







自旋锁用于处理器之间的互斥,适合保护很短的临界区,并且不允许在临界区睡眠。申请自旋锁的时候,如果自旋锁被其他处理器占有,本处理器自旋等待(也称为忙等待)。进程、软中断和硬中断都可以使用自旋锁。自旋锁是用在多处理器环境中的锁:如果内核控制路径发现自旋锁开着,就获取锁并继续执行,相反,如果内核控制路径发现锁由运行在另一个CPU上的内核控制路径锁着,就在周围“旋转”,直到锁被释放。这个“旋转”就是在忙等,这期间正在等待的内核控制路径除了浪费时间,无事可做。
spin_lock()的实现逻辑是,他执行的是一个 核内锁调度,核间自旋 的过程。多核处理器里面,任何一个核拿到了spinlock,这个核内的调度器就被锁住了,也就是这个核上的其他线程就不可能被调度执行了,核内是通过直接把调度器锁住来实现的。而核间才是真正自旋,因此spinlock中的”spin”在多核上才有意义。在单核情况下,spin_lock()就只是简单的去锁住调度器(preempt_disable,即禁掉内核抢占)。
spinlock适合锁住那些时间特别短且不睡眠的区间。这包括了两方面:
核1锁住临界区,核2上某线程在等待进入临界区,那么核2线程可以选择睡眠让其他线程运行,等核1线程退出临界区唤醒自己后再继续运行,也可以原地自旋忙等。如果一个临界区的时间很短,核1的线程很快执行完临界区了,这种情况下,核2线程与其睡眠进行两次上下文切换,还不如原地死等(while循环去检查一个变量的值),因为可能前者的开销更大。
spinlock的区间不能睡眠(不能调用可睡眠函数),这个好理解,因为不能调度了,而睡眠会引发调度。
在定义一个spinlock的时候要将锁初始化为“未锁住”的状态,确保第一次可以获得锁,定义一个自旋锁用DEFINE_SPINLOCK(x)宏即可,x是锁的名字。
虽然spinlock之后这个核不能进行调度了,但这个核上的中断还可能来,spin_lock挡不住中断,如果中断处理程序也要访问临界资源,则spinlock就起不到作用了。这时要用spinlock的修改版本spin_lock_irqsave,即既拿spinlock,也把这个核上的中断关掉。并且,这时线程中必须使用spin_lock_irqsave,要不然线程在spin_lock的时候被中断,中断处理中又调用spin_lock就死锁了。
多核的竞态有哪些情况呢?一个最严重的并发网:CPU0(有t1,t2两个线程和中断irq1)和CPU1(有t3,t4两个线程和中断irq2),这6个例程相互之间都可能产生竞态(访问相同的资源)。
解决竞态的简单做法:在线程里面统一调用spin_lock_irqsave,在中断里面统一调用spinlock。这样就避免了核内和核间的所有竞态,(核间的竞态是通过spin解决的,核内通过禁抢占和中断解决)。如果你知道只有线程才访问临界区,那线程里只用spinlock即可。
注:Linux 2.6.32以后就不支持中断嵌套了,因此中断里spinlock就好了,而老版内核版本,中断里面也要调用spin_lock_irqsave。
自旋锁的几个差别如下:
自旋锁
void spin_lock_irq(spinlock_t *lock);
与
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
区别在于:
spin_lock_irqsave在进入临界区前,保存当前中断寄存器flag状态,关中断,进入临界区,在退出临界区时,把保存的中断状态写回到中断寄存器。
spin_lock_irq在进入临界区前不保存中断状态,关中断,进入临界区,在退出临界区时,开中断。
spin_lock_irqsave锁返回时,中断状态不会被改变,调用spin_lock_irqsave前是开中断返回就开中断。
spin_lock_irq锁返回时,永远都是开中断,即使spin_lock_irq前是关中断
————————————————
版权声明:本文为CSDN博主「大白菜小萝卜」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lbo4031/article/details/8894830
Spinlock的目的是用来同步SMP中会被多个CPU同时存取的变量。在Linux中,普通的spinlock由于不带额外的语义,是用起来反而要非常小心。
在Linux kernel中执行的代码大体分normal和interrupt context两种。tasklet/softirq可以归 为normal因为他们可以进入等待;ne
sted interrupt是interrupt context的一种特殊情况,当然也是 interrupt context。Normal级别可以被interrupt抢断,in
terrupt会被另一个interrupt抢断,但不会被 normal中断。各个 interrupt之间没有优先级关系,只要有可能,每个interrupt都会被其他interrupt中断。
我们先考虑单CPU的情况。在这样情况下,不管在什么执行级别,我们只要简单地把CPU的中断关掉就可以达到独占处理的目的。
从这个角度来说,spinlock的实现简单地令人乍舌:cli/sti。只要这样,我们就关闭了preemption带来的复杂之门。
单CPU的情况很简单,多CPU就不那么简单了。单纯地关掉当前CPU的中断并不会给我们带来好运。当我们的代码存取一
个shared variable时,另一颗CPU随时会把数据改得面目全非。我们需要有手段通知它(或它们,你知道我的意思)——spinlock正为此 设。这个例子是我们的第一次尝试:
extern spinlock_t lock;
// ...
spin_lock(&lock);
// do something
spin_unlock(&lock);
他能正常工作吗?答案是有可能。在某些情况下,这段代码可以正常工作,但想一想会不会发生这样的事:
// in normal run level
extern spinlock_t lock;
// ...
spin_lock(&lock);
// do something
// interrupted by IRQ ...
