







本文是香港理工大学Kuaihua Zhang的一篇跟踪文章,发表在2014ECCV上,其突出贡献就是快,达到了350fps。传统的跟踪算法大多是利用时序信息即图像的前后帧的位置信息做预测,而本文则是融合目标的空间的信息,例如,跟踪过程中目标的背景信息是缓慢发生变化的,目标在背景中的空间位置与空间信息有很大关联,这就是文章中最大的创新点。其利用目标特征非常之简单(intensity and location of each pixel in proposal region),这也是速度之所以快的一个主要原因吧,下面对文章的主要内容做一下梳理,有不足之处希望得到大家的指点。
主要流程:
step1:根据第一帧的标注信息,构建空间上下文模型(spatio context model);
step2:用步骤1中的空间纹理模型更新下一帧的空间时序模型(spatio-temporal context model;
step3:用步骤2构建的空间时序上下文模型计算目标置信图,其中最大值即为本帧的目标位置。
step4:步骤3生成的confidence map用于计算一个目标尺度更新策略。
一,跟踪建模
本文把跟踪问题建模问计算目标位置置信图object location confidence map,该置信图是有目标空间位置的似然函数计算所得,
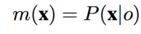
x 表示目标位置,o表示含有跟踪目标的场景
进一步分解该问题:
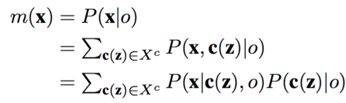
c(z)是o中的点z得上下文特征空间 c(z) = (I (z), z),主要包含空间灰度特征和空间位置特征。X^c表示o中c(z)的特征集。这样就把问题转化为了P(x|c(z),o)和P(c(z)|o)的条件概率乘积之和,下面主要建模的就是P(x|c(z),o)即目标位置关于空间上下文特征的条件概率。
1.1;空间上下文对目标位置建模:编码了空间上下文信息与目标位置之间的关系
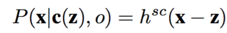
X:目标的location,Z:空间上下文位置的location,可以看出(X-Z)是非径相对称的,这样编码的信息集包含了上下文信息,也包括方向信息。
1.2;上下文先验概率模型:编码空间上下文信息的重要性
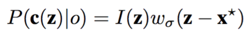
I(Z)表示Z出的灰度信息

可以理解为收到生物研究启发得到,离目标位置X^*近的位置Z有更大的权重,阿尔法是规则化系数,约束概率【0,1】,
1.3;置信图建模

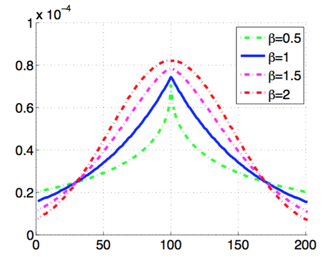
该模型考虑到前一帧目标位置,离X^*越近的位置置信度越大,文中解释shuo贝塔是为了解决目标位置模糊问题,选为1的时候效果最好。
二,快速学习空间上下文模型
该过程即为求解空间上下文与目标位置的条件概率模型h^sc(X-Z),
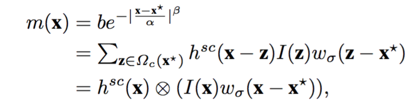

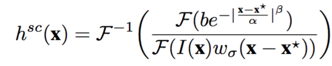
式1为前面公式的替换,式2为傅里叶变换的形式,目的是为了提高运算效率,式3通过逆傅里叶变换的形式解得h^sc(x).
三,跟踪过程
文中把跟踪过程简化为局部检测模型,在已知第一帧目标位置的情况下,建模空间上下文模型h^sc(x),该模型用于更新下一帧的上下文时序模型H^stc(x)
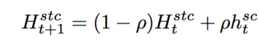
该更新策略是一种低通滤波的方式,目的是为了减低目标表观变化带来的噪声。
新一帧图像到来时首先选择建议目标区域(一般是上一帧目标位置的2倍搜索空间),然后计算置信图,通过寻找最大的置信图位置决定新一帧目标的位置(典型的判别模型)。
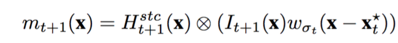
目标尺度更新策略:

四,小结
该算法有一下优点















 4856
4856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









