小”。如果学习率是 0.01(1e-2),那就表示模型每次根据计算出来的信息去调整自己参数的时候,迈的步子大小是 0.01。学习率如果太大了,模型可能会一下子迈得太远,容易走过头或者不稳定;学习率太小呢,模型就会走得慢悠悠的,可能要花很多时间才能走到比较好的地方。
优化器(torch.optim.SGD):
这个就像是模型调整自己的“引导员”。它知道怎么根据损失函数告诉它的信息(也就是模型哪里做得不好),还有学习率这个步子大小,来指挥模型去调整那些参数,比如调整一些权重之类的,让模型变得越来越好,越来越能准确地完成任务。
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-2
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2. 编写训练函数
使用反向传播计算梯度,再通过优化器更新
# 定义了一个训练函数,接收数据加载器、模型、损失函数和优化器作为参数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
# 求平均训练准确率和训练损失,并返回这两个值
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
3. 编写测试函数
测试函数和训练函数大致相同,但不需要优化器与梯度传播
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0 # 初始化训练损失值和准确率为 0。
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4. 正式训练
# 定义训练的轮数
# 分别初始化用于存储训练过程中每一轮训练集的损失值、准确率,以及测试集的损失值、准确率的空列表
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train() # 将模型设置为训练模式
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval() # 将模型切换到评估模式
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 定义了一个输出模板
# 根据模板格式化并打印出每一轮的相关信息
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
经过10轮训练,得到结果如下:
🪧代码输出
Epoch: 1, Train_acc:15.4%, Train_loss:2.272, Test_acc:22.0%,Test_loss:2.097
Epoch: 2, Train_acc:25.9%, Train_loss:1.993, Test_acc:31.1%,Test_loss:1.871
Epoch: 3, Train_acc:35.0%, Train_loss:1.775, Test_acc:40.4%,Test_loss:1.638
Epoch: 4, Train_acc:41.3%, Train_loss:1.612, Test_acc:42.6%,Test_loss:1.589
Epoch: 5, Train_acc:44.8%, Train_loss:1.512, Test_acc:46.4%,Test_loss:1.452
Epoch: 6, Train_acc:48.3%, Train_loss:1.426, Test_acc:48.7%,Test_loss:1.416
Epoch: 7, Train_acc:51.3%, Train_loss:1.347, Test_acc:52.7%,Test_loss:1.311
Epoch: 8, Train_acc:54.2%, Train_loss:1.281, Test_acc:54.9%,Test_loss:1.265
Epoch: 9, Train_acc:56.9%, Train_loss:1.220, Test_acc:54.8%,Test_loss:1.257
Epoch:10, Train_acc:59.0%, Train_loss:1.164, Test_acc:59.0%,Test_loss:1.171
Done
四、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

由数据结合图表可以看到模型训练过程中每一轮的统计信息:
Epoch表示轮数Train_acc是训练集上的准确率,从第一轮的 15.4%逐步提升到最后一轮的 59.0%,整体呈上升趋势,说明模型在训练集上的学习效果在不断改善Train_loss是训练集上的损失值,从 2.272 逐渐下降到 1.164,表明模型在训练过程中对训练数据的拟合越来越好Test_acc是测试集上的准确率,在前几轮有较大提升,后面虽有波动但总体也有所上升Test_loss是测试集上的损失值,整体也呈现下降趋势,但存在一定波动
总体来说,从这些信息可以观察到模型在训练过程中的大致性能变化,训练集上的准确率和损失值表现出模型在不断学习和改进,而测试集上的结果则反映了模型的泛化能力。不过,仅根据这些信息还不能全面准确地评估模型的性能,可能还需要结合其他指标和更深入的分析。
五、总结
- 通过本期实验,再次复习并强化了深度学习的模型训练套路,为日后自主编写完整的深度学习程序打下基础
- 数据收集:收集用于训练和测试模型的数据集
- 数据预处理:清洗数据,进行归一化、标准化,以及数据增强等操作
- 定义模型架构:根据问题的性质设计神经网络的结构,选择合适的层和激活函数
- 编译模型:配置模型的损失函数、优化器和评估指标
- 训练模型:使用训练数据对模型进行训练,调整模型参数
- 评估模型:使用验证集或测试集评估模型的性能
- 模型调优:根据评估结果对模型进行调整,包括调整网络结构、超参数等,“调参大法好”
- 应用模型:将训练好的模型应用于实际问题,进行预测或分类
- 推导卷积层与池化层的计算过程
卷积层的目的是提取图像的特征。它通过使用卷积核(或滤波器)在输入图像上滑动来实现这一点。
-
输入:
- 输入图像 ( I ),大小为 ( H \times W \times C )(高度 x 宽度 x 通道数)
- 卷积核 ( K ),大小为 ( F \times F \times C )(卷积核的尺寸 x 通道数)
-
参数:
- 步长(Stride): ( S )
- 填充(Padding): ( P )
-
输出:
- 特征图 ( O ),大小为 ( O_H \times O_W \times N )(输出高度 x 输出宽度 x 卷积核数量)
-
计算过程:
- 计算输出特征图的大小:
[ O_H = \frac{H + 2P - F}{S} + 1 ]
[ O_W = \frac{W + 2P - F}{S} + 1 ]
其中 ( H ) 和 ( W ) 是输入图像的高度和宽度。 - 对于每个卷积核:
- 初始化输出特征图 ( O ) 为零矩阵
- 将卷积核在输入图像上滑动,步长为 ( S ),填充 ( P )
- 对于每个位置,计算卷积核和输入图像的局部区域的点积
- 将结果累加到输出特征图的对应位置
- 对于所有卷积核,重复步骤2
- 计算输出特征图的大小:
池化层用于降低特征图的空间维度,从而减少参数数量和计算量,同时使特征检测更加鲁棒。
-
输入:
- 特征图 ( I ),大小为 ( H \times W \times C )(高度 x 宽度 x 通道数)
-
参数:
- 池化窗口大小 ( F )
- 步长 ( S )
-
输出:
- 池化后的特征图 ( P ),大小为 ( P_H \times P_W \times C )
-
计算过程:
-
计算池化后特征图的大小:
[ P_H = \frac{H - F}{S} + 1 ]
[ P_W = \frac{W - F}{S} + 1 ] -
对于每个通道:
- 初始化输出特征图 ( P ) 为零矩阵
- 将池化窗口在输入特征图上滑动,步长为 ( S )
- 对于每个位置,根据池化类型(最大池化或平均池化)计算池化窗口内的值:
- 最大池化:选择窗口内的最大值
- 平均池化:计算窗口内所有值的平均
-
对于所有通道,重复步骤2
-















 5596
5596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