// in IRQ
extern spinlock_t lock;
spin_lock(&lock);
喔,我们在normal级别下获得了一个spinlock,正当我们想做什么的时候,我们被interrupt打断了,CPU转而执行interrupt level的代码,它也想获得这个lock,于是“死锁”发生了!解决方法很简单,看看我们第二次尝试:
extern spinlock_t lock;
// ...
cli; // disable interrupt on current CPU
spin_lock(&lock);
// do something
spin_unlock(&lock);
sti; // enable interrupt on current CPU
在获得spinlock之前,我们先把当前CPU的中断禁止掉,然后获得一个lock;在释放lock之后再把中断打开。这样,我们就防止了死锁。事实上,Linux提供了一个更为快捷的方式来实现这个功能:
extern spinlock_t lock;
// ...
spin_lock_irq(&lock);
// do something
spin_unlock_irq(&lock);
如果没有nested interrupt,所有这一切都很好。加上nested interrupt,我们再来看看这个例子:
// code 1
extern spinlock_t lock1;
// ...
spin_lock_irq(&lock);
// do something
spin_unlock_irq(&lock);
// code 2
extern spinlock_t lock2;
// ...
spin_lock_irq(&lock2);
// do something
spin_unlock_irq(&lock2);
Code 1和code 2都可运行在interrupt下,我们很容易就可以想到这样的运行次序():
Code 1 Code 2
extern spinlock_t lock1;
// ...
spin_lock_irq(&lock1);
extern spinlock_t lock2;
// ...
spin_lock_irq(&lock1);
// do something
spin_unlock_irq(&lock2);
// do something
spin_unlock_irq(&lock1);
问题是在第二个spin_unlock_irq后这个CPU的中断已经被打开,“死锁”的问题又会回到我们身边!
解决方法是我们在每次关闭中断前纪录当前中断的状态,然后恢复它而不是直接把中断打开。
unsigned long flags;
local_irq_save(flags);
spin_lock(&lock);
// do something
spin_unlock(&lock);
local_irq_restore(flags);
Linux同样提供了更为简便的方式:
unsigned long flags;
spin_lock_irqsave(&lock, flags);
// do something
spin_unlock_irqrestore(&lock, flags);
总结:
如果被保护的共享资源只在进程上下文访问和软中断上下文访问,那么当在进程上下文访问共享资源时,可能被软中断打断,从而可能进入软中断上下文来对被保护 的共享资源访问,因此对于这种情况,对共享资源的访问必须使用spin_lock_bh和spin_unlock_bh来保护。
当然使用spin_lock_irq和spin_unlock_irq以及spin_lock_irqsave和 spin_unlock_irqrestore也可以,它们失效了本地硬中断,失效硬中断隐式地也失效了软中断。但是使用spin_lock_bh和 spin_unlock_bh是最恰当的,它比其他两个快。
如果被保护的共享资源只在进程上下文和tasklet或timer上下文访问,那么应该使用与上面情况相同的获得和释放锁的宏,因为tasklet和timer是用软中断实现的。
如果被保护的共享资源只在一个tasklet或timer上下文访问,那么不需要任何自旋锁保护,因为同一个tasklet或timer只能在一个 CPU上运行,即使是在SMP环境下也是如此。实际上tasklet在调用tasklet_schedule标记其需要被调度时已经把该tasklet绑 定到当前CPU,因此同一个tasklet决不可能同时在其他CPU上运行。
timer也是在其被使用add_timer添加到timer队列中时已经被帮定到当前CPU,所以同一个timer绝不可能运行在其他CPU上。当然同一个tasklet有两个实例同时运行在同一个CPU就更不可能了。
如果被保护的共享资源只在两个或多个tasklet或timer上下文访问,那么对共享资源的访问仅需要用spin_lock和 spin_unlock来保护,不必使用_bh版本,因为当tasklet或timer运行时,不可能有其他tasklet或timer在当前CPU上运 行。
如果被保护的共享资源只在一个软中断(tasklet和timer除外)上下文访问,那么这个共享资源需要用spin_lock和spin_unlock来保护,因为同样的软中断可以同时在不同的CPU上运行。
如果被保护的共享资源在两个或多个软中断上下文访问,那么这个共享资源当然更需要用spin_lock和spin_unlock来保护,不同的软中断能够同时在不同的CPU上运行。
如果被保护的共享资源在软中断(包括tasklet和timer)或进程上下文和硬中断上下文访问,那么在软中断或进程上下文访问期间,可能被硬中断 打断,从而进入硬中断上下文对共享资源进行访问,因此,在进程或软中断上下文需要使用spin_lock_irq和spin_unlock_irq来保护 对共享资源的访问。
而在中断处理句柄中使用什么版本,需依情况而定,如果只有一个中断处理句柄访问该共享资源,那么在中断处理句柄中仅需要spin_lock和spin_unlock来保护对共享资源的访问就可以了。
因为在执行中断处理句柄期间,不可能被同一CPU上的软中断或进程打断。但是如果有不同的中断处理句柄访问该共享资源,那么需要在中断处理句柄中使用spin_lock_irq和spin_unlock_irq来保护对共享资源的访问。
在使用spin_lock_irq和spin_unlock_irq的情况下,完全可以用spin_lock_irqsave和 spin_unlock_irqrestore取代,那具体应该使用哪一个也需要依情况而定,如果可以确信在对共享资源访问前中断是使能的,那么使用 spin_lock_irq更好一些。
因为它比spin_lock_irqsave要快一些,但是如果你不能确定是否中断使能,那么使用spin_lock_irqsave和spin_unlock_irqrestore更好,因为它将恢复访问共享资源前的中断标志而不是直接使能中断。
当然,有些情况下需要在访问共享资源时必须中断失效,而访问完后必须中断使能,这样的情形使用spin_lock_irq和spin_unlock_irq最好。
