







pandas是什么?

是它吗?
。。。。很显然pandas没有这个家伙那么可爱。。。。
我们来看看pandas的官网是怎么来定义自己的:
pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language.
很显然,pandas是python的一个非常强大的数据分析库!
让我们来学习一下它吧!
1.pandas序列
import numpy as np
import pandas as pd
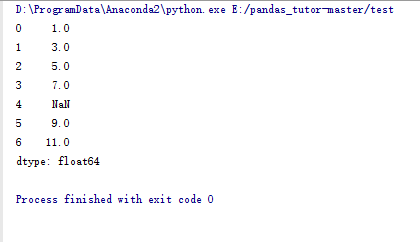
s_data = pd.Series([1,3,5,7,np.NaN,9,11])#pandas中生产序列的函数,类似于我们平时说的数组
print s_data
2.pandas数据结构DataFrame
import numpy as np
import pandas as pd
#以20170220为基点向后生产时间点
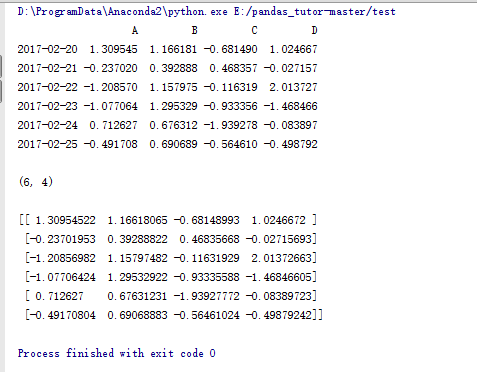
dates = pd.date_range('20170220',periods=6)
#DataFrame生成函数,行索引为时间点,列索引为ABCD
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
print data.shape
print
print data.values
3.DataFrame的一些操作(1)
import numpy as np
import pandas as pd
#设计一个字典
d_data = {'A':1,'B':pd.Timestamp('20170220'),'C':range(4),'D':np.arange(4)}
print d_data
#使用字典生成一个DataFrame
df_data = pd.DataFrame(d_data)
print df_data
#DataFrame中每一列的类型
print df_data.dtypes
#打印A列
print df_data.A
#打印B列
print df_data.B
#B列的类型
print type(df_data.B)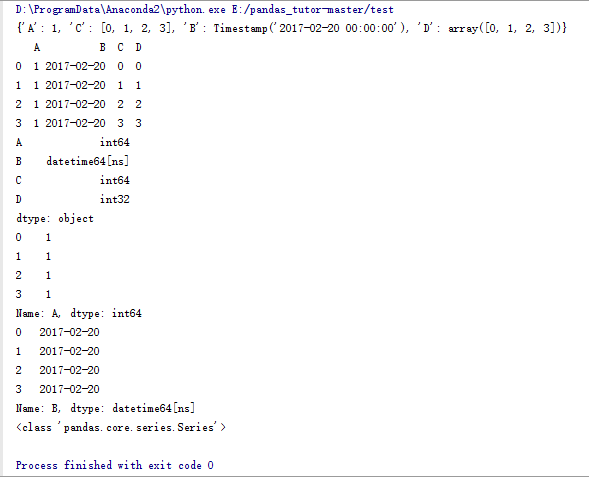
4.DataFrame的一些操作(2)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
#输出DataFrame头部数据,默认为前5行
print data.head()
#输出输出DataFrame第一行数据
print data.head(1)
#输出DataFrame尾部数据,默认为后5行
print data.tail()
#输出输出DataFrame最后一行数据
print data.tail(1)
#输出行索引
print data.index
#输出列索引
print data.columns
#输出DataFrame数据值
print data.values
#输出DataFrame详细信息
print data.describe()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









