







在前面的两篇文章中,我们分别讲了卷积神经网络的卷积层、池化层、Affine层、Softmax层等基础知识。
我们知道,信号在神经网络中的传播方向分为正向传播与反向传播:
(1) 正向传播:输入信号按顺序通过神经网络的每一层,一直从输入端达到最后的输出端,然后作为最终输出信息输出。
(2) 反向传播:训练数据时,由于神经网络的参数是根据输出信号与标签的误差信息来调节的,因此需要将其误差信息从神经网络的输出端传递到输入端,也即按反方向传播。
本文我们主要从数学公式的角度来讲解以下5层卷积神经网络的正向传播过程。
![]()
1. 卷积层C1
C1作为5层网络的第一层,也是输入层。它的相关信息列出如下:
输入:1张28*28的手写数字图像。
卷积神经元个数:6个卷积神经元。
卷积核尺寸:每个卷积神经元对应1个5*5卷积核。
偏置:每个卷积神经元对应1个偏置值。·
卷积模式:Valid卷积模式。
激活函数:Relu函数。
输出尺寸:每个卷积神经元输出(28-5+1)*(28-5+1)=24*24的卷积结果,总共6个卷积神经元,因为总共输出6张24*24的卷积结果图像。
假设输入图像为I,卷积核为k,偏置为b,激活函数为f(x),那么C1层的每个卷积神经元的输出Y按照下式计算,其中"*"号为图像的卷积操作,且0≤i<6。
![]()
这里可能有人会有疑问,既然卷积的结果为一个二维矩阵,它是怎么加上作为一个数的偏置,以及怎么输入激活函数的?其实前面的文章我们就讲过:
(1) 两个卷积结果的相加操作,也即矩阵中对应位置值的相加。
(2) 加上偏置的操作,也即矩阵中每个值都加上相同的偏执值。
(3) 通过激活函数的操作,也即矩阵中每个值都输入激活函数,然后所有的激活函数输出值组成相同维度的矩阵,该矩阵就是卷积神经元的输出。
2. 池化层S2
池化原理我们在上篇文章(文章开头的超链接)已经讲过,在本层我们选择最大值池化的方法对C1层的输出进行池化。本层信息列出如下:
输入:6张24*24的卷积结果图。
池化窗口尺寸:2*2。
池化模式:最大值池化。
输出尺寸:每张卷积结果图经过池化之后,变成(24/2)*(24/2)=12*12的图像,因此该层输入的6张24*24的图像变成6张12*12的图像。
用数学式子表示池化过程如下:
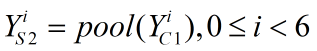
3. 卷积层C3
该层的相关信息列出如下:
输入:6张12*12的池化结果图。
卷积神经元个数:12个卷积神经元,每个卷积神经元都输入6张12*12的池化结果图。
卷积核尺寸:每个卷积神经元对应6个5*5卷积核。
偏置:每个卷积神经元对应一个偏置值。·
卷积模式:Valid卷积模式。
激活函数:Relu函数。
输出尺寸:每个卷积神经元输出(12-5+1)*(12-5+1)=8*8的卷积结果,总共12个卷积神经元,因此总共输出12张8*8的卷积结果图像。
那么C3层的每个卷积神经元的输出Y按照下式计算。·
![]()
4. 池化层S4
本层信息列出如下:
输入:12张8*8的卷积结果图。
池化窗口尺寸:2*2。
池化模式:最大值池化。
输出尺寸:每张卷积结果图经过池化之后,变成(8/2)*(8/2)=4*4的图像,因此该层输入的12张8*8的图像变成12张4*4的图像。
用数学式子表示池化过程如下:
![]()
5. 输出层O5
本层是全连接层,也是5层网络的最后一层,其信息列出如下:
输入:输入12张4*4的池化结果图,输入之后将12*4*4=192的数据按顺序展开成长度为192的一维向量X:
![]()
神经元个数:10个神经元,每个神经元都输入向量X的192个数据。
权重个数:每个神经元对应192个权重,总共10个神经元,因此该层总共有10*192个权重。
偏置:每个卷积神经元对应一个偏置值,因此总共有10个偏置值。·
激活函数:Softmax函数。
输出尺寸:每个神经元输出一个0~1之间的概率值,因此总共输出10个概率值。
本层的输出Y可按下式计算:
好了,本文我们就讲到这里,下篇文章中让我们继续探讨一下反向传播吧,敬请期待!















 3486
3486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