spin_lock用于阻止在不同CPU上的执行单元对共享资源的同时访问以及不同进程上下文互相抢占导致的对共享资源的非同步访问,而中断失效和软中断失效却是为了阻止在同一CPU上软中断或中断对共享资源的非同步访问
————————————————
版权声明:本文为CSDN博主「bob_fly1984」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bob_fly1984/article/details/38042763
实际场景
一、考虑下面的场景(内核抢占场景):
(1)进程A在某个系统调用过程中访问了共享资源 R (2)进程B在某个系统调用过程中也访问了共享资源 R 会不会造成冲突呢?假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态
二、再考虑下面的场景(中断上下文场景):
(1)运行在CPU0上的进程A在某个系统调用过程中访问了共享资源 R (2)运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源 R (3)外设P的中断handler中也会访问共享资源 R 在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本 CPU 上的中断联合使用。
三、再考虑下面的场景(底半部场景)
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就OK了
四、中断上下文之间的竞争
同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的softirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。tasklet更简单,因为同一种tasklet不会多个CPU上并发。
总结:
如果被保护的共享资源只在进程上下文访问和软中断上下文访问,那么当在进程上下文访问共享资源时,可能被软中断打断,从而可能进入软中断上下文来对被保护 的共享资源访问,因此对于这种情况,对共享资源的访问必须使用spin_lock_bh和spin_unlock_bh来保护。
当然使用spin_lock_irq和spin_unlock_irq以及spin_lock_irqsave和 spin_unlock_irqrestore也可以,它们失效了本地硬中断,失效硬中断隐式地也失效了软中断。但是使用spin_lock_bh和 spin_unlock_bh是最恰当的,它比其他两个快。
如果被保护的共享资源只在进程上下文和tasklet或timer上下文访问,那么应该使用与上面情况相同的获得和释放锁的宏,因为tasklet和timer是用软中断实现的。
如果被保护的共享资源只在一个tasklet或timer上下文访问,那么不需要任何自旋锁保护,因为同一个tasklet或timer只能在一个 CPU上运行,即使是在SMP环境下也是如此。实际上tasklet在调用tasklet_schedule标记其需要被调度时已经把该tasklet绑 定到当前CPU,因此同一个tasklet决不可能同时在其他CPU上运行。
timer也是在其被使用add_timer添加到timer队列中时已经被帮定到当前CPU,所以同一个timer绝不可能运行在其他CPU上。当然同一个tasklet有两个实例同时运行在同一个CPU就更不可能了。
如果被保护的共享资源只在两个或多个tasklet或timer上下文访问,那么对共享资源的访问仅需要用spin_lock和 spin_unlock来保护,不必使用_bh版本,因为当tasklet或timer运行时,不可能有其他tasklet或timer在当前CPU上运 行。
如果被保护的共享资源只在一个软中断(tasklet和timer除外)上下文访问,那么这个共享资源需要用spin_lock和spin_unlock来保护,因为同样的软中断可以同时在不同的CPU上运行。
如果被保护的共享资源在两个或多个软中断上下文访问,那么这个共享资源当然更需要用spin_lock和spin_unlock来保护,不同的软中断能够同时在不同的CPU上运行。
如果被保护的共享资源在软中断(包括tasklet和timer)或进程上下文和硬中断上下文访问,那么在软中断或进程上下文访问期间,可能被硬中断 打断,从而进入硬中断上下文对共享资源进行访问,因此,在进程或软中断上下文需要使用spin_lock_irq和spin_unlock_irq来保护 对共享资源的访问。
而在中断处理句柄中使用什么版本,需依情况而定,如果只有一个中断处理句柄访问该共享资源,那么在中断处理句柄中仅需要spin_lock和spin_unlock来保护对共享资源的访问就可以了。
因为在执行中断处理句柄期间,不可能被同一CPU上的软中断或进程打断。但是如果有不同的中断处理句柄访问该共享资源,那么需要在中断处理句柄中使用spin_lock_irq和spin_unlock_irq来保护对共享资源的访问。
在使用spin_lock_irq和spin_unlock_irq的情况下,完全可以用spin_lock_irqsave和 spin_unlock_irqrestore取代,那具体应该使用哪一个也需要依情况而定,如果可以确信在对共享资源访问前中断是使能的,那么使用 spin_lock_irq更好一些。
因为它比spin_lock_irqsave要快一些,但是如果你不能确定是否中断使能,那么使用spin_lock_irqsave和spin_unlock_irqrestore更好,因为它将恢复访问共享资源前的中断标志而不是直接使能中断。
当然,有些情况下需要在访问共享资源时必须中断失效,而访问完后必须中断使能,这样的情形使用spin_lock_irq和spin_unlock_irq最好。
spin_lock用于阻止在不同CPU上的执行单元对共享资源的同时访问以及不同进程上下文互相抢占导致的对共享资源的非同步访问,而中断失效和软中断失效却是为了阻止在同一CPU上软中断或中断对共享资源的非同步访问
————————————————
版权声明:本文为CSDN博主「bob_fly1984」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bob_fly1984/article/details/38042763
1、spin lock的特点
我们可以总结spin lock的特点如下:
(1)spin lock是一种死等的锁机制。当发生访问资源冲突的时候,可以有两个选择:一个是死等,一个是挂起当前进程,调度其他进程执行。spin lock是一种死等的机制,当前的执行thread会不断的重新尝试直到获取锁进入临界区。
(2)只允许一个thread进入。semaphore可以允许多个thread进入,spin lock不行,一次只能有一个thread获取锁并进入临界区,其他的thread都是在门口不断的尝试。
(3)执行时间短。由于spin lock死等这种特性,因此它使用在那些代码不是非常复杂的临界区(当然也不能太简单,否则使用原子操作或者其他适用简单场景的同步机制就OK了),如果临界区执行时间太长,那么不断在临界区门口“死等”的那些thread是多么的浪费CPU啊(当然,现代CPU的设计都会考虑同步原语的实现,例如ARM提供了WFE和SEV这样的类似指令,避免CPU进入busy loop的悲惨境地)
(4)可以在中断上下文执行。由于不睡眠,因此spin lock可以在中断上下文中适用。
2、 场景分析
对于spin lock,其保护的资源可能来自多个CPU CORE上的进程上下文和中断上下文的中的访问,其中,进程上下文包括:用户进程通过系统调用访问,内核线程直接访问,来自workqueue中work function的访问(本质上也是内核线程)。中断上下文包括:HW interrupt context(中断handler)、软中断上下文(soft irq,当然由于各种原因,该softirq被推迟到softirqd的内核线程中执行的时候就不属于这个场景了,属于进程上下文那个分类了)、timer的callback函数(本质上也是softirq)、tasklet(本质上也是softirq)。
先看最简单的单CPU上的进程上下文的访问。如果一个全局的资源被多个进程上下文访问,这时候,内核如何交错执行呢?对于那些没有打开preemptive选项的内核,所有的系统调用都是串行化执行的,因此不存在资源争抢的问题。如果内核线程也访问这个全局资源呢?本质上内核线程也是进程,类似普通进程,只不过普通进程时而在用户态运行、时而通过系统调用陷入内核执行,而内核线程永远都是在内核态运行,但是,结果是一样的,对于non-preemptive的linux kernel,只要在内核态,就不会发生进程调度,因此,这种场景下,共享数据根本不需要保护(没有并发,谈何保护呢)。如果时间停留在这里该多么好,单纯而美好,在继续前进之前,让我们先享受这一刻。
当打开premptive选项后,事情变得复杂了,我们考虑下面的场景:
(1)进程A在某个系统调用过程中访问了共享资源R
(2)进程B在某个系统调用过程中也访问了共享资源R
会不会造成冲突呢?假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态。
多CPU core的场景和单核CPU打开preemptive选项的效果是一样的,这里不再赘述。
我们继续向前分析,现在要加入中断上下文这个因素。访问共享资源的thread包括:
(1)运行在CPU0上的进程A在某个系统调用过程中访问了共享资源R
(2)运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源R
(3)外设P的中断handler中也会访问共享资源R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本CPU上的中断联合使用。
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就OK了。
最后,我们讨论一下中断上下文之间的竞争。同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的sofirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。tasklet更简单,因为同一种tasklet不会多个CPU上并发,具体我就不分析了,大家自行思考吧。
1. 自旋锁基本逻辑
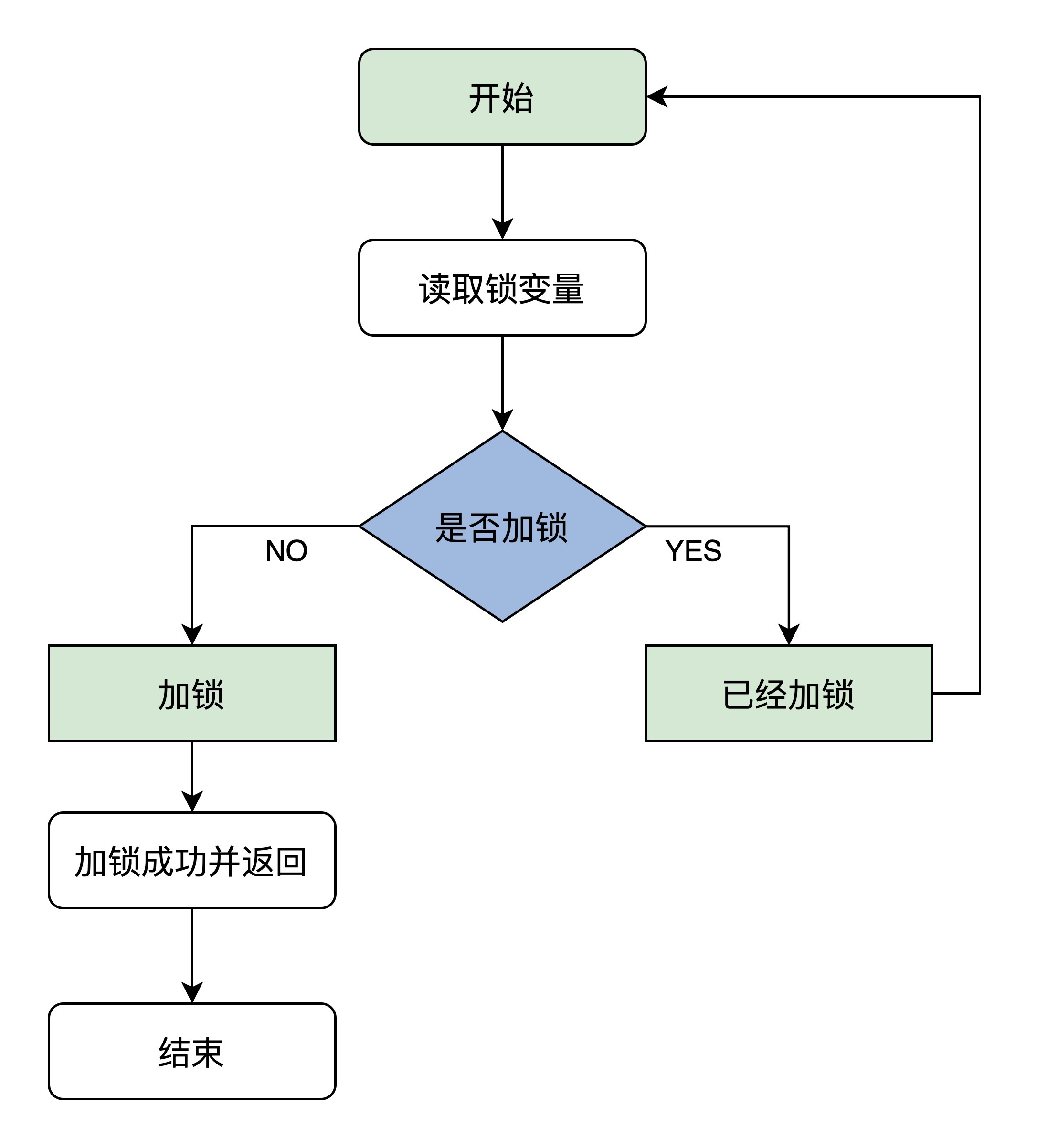
们先看看自旋锁的原理,它是这样的:首先读取锁变量,判断其值是否已经加锁,如果未加锁则执行加锁,然后返回,表示加锁成功;如果已经加锁了,就要返回第一步继续执行后续步骤,因而得名自旋锁。这个算法看似很好,但是想要正确的执行,就必须保证读取锁变量和判断并加锁的操作是原子操作,具体实现以来各自平台,对于ARM平台实现见文章https://blog.csdn.net/u012294613/article/details/123179303。
2. API
1、文件整理
和体系结构无关的代码如下:
(1)include/linux/spinlock_types.h。这个头文件定义了通用spin lock的基本的数据结构(例如spinlock_t)和如何初始化的接口(DEFINE_SPINLOCK)。这里的“通用”是指不论SMP还是UP都通用的那些定义。
(2)include/linux/spinlock_types_up.h。这个头文件不应该直接include,在include/linux/spinlock_types.h文件会根据系统的配置(是否SMP)include相关的头文件,如果UP则会include该头文件。这个头文定义UP系统中和spin lock的基本的数据结构和如何初始化的接口。当然,对于non-debug版本而言,大部分struct都是empty的。
(3)include/linux/spinlock.h。这个头文件定义了通用spin lock的接口函数声明,例如spin_lock、spin_unlock等,使用spin lock模块接口API的驱动模块或者其他内核模块都需要include这个头文件。
(4)include/linux/spinlock_up.h。这个头文件不应该直接include,在include/linux/spinlock.h文件会根据系统的配置(是否SMP)include相关的头文件。这个头文件是debug版本的spin lock需要的。
(5)include/linux/spinlock_api_up.h。同上,只不过这个头文件是non-debug版本的spin lock需要的
(6)linux/spinlock_api_smp.h。SMP上的spin lock模块的接口声明
(7)kernel/locking/spinlock.c。SMP上的spin lock实现。
头文件有些凌乱,我们对UP和SMP上spin lock头文件进行整理:
| UP需要的头文件 | SMP需要的头文件 |
| linux/spinlock_type_up.h: | asm/spinlock_types.h |
2、数据结构
根据第二章的分析,我们可以基本可以推断出spin lock的实现。首先定义一个spinlock_t的数据类型,其本质上是一个整数值(对该数值的操作需要保证原子性),该数值表示spin lock是否可用。初始化的时候被设定为1。当thread想要持有锁的时候调用spin_lock函数,该函数将spin lock那个整数值减去1,然后进行判断,如果等于0,表示可以获取spin lock,如果是负数,则说明其他thread的持有该锁,本thread需要spin。
内核中的spinlock_t的数据类型定义如下:
typedef struct spinlock {
struct raw_spinlock rlock;
} spinlock_t;typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
} raw_spinlock_t;
由于各种原因(各种锁的debug、锁的validate机制,多平台支持什么的),spinlock_t的定义没有那么直观,为了让事情简单一些,我们去掉那些繁琐的成员。struct spinlock中定义了一个struct raw_spinlock的成员,为何会如此呢?好吧,我们又需要回到kernel历史课本中去了。在旧的内核中(比如我熟悉的linux 2.6.23内核),spin lock的命令规则是这样:
通用(适用于各种arch)的spin lock使用spinlock_t这样的type name,各种arch定义自己的struct raw_spinlock。听起来不错的主意和命名方式,直到linux realtime tree(PREEMPT_RT)提出对spinlock的挑战。real time linux是一个试图将linux kernel增加硬实时性能的一个分支(你知道的,linux kernel mainline只是支持soft realtime),多年来,很多来自realtime branch的特性被merge到了mainline上,例如:高精度timer、中断线程化等等。realtime tree希望可以对现存的spinlock进行分类:一种是在realtime kernel中可以睡眠的spinlock,另外一种就是在任何情况下都不可以睡眠的spinlock。分类很清楚但是如何起名字?起名字绝对是个技术活,起得好了事半功倍,可维护性好,什么文档啊、注释啊都素那浮云,阅读代码就是享受,如沐春风。起得不好,注定被后人唾弃,或者拖出来吊打(这让我想起给我儿子起名字的那段不堪回首的岁月……)。最终,spin lock的命名规范定义如下:
(1)spinlock,在rt linux(配置了PREEMPT_RT)的时候可能会被抢占(实际底层可能是使用支持PI(优先级翻转)的mutext)。
(2)raw_spinlock,即便是配置了PREEMPT_RT也要顽强的spin
(3)arch_spinlock,spin lock是和architecture相关的,arch_spinlock是architecture相关的实现
对于UP平台,所有的arch_spinlock_t都是一样的,定义如下:
typedef struct { } arch_spinlock_t;
什么都没有,一切都是空啊。当然,这也符合前面的分析,对于UP,即便是打开的preempt选项,所谓的spin lock也不过就是disable preempt而已,不需定义什么spin lock的变量。
对于SMP平台,这和arch相关,我们在下一节描述。
3、spin lock接口API
我们整理spin lock相关的接口API如下:
| 接口API的类型 | spinlock中的定义 | raw_spinlock的定义 |
| 定义spin lock并初始化 | DEFINE_SPINLOCK | DEFINE_RAW_SPINLOCK |
| 动态初始化spin lock | spin_lock_init | raw_spin_lock_init |
| 获取指定的spin lock | spin_lock | raw_spin_lock |
| 获取指定的spin lock同时disable本CPU中断 | spin_lock_irq | raw_spin_lock_irq |
| 保存本CPU当前的irq状态,disable本CPU中断并获取指定的spin lock | spin_lock_irqsave | raw_spin_lock_irqsave |
| 获取指定的spin lock同时disable本CPU的bottom half | spin_lock_bh | raw_spin_lock_bh |
| 释放指定的spin lock | spin_unlock | raw_spin_unlock |
| 释放指定的spin lock同时enable本CPU中断 | spin_unlock_irq | raw_spin_unock_irq |
| 释放指定的spin lock同时恢复本CPU的中断状态 | spin_unlock_irqstore | raw_spin_unlock_irqstore |
| 获取指定的spin lock同时enable本CPU的bottom half | spin_unlock_bh | raw_spin_unlock_bh |
| 尝试去获取spin lock,如果失败,不会spin,而是返回非零值 | spin_trylock | raw_spin_trylock |
| 判断spin lock是否是locked,如果其他的thread已经获取了该lock,那么返回非零值,否则返回0 | spin_is_locked | raw_spin_is_locked |
在具体的实现面,我们不可能把每一个接口函数的代码都呈现出来,我们选择最基础的spin_lock为例子,其他的读者可以自己阅读代码来理解。
spin_lock的代码如下:
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
当然,在linux mainline代码中,spin_lock和raw_spin_lock是一样的,在realtime linux patch中,spin_lock应该被换成可以sleep的版本,当然具体如何实现我没有去看(也许直接使用了Mutex,毕竟它提供了优先级继承特性来解决了优先级翻转的问题),有兴趣的读者可以自行阅读,我们这里重点看看(本文也主要focus这个主题)真正的,不睡眠的spin lock,也就是是raw_spin_lock,代码如下:
#define raw_spin_lock(lock) _raw_spin_lock(lock)
UP中的实现:
#define _raw_spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)SMP的实现:
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
UP中很简单,本质上就是一个preempt_disable而已,和我们在第二章中分析的一致。SMP中稍显复杂,preempt_disable当然也是必须的,spin_acquire可以略过,这是和运行时检查锁的有效性有关的,如果没有定义CONFIG_LOCKDEP其实就是空函数。如果没有定义CONFIG_LOCK_STAT(和锁的统计信息相关),LOCK_CONTENDED就是调用do_raw_spin_lock而已,如果没有定义CONFIG_DEBUG_SPINLOCK,它的代码如下:
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}
__acquire和静态代码检查相关,忽略之,最终实际的获取spin lock还是要靠arch相关的代码实现。
2.1. 基本结构
可以看到,数据类型spinlock对raw_spinlock做了封装,然后数据类型raw_spinlock对arch_spinlock_t做了封装,各种处理器架构需要自定义数据类型arch_spinlock_t。
spinlock和raw_spinlock(原始自旋锁)有什么关系?
Linux内核有一个实时内核分支(开启配置宏CONFIG_PREEMPT_RT)来支持硬实时特性,内核主线只支持软实时。对于没有打上实时内核补丁的内核,spinlock只是封装raw_spinlock,它们完全一样。如果打上实时内核补丁,那么spinlock使用实时互斥锁保护临界区,在临界区内可以被抢占和睡眠,但raw_spinlock还是自旋锁。
目前主线版本还没有合并实时内核补丁,说不定哪天就会合并进来,为了使代码可以兼容实时内核,最好坚持3个原则:
(1)尽可能使用spinlock。
(2)绝对不允许被抢占和睡眠的地方,使用raw_spinlock,否则使用spinlock。
(3)如果临界区足够小,使用raw_spinlock。
typedef struct {
raw_spinlock_t raw_lock;
#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;
include/asm-arm/spinlock_types.h
typedef struct {
volatile unsigned int lock;
} raw_spinlock_t;2.2. API
中断的几个API:
local_irq_save或local_irq_disable,关闭本CPU的中断。local_irq_save在关中断的同时会保存当前开关中断的状态,可以在restore的时候恢复。local_irq_disable/save是直接去改cprs寄存器,让CPU不响应中断。spin_lock_irqsave,是spinlock加local_irq_save的合体。
irq_disable(iqr_desc),屏蔽某号中断,它该的是描述符,让这个中断不发给CPU了。
我们说spin_lock核内锁调度,核间自旋。而local_irq_save是锁住了本核的中断,但在核间是没有任何作用的(Linux没有任何API能关其他核的中断或调度器)。由于我们平时写的驱动都是跨核的,不要假设自己代码肯定是单核上运行,local_irq_save起不到锁住多核的作用,如果另一个核要访问你这个核上线程的资源就产生竞态了,因此写代码的时候不要用local_irq_save,你自己写的代码基本不会存在只需要使用local_irq_save的情况,建议都改用spin_lock_irqsave来锁中断。当然local_irq_disable就更不要用了。
因此,spin_lock和spin_lock_irqsave是常用的。
注意kmalloc可能睡眠,如果在spinlock申请内存,可以加GFP_ATOMIC的flag,也可以直接用alloc_page系列函数。
还有其他的变种例如local_bh_disable()是锁下半部(锁抢占)的,相应的spin_lock_bh()是多核中锁下半部的。
| 函数或者宏 | 说明 |
| DEFINE_SPINLOCK(x) | 定义并且初始化静态自旋锁 |
| spin_lock_init(x) | 初始化自旋锁 |
| void spin_lock(spinlock_t *lock) | 获取自旋锁不成功,原地自旋等待,直到锁被释放,获取成功才返回 |
| void spin_unlock(spinlock_t *lock) | 释放自旋锁 |
| spin_trylock(&btn_lock) | 不成功,直接返回一个错误信息,调试的时候可用,可以避免死锁 |
| void spin_lock_irq(spinlock_t *lock) | 申请自旋锁,并且禁止当前处理器的软中断。+local_irq_disable() |
| spin_lock_irqsave(lock, flags) | 申请自旋锁,并且禁止当前处理器的硬中断。+local_irq_save() |
2.2. 实例btn_drv.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/device.h>
#include <linux/cdev.h>
MODULE_LICENSE("GPL");
dev_t dev;
struct cdev btn_cdev;
struct class *cls = NULL;
int count = 1; //共享资源
spinlock_t btn_lock; //[1]. 定义一个自旋锁变量
int btn_open(struct inode *inode, struct file *filp)
{
spin_lock(&btn_lock); /*[3].获取自旋锁*/
count--; /*[4] 访问共享资源*/
if(count !=0 )
{
count++;
spin_unlock(&btn_lock); /*[5]. 释放自旋锁*/
return -EBUSY;
}
spin_unlock(&btn_lock); /*[5].释放自旋锁*/
return 0;
}
int btn_close(struct inode *inode, struct file *filp)
{
spin_lock(&btn_lock);
count++;
spin_unlock(&btn_lock);
return 0;
}
struct file_operations btn_fops =
{
.owner = THIS_MODULE,
.open = btn_open,
.release = btn_close,
};
int __init btn_drv_init(void)
{
alloc_chrdev_region(&dev, 100, 1, "mybuttons"); /*设备号的动态申请注册*/
cdev_init(&btn_cdev, &btn_fops); /*初始化cdev*/
cdev_add(&btn_cdev, dev, 1); /*注册cdev*/
cls = class_create(THIS_MODULE, "buttons"); /*设备文件的自动创建*/
device_create(cls, NULL, dev, NULL,"mybuttons");
spin_lock_init(&btn_lock); /*2.初始化自旋锁*/
return 0;
}
void __exit btn_drv_exit(void)
{
/*销毁设备文件*/
device_destroy(cls, dev);
class_destroy(cls);
/*注销cdev*/
cdev_del(&btn_cdev);
/*注销设备号*/
unregister_chrdev_region(dev, 1);
}
module_init(btn_drv_init);
module_exit(btn_drv_exit);Makefile
obj-m += btn_drv.o
all:
make -C /home/chuckchee/driver/kernel M=$(PWD) modules
cp *.ko ../../rootfs
arm-cortex_a9-linux-gnueabi-gcc test.c -o test
cp test ../../rootfs
clean:
make -C /home/chuckchee/driver/kernel M=$(PWD) cleantest.c应用测试代码
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
int fd = open("/dev/mybuttons", O_RDWR);
if(fd < 0)
{
perror("open failed:");
return -1;
}
printf("open successed: using device 20s...\n");
sleep(20);
printf("close device\n");
close(fd);
return 0;
}3. 演进
自旋锁的实现经历了3个阶段:
(1) 最早的自旋锁是无序竞争的,不保证先申请的进程先获得锁。
(2) 第2个阶段是入场券自旋锁,进程按照申请锁的顺序排队,先申请的进程先获得锁。
(3) 第3个阶段是MCS自旋锁。入场券自旋锁存在性能问题:所有申请锁的处理器在同一个变量上自旋等待,缓存同步的开销大,不适合处理器很多的系统。MCS自旋锁的策略是为每个处理器创建一个变量副本,每个处理器在自己的本地变量上自旋等待,解决了性能问题。
入场券自旋锁和MCS自旋锁都属于排队自旋锁(queued spinlock),进程按照申请锁的顺序排队,先申请的进程先获得锁。
在早期,2.6.24之前的内核,抢spinlock完全靠斗狠。比如有8个CPU核,CPU0已经持有了spin_lock(),在其释放之前,CPU1-CPU7都来抢(前后顺序可能不一样):

那么在CPU0释放spinlock的瞬间,CPU1-CPU7究竟哪个先抢到?不知道,谁狠谁抢到。比如某个核的计算能力强,某个核正好cache命中spinlock对应的变量,它就抢地快。
因为,早期的spinlock大概是这个一个逻辑:
在没有持有锁的情况下:
int count=1
持有锁的过程中:
count=count-1;
if(count==0)
成功拿到了锁;
if(count < 0)
证明别人拿到了锁,自己还得继续等。
释放锁的过程:
count = 1;
因此,谁先感觉到count-1==0,谁就成功拿到锁。比如8个人去银行汇款,柜台服务完前一个人后,喊了一句“next one”,那么谁会抢到柜台服务呢?
-
刘翔、姚明、长腿欧巴、走路特别快的(CPU猛)
-
思想没有在打野,全神灌注盯着柜台的(cache命中)
至于,老弱病残幼,那就完全没戏了;柜台叫“next one”的时候,正在发微信的、玩手机的、吟诗作对的、聊骚的,也完全没戏了!!
这显然太特么不公平了!!像我这么喜欢玩手机的人,按照这种排队方法,在银行哪怕第一个去,恐怕一天也排不到我!!!这叫被饥饿(starved )。
叫号
我要玩手机
银行的柜台服务没有那么傻逼。任何一个人去到银行,先取一个号,银行每服务完一个人,就报一个新的号,如果机器报的号等于自己持有的票号,则取得柜台服务。这特么太公平了!!我取完号,我就发微信了,你腿再长也没鸟用,你来的晚,你的号大,柜台叫的号小于你的号,你就得继续等。
spinlock显然需要这个一模一样的机制。这就叫Ticket spinlocks。2.6.25之后的spinlock是这样实现的:

owner类似于柜台语音报的号,next是取票的号。它的逻辑大概类似于,谁取票先把spinlock的next暂存到本地local_next,然后把spinlock的next+1,所以后来的人取到的票号肯定更大;谁释放锁就把owner加1。如果spinlock释放后,owner正好等于某个CPU本地暂存的local_next,则这个CPU获得spinlock。
spinlock本身将含有owner和next:
typedef struct {
union {
unsigned int slock;
struct __raw_tickets {
unsigned short owner;
unsigned short next;
} tickets;
};
} arch_spinlock_t;
获取spinlock的过程变成
取号+等待叫号等于自己取的号:

当然,真实的取号过程要通过ldrex、strex这样的指令来实现原子性:
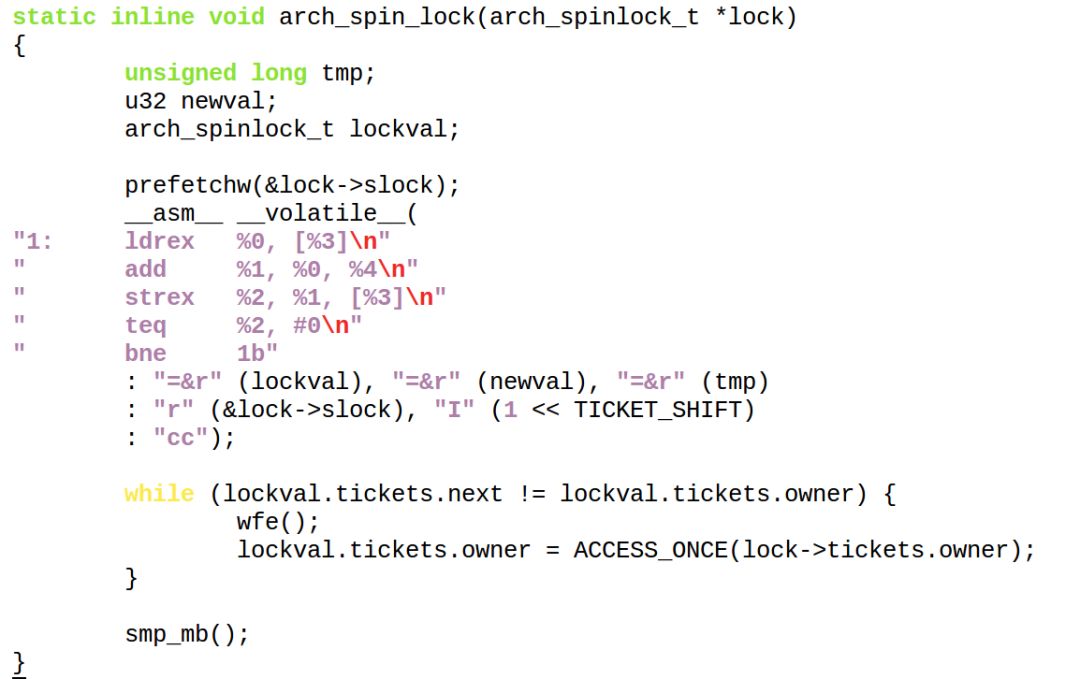
上述代码中,wfe()类似你在发呆、玩微信,这个时候,叫号机通过sev()来唤醒你。
MCS锁
MCS锁可以解决上面的CLH锁的缺点,MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott。
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋(与CLH自旋锁不同的地方,不在轮询前驱的状态,而是由前驱主动通知),从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。
原理

MCS
- 每个线程持有一个自己的node,node有一个locked属性,true表示等待获取锁,false表示可以获取到锁,并且持有下一个node(后继者)的引用(可能存在)
- 线程在轮询自己node的locked状态,true表示锁被其他线程暂用,等待获取锁,自旋。
- 线程释放锁的时候,修改后继者(nextNode)的locked属性,通知后继者结束自旋。
各个spin_lock之间的差异和关系
本文不打算详细探究spin_lock的详细实现机制,只是最近对raw_spin_lock的出现比较困扰,搞不清楚什么时候用spin_lock,什么时候用raw_spin_lock,因此有了这篇文章。
/*****************************************************************************************************/
声明:本博内容均由http://blog.csdn.net/droidphone原创,转载请注明出处,谢谢!
/*****************************************************************************************************/
1. 临界区(Critical Section)
我们知道,临界区是指某个代码区间,在该区间中需要访问某些共享的数据对象,又或者是总线,硬件寄存器等,通常这段代码区间的范围要控制在尽可能小的范围内。临界区内需要对这些数据对象和硬件对象的访问进行保护,保证在退出临界区前不会被临界区外的代码对这些对象进行修改。出现以下几种情形时,我们需要使用临界区进行保护:
(1) 在可以抢占(preemption)的系统中,两个线程同时访问同一个对象;
(2) 线程和中断同时访问同一个对象;
(3) 在多核系统中(SMP),可能两个CPU可能同时访问同一个对象;
2. 自旋锁(spin_lock)
针对单处理器系统,对第一种情况,只要临时关闭系统抢占即可,我们可以使用以下方法:
preempt_disable();
.....
// 访问共享对象的代码
......
preempt_enable();
同样地,针对单处理器系统,第二种情况,只要临时关闭中断即可,我们可以使用以下方法:
local_irq_disable();
......
// 访问共享对象的代码
......
local_irq_enable();
那么,针对多处理器的系统,以上的方法还成立么?答案很显然:不成立。
对于第一种情况,虽然抢占被禁止了,可是另一个CPU上还有线程在运行,如果这个线程也正好要访问该共享对象,上面的代码段显然是无能为力了。
对于第二种情况,虽然本地CPU的中断被禁止了,可是另一个CPU依然可以产生中断,如果他的中断服务程序也正好要访问该共享对象,上面的代码段也一样无法对共享对象进行保护。
实际上,在linux中,上面所说的三种情况都可以用自旋锁(spin_lock)解决。基本的自旋锁函数对是:
spin_lock(spinlock_t *lock);
spin_unlock(spinlock_t *lock);
对于单处理器系统,在不打开调试选项时,spinlock_t实际上是一个空结构,把上面两个函数展开后,实际上就只是调用preempt_disable()和preempt_enable(),对于单处理器系统,关掉抢占后,其它线程不能被调度运行,所以并不需要做额外的工作,除非中断的到来,不过内核提供了另外的变种函数来处理中断的问题。
对于多处理器系统,spinlock_t实际上等效于内存单元中的一个整数,内核保证spin_lock系列函数对该整数进行原子操作,除了调用preempt_disable()和preempt_enable()防止线程被抢占外,还必须对spinlock_t上锁,这样,如果另一个CPU的代码要使用该临界区对象,就必须进行自旋等待。
对于中断和普通线程都要访问的对象,内核提供了另外两套变种函数:
spin_lock_irq(spinlock_t *lock);
spin_unlock_irq(spinlock_t *lock);
和:
spin_lock_irqsave(lock, flags);
spin_lock_irqrestore(lock, flags);
我们可以按以下原则使用上面的三对变种函数(宏):
如果只是在普通线程之间同时访问共享对象,使用spin_lock()/spin_unlock();
如果是在中断和普通线程之间同时访问共享对象,并且确信退出临界区后要打开中断,使用spin_lock_irq()/spin_unlock_irq();
如果是在中断和普通线程之间同时访问共享对象,并且退出临界区后要保持中断的状态,使用spin_lock_irqsave()/spin_unlock_irqrestore();
其实变种还不止这几个,还有read_lock_xxx/write_lock_xxx、spin_lock_bh/spin_unlock_bh、spin_trylock_xxx等等。但常用的就上面几种。
3. raw_spin_lock
在2.6.33之后的版本,内核加入了raw_spin_lock系列,使用方法和spin_lock系列一模一样,只是参数有spinlock_t变为了raw_spinlock_t。而且在内核的主线版本中,spin_lock系列只是简单地调用了raw_spin_lock系列的函数,但内核的代码却是有的地方使用spin_lock,有的地方使用raw_spin_lock。是不是很奇怪?要解答这个问题,我们要回到2004年,MontaVista Software, Inc的开发人员在邮件列表中提出来一个Real-Time Linux Kernel的模型,旨在提升Linux的实时性,之后Ingo Molnar很快在他的一个项目中实现了这个模型,并最终产生了一个Real-Time preemption的patch。
该模型允许在临界区中被抢占,而且申请临界区的操作可以导致进程休眠等待,这将导致自旋锁的机制被修改,由原来的整数原子操作变更为信号量操作。当时内核中已经有大约10000处使用了自旋锁的代码,直接修改spin_lock将会导致这个patch过于庞大,于是,他们决定只修改哪些真正不允许抢占和休眠的地方,而这些地方只有100多处,这些地方改为使用raw_spin_lock,但是,因为原来的内核中已经有raw_spin_lock这一名字空间,用于代表体系相关的原子操作的实现,于是linus本人建议:
把原来的raw_spin_lock改为arch_spin_lock;
把原来的spin_lock改为raw_spin_lock;
实现一个新的spin_lock;
写到这里不知大家明白了没?对于2.6.33和之后的版本,我的理解是:
尽可能使用spin_lock;
绝对不允许被抢占和休眠的地方,使用raw_spin_lock,否则使用spin_lock;
如果你的临界区足够小,使用raw_spin_lock;
对于没有打上Linux-RT(实时Linux)的patch的系统,spin_lock只是简单地调用raw_spin_lock,实际上他们是完全一样的,如果打上这个patch之后,spin_lock会使用信号量完成临界区的保护工作,带来的好处是同一个CPU可以有多个临界区同时工作,而原有的体系因为禁止抢占的原因,一旦进入临界区,其他临界区就无法运行,新的体系在允许使用同一个临界区的其他进程进行休眠等待,而不是强占着CPU进行自旋操作。写这篇文章的时候,内核的版本已经是3.3了,主线版本还没有合并Linux-RT的内容,说不定哪天就会合并进来,也为了你的代码可以兼容Linux-RT,最好坚持上面三个原则。
————————————————
版权声明:本文为CSDN博主「DroidPhone」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/droidphone/article/details/7395983
其他进一步参考链接:
自旋锁 spin_lock、 spin_lock_irq 以及 spin_lock_irqsave 的区别_时间片 线程切换 spinlock-CSDN博客
spin_lock_irqsave_spinlock irqsave-CSDN博客
[内核同步]自旋锁spin_lock、spin_lock_irq 和 spin_lock_irqsave 分析-CSDN博客














 79
79











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









